")
AÇIK VERİ
YAPILARI
(JAVA İLE)
Pat Morin
Türkçeye Çeviren: Ayşegül Tunç
2|
AÇIK VERİ YAPILARI (JAVA İLE)
Pat Morin
Türkçeye Çeviren: Ayşegül Tunç
Yazarı (Author): Pat MORIN (Canadian Scientist)
Türkçeye Çeviren: Ayşegül Tunç
Sayfa Düzenleme & Grafik Tasarım: e-KiTAP PROJES
Kapak Tasarımı: © E-Kitap Projesi,
Editorial: Banu Fi ek & Fulya Saatçıo lu
Yayıncı (Publisher): http://www.ekitaprojesi.com, Murat Ukray
Baskı ve Cilt (Print Publisher): www.lulu.com
Yayıncı Sertifika Numarası (Publisher Certificate Number): 32712
Istanbul, Ocak (January) 2016
ISBN: 978-1-329-86063-6
Yazar & Kitap leti im (Author Contact):
(e-mail & web):
agultunc@hotmail.com
www.ekitaprojesi.com/books/acik-veri-yapilari-java-ile
www.facebook.com/EKitapProjesi
Bu Kitabın çeviri hakları, yazarın yazılı izni ile e-Kitap Projesi ile
Çevirmen Ayşegül Tunç’a aittir. İzin alınmadan kısmen veya tamamen
kopyalanması yasaktır..
©
Bu eserin basım ve yayın
hakları yazarın kendisine aittir.
Fikir ve Sanat Eserleri Yasası
gereğince, izinsiz kısmen veya
tamamen çoğaltılıp yayınlanamaz. Kaynak gösterilerek kısa
alıntı yapılabilir.
|3
KİTAP HAKKINDA...................................................................................................... 9
YAZAR HAKKINDA ................................................................................................... 11
ÇEVİRMEN HAKKINDA ............................................................................................ 13
BÖLÜM 1 ................................................................................................................... 15
Giriş ........................................................................................................................... 15
Verimlilik Gereksinimi ................................................................................... 17
Arayüzler............................................................................................................ 21
Kuyruk, Yığıt ve İki Başlı Kuyruk Arayüzleri .................................... 22
Liste Arayüzü: Doğrusal Diziler .................................................................. 25
UKüme Arayüzü: Sıralı Olmayan Kümeler ...................................... 27
SKüme Arayüzü: Sıralı Kümeler ......................................................... 29
Matematiksel Zemin ...................................................................................... 31
Üslüler ve Logaritmalar ........................................................................... 31
Faktöryeller.................................................................................................. 34
Asimptotik Gösterim ................................................................................. 36
Rasgele Sıralama ve Olasılık ................................................................. 43
Hesaplama Modeli .............................................................................................. 47
Doğruluk, Zaman Karmaşıklığı ve Alan Karmaşıklığı......................... 49
Kod Örnekleri ................................................................................................... 53
Veri Yapıları Listesi ......................................................................................... 54
Tartışma ve Alıştırmalar ............................................................................... 56
BÖLÜM 2 ................................................................................................................... 61
Dizi-Tabanlı Listeler............................................................................................. 61
Dizi Yığıtı: Dizi Kullanan Hızlı Yığıt İşlemleri ......................................... 63
Temel Bilgiler .............................................................................................. 64
Büyültme ve Küçültme ............................................................................ 67
Özet ................................................................................................................ 71
Hızlı Dizi Yığıtı: Optimize Dizi Yığıtı .......................................................... 72
Dizi Kuyruğu: Dizi-Tabanlı Kuyruk ........................................................... 74
4|
Özet ................................................................................................................ 79
Dizi İki Başlı Kuyruk: Dizi Kullanan Hızlı İki Başlı Kuyruk ............... 80
Özet ................................................................................................................ 83
Çifte Dizi İki Başlı Kuyruk: İki Yığıt’tan
İki Başlı Kuyruk Oluşturulması................................................................... 84
Dengeleme ................................................................................................... 89
Özet ................................................................................................................ 92
Kök Dizi Yığıt: Alan Kriteri Verimli Olan Dizi Yığıt Uygulaması ...... 93
Büyültme ve Küçültmenin Analizi ...................................................... 100
Alan Kullanımı ........................................................................................... 101
Özet .............................................................................................................. 103
Karekökleri Hesaplamak ....................................................................... 104
Tartışma ve Alıştırmalar ............................................................................. 109
BÖLÜM 3 ................................................................................................................. 113
Bağlantılı Listeler ................................................................................................ 113
TBListe: Tekli-Bağlantılı Liste ................................................................... 114
Kuyruk İşlemleri ....................................................................................... 117
Özet .............................................................................................................. 118
ÇBListe: Çifte-Bağlantılı Liste ................................................................... 119
Ekleme ve Çıkarma ................................................................................. 122
Özet .............................................................................................................. 124
AVListe: Alan-Verimli Liste ........................................................................ 126
Alan Gereksinimleri ................................................................................. 128
Elemanların Bulunması .......................................................................... 128
Elemanların Eklenmesi........................................................................... 131
Elemanların Silinmesi ............................................................................. 134
yayıl(u) ve birarayaGetir(u) Yöntemlerinin
Amortize Edilmiş Analizi ........................................................................ 137
Özet .............................................................................................................. 140
Tartışma ve Alıştırmalar ............................................................................. 142
BÖLÜM 4 ................................................................................................................. 113
Sekme Listeleri ................................................................................................... 150
Temel Yapı ....................................................................................................... 151
Sıralı Küme Sekme Listesi: Verimli bir Sıralı Küme ......................... 155
Özet .............................................................................................................. 159
|5
Liste Sekme Listesi: Verimli Rasgele Erişim Listesi ......................... 160
Özet .............................................................................................................. 167
Sekme Listelerinin Analizi .......................................................................... 168
Tartışma ve Alıştırmalar ............................................................................. 174
BÖLÜM 5 ................................................................................................................. 181
Karma Tabloları .................................................................................................. 181
Zincirleme Karma Tablo: Zincirleme İle Adresleme ........................ 182
Çarpımsal Karma Yöntemi.................................................................... 186
Özet .............................................................................................................. 193
Doğrusal Karma Tablo: Doğrusal Yerleştirme .................................... 194
Doğrusal Yerleştirme Analizi ............................................................... 199
Özet .............................................................................................................. 204
Listeleme Karma Yöntemi .................................................................... 205
Karma Kodları ................................................................................................ 207
Temel Veri Türleri için Karma Kodları .............................................. 208
Bileşik Nesneler için Karma Kodları .................................................. 209
Diziler ve Dizeler için Karma Kodları ................................................ 213
Tartışma ve Alıştırmalar ............................................................................. 217
BÖLÜM 6 ................................................................................................................. 224
İkili Ağaçlar .......................................................................................................... 224
İkili Ağaç: Temel İkili Ağaç ....................................................................... 227
Özyinelemeli Algoritmalar .................................................................... 228
İkili Ağaçta Sıralı-Düğüm Ziyaretleri ................................................ 229
Serbest Yükseklikli İkili Arama Ağacı .................................................... 234
Arama .......................................................................................................... 235
Ekleme ......................................................................................................... 238
Silme ............................................................................................................ 240
Özet .............................................................................................................. 243
Tartışma ve Alıştırmalar ............................................................................. 245
BÖLÜM 7 ................................................................................................................. 253
Rasgele İkili Arama Ağaçları .......................................................................... 253
Rasgele İkili Arama Ağaçları ..................................................................... 253
Önerme 7.1’in Kanıtı .............................................................................. 258
Özet .............................................................................................................. 262
6|
Treap: Rasgele İkili Arama Ağaçları....................................................... 263
Özet .............................................................................................................. 272
Tartışma ve Alıştırmalar ............................................................................. 276
BÖLÜM 8 ................................................................................................................. 284
Günah Keçisi Ağaçları ....................................................................................... 284
Günah Keçisi Ağacı: Kısmi Yeniden
Oluşturmalı İkili Arama Ağacı ................................................................... 286
Doğruluk Analizi ve Çalışma Zamanı ................................................ 291
Özet .............................................................................................................. 296
Tartışma ve Alıştırmalar ............................................................................. 297
BÖLÜM 9 ................................................................................................................. 304
Kırmızı-Siyah Ağaçlar ....................................................................................... 304
2-4 Ağaçları..................................................................................................... 306
Yaprak eklenmesi .................................................................................... 307
Yaprak silinmesi ....................................................................................... 309
Kırmızı-Siyah Ağacı: 2-4 Ağacının Benzeri .......................................... 311
Kırmızı-Siyah Ağacı ve 2-4 Ağacı ....................................................... 313
Kırmızı-Siyah Ağacında Sola-Dayanım ............................................ 318
Ekleme ......................................................................................................... 321
Silme ............................................................................................................ 325
Özet.................................................................................................................... 334
Tartışma ve Alıştırmalar ............................................................................. 337
BÖLÜM 10 .............................................................................................................. 344
Yığınlar ................................................................................................................... 344
İkili Yığın: Bir Örtülü İkili Ağaç ................................................................ 344
Özet .............................................................................................................. 352
Karışık Yığın: Rasgele Karışık Yığın ........................................................ 353
merge(h1, h2) Analizi ............................................................................ 357
Özet .............................................................................................................. 360
Tartışma ve Alıştırmalar ............................................................................. 361
BÖLÜM 11 .............................................................................................................. 365
Sıralama Algoritmaları...................................................................................... 365
Karşılaştırmaya-Dayalı Sıralamalar ........................................................ 367
Birleştirerek-Sıralama ............................................................................ 368
Hızlı-Sıralama ............................................................................................ 373
|7
Yığın-Sıralama .......................................................................................... 379
Karşılaştırmaya Dayalı Sıralama için Alt-Sınır .............................. 383
Sayma Sıralama ve Taban Sıralaması .................................................. 388
Sayma Sıralaması.................................................................................... 389
Taban-Sıralaması..................................................................................... 392
Tartışma ve Alıştırmalar ............................................................................. 395
BÖLÜM 12 .............................................................................................................. 401
Grafikler................................................................................................................. 401
Bitişiklik Matrisi: Bir Grafiğin Matris ile Gösterimi ............................ 404
Bitişiklik Listeleri: Liste Derlemi olarak Grafik ................................... 409
Grafik Ziyaretleri ........................................................................................... 415
Enine-Arama ............................................................................................. 416
Derinliğine Arama.................................................................................... 419
Tartışma ve Alıştırmalar ............................................................................. 424
BÖLÜM 13 .............................................................................................................. 429
Tamsayılar için Veri Yapıları ........................................................................... 429
İkili Sıralı Ağaç: Sayısal Arama Ağacı ................................................... 431
X-Hızlı Sıralı Ağaç: Çifte-Logaritmik Zamanda Arama .................... 439
Y-Hızlı Sıralı Ağaç: Çifte-Logaritmik Zamanlı Sıralı Küme ............. 444
Tartışma ve Alıştırmalar ............................................................................. 453
BÖLÜM 14 .............................................................................................................. 457
Dış Bellek Aramaları.......................................................................................... 457
Blok Deposu .................................................................................................... 460
B-Ağaçları ........................................................................................................ 462
Arama .......................................................................................................... 466
Ekleme ......................................................................................................... 470
Silme ............................................................................................................ 476
B-Ağaç’ların Amortize Analizi .............................................................. 484
Tartışma ve Alıştırmalar ............................................................................. 489
KAYNAKÇA (BİBLİOGRAPHY) ............................................................................. 495
8|
|9
Kitap Hakkında
Açık Veri Yapıları, dizi (liste), kuyruk, öncelikli kuyruk, sırasız
küme, sıralı küme ve grafik gibi veri yapıları için geliştirilmiş uygulama ve veri yapılarının analizini kapsar. Hızlı, pratik, titiz ve
verimli bir matematiksel yaklaşım üzerinde yoğunlaşırken, Morin
açıkça ve dinamik olarak kaynak kod ile birlikte birtakım çözümlemeler sunar.
Java dilinde analiz edilmiş ve uygulanmış veri yapıları, kitapta sunulan, yığıt, kuyruk ve listelerin dizi ve bağlantılı liste uygulamalarını; liste ve sekme listelerinin alan-verimli uygulamalarını; karma
tabloları ve karma kodlarını; x-hızlı sıralı ağaç ve y-hızlı sıralı ağaç
üzerinde tamsayı arama yapılarını; grafikleri, bitişiklik matrislerini
ve B-ağaçlarını içerir.
https://archive.org/details/ost-computer-science-odstructuresjava
adresinde kitabın orijinal baskısını bulabilirsiniz.
10|
| 11
Yazar Hakkında
PAT MORIN, Carleton Üniversitesi’nde Bilgisayar Bilimleri Okulu’nda Profesör olmasının yanı sıra, açık erişimli Hesaplamalı Geometri Dergisi’nin kurucusu ve yönetici editörüdür. Hesaplamalı
geometri, algoritmalar ve veri yapıları konularında çok sayıda konferans makaleleri ve dergi yayınlarının yazarıdır.
12|
| 13
Çevirmen Hakkında
AYŞEGÜL TUNÇ, 1971 yılında Ankara'da dünyaya geldi. İlkokulu
TED Ankara Koleji'nde, ortaokul ve liseyi Ankara Atatürk Anadolu
Lisesi'nde takdirname derecesi ile bitirdi. Üniversitede birinci tercihine girdi ve burslu okudu. Annesinin vefatı ve babasının rahatsızlığı nedeniyle çalışmıyor. Ev-ofisinde yaptığı iş Internet-tabanlı
betik programlar geliştirmek ve bilgisayar bilimleri alanına ait dikkatini çeken konularda Türkçeye çeviriler yapmaktadır. Son yıllarda “İşbirliğine Dayalı Öğrenme ve Açık Eğitim Hareketi” kapsamında serbest lisanslamalar artış gösterdi. Çevirmen de bu uygulamalar arasından seçimlerde bulunarak işe başladı.
14|
| 15
Bölüm 1
Giriş
Dünyadaki bilgisayar bilimleri öğretim programlarının tümünde,
veri yapıları ve algoritmalar üzerine bir ders içeriği bulunmaktadır.
Veri yapıları bu kadar önemlidir; her gün, hafta ve ay bizi tehlike,
zarar ve başarısızlıktan korur, böylece daha başarılı oluruz. Pek çok
multi-milyon ve multi-milyar liralık şirketler ihtiyaçları veya gereksinimlerine uygun, birçok veri yapısı etrafında yapılandırılmışlardır.
Bu nasıl olabilir? Eğer biraz düşünürsek, veri yapıları ile belirli bir
süre boyunca çok sık veya her zaman etkileşim içinde olduğumuzu
anlarız.
Dosya açmak: Dosya sistemine ait veri yapıları bir dosyanın
parçalarını diskte bulmak için kullanılır, böylece o dosyaya erişebiliriz. Bu kolay değildir; diskler yüzlerce milyon blok içerir. Dosyanızın içeriği bunlardan herhangi biri üzerinde depolanmış olabilir.
Telefonunuzda kayıtlı olan bir kişiye bakmak: Siz arama-
yı/yazmayı bitirmeden önce, kısmi bilgiye dayalı olarak kişi listesindeki bir telefon numarasını aramak için bir veri yapısı kullanılır.
Bu kolay değildir; telefonuzda pek çok insan hakkında bilgiler ka-
16|
yıtlı olabilir - telefon veya e-posta yoluyla görüştüğünüz herkes ve telefonunuzun çok hızlı bir işlemcisi, veya belleği olmak zorunda değildir.
En sevdiğiniz sosyal ağınıza giriş yapmak: Ağ sunucuları, he-
sap bilgilerinize bakmak için giriş bilgilerinizi kullanır. Bu kolay
değildir; en popüler sosyal ağlar yüzlerce milyon aktif kullanıcı
içerir.
Web araması yapmak: Arama motoru, arama terimlerinizi içe-
ren web sayfalarını bulmak için veri yapılarını kullanır. Bu kolay
değildir; Internet üzerinde 8,5 milyarın üzerinde web sayfası vardır
ve her sayfa pek çok potansiyel arama terimlerini içerir.
Telefon acil durum hizmetleri (1-5-5): Polis arabaları, ambu-
lanslar ve itfaiye araçları gecikmeden adresinize gönderilsin diye,
acil servis şebekeleri, telefon numaralarını adreslerle eşleştiren bir
veri yapısı kullanarak sizin telefon numaranızı arar. Bu önemlidir;
çağrıyı yapan kişinin tam adresini vermesi mümkün olmayabilir ve
bir gecikme ölüm kalım arasındaki fark anlamına gelebilir.
| 17
Verimlilik Gereksinimi
Bir sonraki bölümde, en sık kullanılan veri yapıları tarafından desteklenen işlemlere bakacağız. Biraz programlama deneyimi olan
herkes, bu işlemleri doğru olarak gerçekleştirmenin zor olmadığını
görecektir. Verileri, muhtemelen, bir dizi veya bağlantılı-listede
depolayabiliriz ve dizi veya listedeki tüm elemanlar üzerinden yineleme yaparak, örneğin, bir elemanı ekleyebilir veya silebiliriz.
Bu tür bir uygulama kolaydır, ancak çok verimli değildir. Bu gerçekten önemli midir? Bilgisayarlar hızlı ve gitgide daha hızlı hale
gelmektedir. Belki, anlaşılması kolay olan uygulama daha iyidir.
Yaklaşık hesaplamalar yaparak öğrenmeye çalışalım.
6
İşlem sayısı: 1 milyon (10 ) elemanı olan, orta ölçekte bir veri kümesi kullanan uygulamayı düşünün. Bu uygulamanın en az bir defa
her elemanı aramak istemesi, çoğu uygulama için makul bir varsa6
yımdır. Bu demektir ki, veri içinden en az 1 milyon (10 ) arama
6
yapmayı bekleyebiliriz. Her arama için, 10 inceleme yapılacaksa,
6
6
12
toplamda bu, 10 x 10 = 10
(bir trilyon) arama eder.
İşlemci hızları: Çok hızlı bir masaüstü bilgisayar bile, saniyede bir
9
milyardan fazla (10 ) yazdırma işlemi yapamaz. Bu demektir ki, bir
uygulama en az 10
12
9
/ 10 = 1.000 saniye veya yaklaşık 16 dakika
ve 40 saniye alacaktır. Onaltı dakika bilgisayar zamanı için birçok
18|
uzun bir zamandır, kahve molası vermek için dışarıya yönelen bir
kişi ancak bu zamanı ayırabilir.
Büyük veri setleri: Şimdi 8,5 milyar’ın üzerinde web sayfasını
endeksleyen, Google gibi bir şirket düşünün. Hesaplarımıza göre,
bu veriler üzerinde yapılacak her türlü sorgu en az 8,5 saniye sürer.
Ancak, bu durumda olmadığımızı zaten biliyoruz; web aramaları
8,5 saniyeden çok daha az sürede tamamlanıyor ve belirli bir sayfanın kendilerine endeksli sayfalar içinde olup olmadığını sormak
yanında, çok daha karmaşık sorguları da yapabiliyorlar. Google,
saniyede yaklaşık 4.500 sorgu gerçekleştirir, bu işi yürütebilmeleri
için, en az 4.500 x 8,5 = 38.250 sayıda çok hızlı sunucuya gereksinim duyarlar.
Çözüm: Bu örnekler bize şunu söylemektedir: Veri yapısındaki
eleman sayısı olan n, ve gerçekleştirilen işlem sayısı olan, m, verildiğinde özellikle her ikisi de büyük olduğunda, besbelli algoritmalar için iyi ölçeklendirme sağlanamamaktadır. Yaklaşık bir hesaplamayla, bu algoritmalar için gerekli olan çalışma zamanı (diyelim
ki, makine komutu cinsinden ölçüldüğünde)
n x m olarak
hesaplanır.
Çözüm, tabii ki, her işlemin her elemanı kontrol etmemesidir, bunu
sağlayacak şekilde veri yapısı içindeki verilerin dikkatle düzenlenmesi gerekiyor. Veri yapısı içinde depolanmış bulunan eleman sayısından bağımsız olarak, sadece ortalama iki elemana bakarak
arama yapabilen veri yapılarını göreceğiz. Bilgisayarınız, saniyede
| 19
milyar komut çalıştırabiliyorsa, bir milyar (veya bir trilyon, bir katrilyon ve hatta bir kentilyon) eleman içeren bir veri yapısı içinde
arama yapmak, sadece 0,000000002 saniye alacaktır.
Sıralı veri tutan bir yapı için, eleman sayısına bağlı olarak, bir işlem
sırasında kontrol edilen eleman sayısı çok yavaş büyüme kaydedebilir. Örneğin, herhangi bir işlem sırasında, en fazla 60 elemanı
kontrol edecek şekilde, bir milyar elemanı sıralı olarak tutabiliriz.
Saniyede milyar komut çalıştırabilen bilgisayarınızda, bu işlemler
0,00000006 saniye alacaktır.
Bu bölümün kalan kısmında, bazı temel kavramları yorumlayacağız. Arayüzler Bölümü’nde, kitapta anlatılan veri yapılarının tamamı tarafından gerçekleştirilen arayüzler açıklanıyor ve okunması
için gereken dikkati vermelisiniz. Kalan bölümlerde şunları tartışacağız:
Üsler, logaritma, faktöriyel, asimptotik (büyük-Oh) gösterimi, olasılık ve randomizasyon dahil olmak üzere bazı matematiksel incelemeler;
Hesaplama modeli;
Doğruluk, yürütme zamanı ve alanı;
Kalan bölümlere genel bir bakış, ve
Örnek kod ve dizgi kuralları.
20|
Bu alanlarda birikim sahibi olan veya olmayan okuyucular için,
şimdilik bu tartışmalar atlanabilir, ve gerekirse, daha sonra tekrar
geri dönüş sağlanabilir.
| 21
Arayüzler
Veri yapılarını tartışırken, bir veri yapının arayüzü ile uygulaması
arasındaki farkı anlamak önem arz eder. Arayüz bir veri yapısının
ne yaptığını açıklarken, uygulaması bunu nasıl yaptığını açıklar.
Bazen, soyut veri türü olarak da adlandırılan arayüz, bir veri yapısı
tarafından desteklenen işlem kümesini ve bu işlemlerin semantiğini, yani anlamını, tanımlar.
Arayüz, veri yapısının bu işlemleri nasıl gerçekleştirdiğine dair hiçbir şey söylemez; sadece desteklenen işlemlerin bir listesini ve her
işlemin ne tür argümanları kabul ettiğini ve döndürdükleri değer
hakkındaki gereksinimleri belirtir.
Bir veri yapısını gerçekleştirmek, diğer taraftan, veri yapısının iç
gösterimini ve aynı zamanda veri yapısı tarafından desteklenen
işlemleri uygulamaya koyan algoritmaların tanımlarını içerir. Bu
nedenle, tek bir arayüzün birçok uygulaması olabilir. Örneğin, Liste
arayüzünün uygulamalarını görürken, Bölüm 2, dizileri işleyecek;
Bölüm 3, işaretçi-tabanlı veri yapılarını işleyecek. Her ikisi de aynı
arayüzü, Liste’yi, farklı şekillerde uygulamıştır.
22|
Kuyruk, Yığıt ve İki Başlı Kuyruk
Arayüzleri
Kuyruk
arayüzü, elemanları ekleyebildiğimiz ve sonraki elemanı
silebildiğimiz bir elemanlar topluluğunu gösterir. Daha kesin olarak, Kuyruk arayüzü tarafından desteklenen işlemler şunlardır:
ekle(x): Kuyruğa x değerini
sil():
ekler.
Daha önceden eklenmiş bulunan y değerini kuyruktan
siler, ve y değerini döndürür.
sil()
işleminin hiçbir argüman almadığına dikkat ediniz. Kuyruk’un
kuyruklama disiplini hangi elemanın kaldırılması gerektiğine karar
verir. En yaygın olarak FIFO (ilk-giren-ilk-çıkar), Öncelik Kuyruğu,
ve LIFO(son-giren-ilk-çıkar) dahil olmak üzere birçok olası
kuyruk disiplinleri vardır.
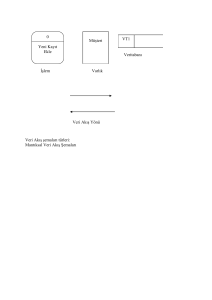
Şekil 1.1'de gösterilen FIFO(ilk-giren-ilk-çıkar) Kuyruk’u, elemanları ekleme sırasıyla aynı sırada siler. Bunu, bir bakkalın kasasında
çalışan kuyruğa (veya sıraya) benzetebiliriz. Bu, en sık rastlanan
Kuyruk
türüdür, bu nedenle, FIFO sıfatı genellikle ihmal edilir; kul-
lanılmaz. FIFO Kuyruğu üzerindeki ekle(x) ve sil() işlemleri, sırasıyla, kuyruğa koy(x) ve kuyruktan kaldır() olarak adlandırılmıştır.
| 23
Şekil 1.2'de gösterilen Öncelik Kuyruğu, her zaman, en küçük elemanı siler, bağları buna uygun olacak şekilde kırar. Bunu, bir hastanenin acil serviste hastalara servis vermesine benzetebiliriz. Hastalar, geldikçe değerlendirilir ve daha sonra bir bekleme odasına
yerleştirilir. Bir doktor müsait olduğunda, ilk olarak yaşam tehditi
en fazla bulunan hasta ile ilgilenir. Öncelik Kuyruğu üzerindeki
sil() işlemi, silMin()
olarak adlandırılmıştır.
Çok yaygın bir kuyruk disiplini de Şekil 1.3'de gösterildiği gibi
LIFO(son-giren-ilk-çıkar)
disiplinidir. LIFO Kuyruğu’nda, en son
eklenen eleman silinir. Bunu en iyi olarak, tabakların üst üste dizildiği bir tabak yığıtı şeklinde görselleştirebiliriz. Yeni bir tabağı
yığıtın en üstüne dizeriz; tabak çıkarırken yığıtın en üstünden çıkarırız. Bu yapıya çok sık rastlanır ve Yığıt adı altında incelenir. Yığıt
tartışılırken, ekle() ve sil() işlemleri, çoğu zaman yığ() ve
yığıttan_kaldır()
olarak değiştirilmiştir, bunun nedeni LIFO ve FIFO
Kuyruk disiplinlerinin
birbirine karıştırılmamasıdır.
24|
İki Başlı Kuyruk,
(Yığıt)
hem FIFO Kuyruğu ve hem LIFO Kuyruğu’nun
genelleştirilmiş bir halidir. Önü ve arkası bulunan eleman-
lardan oluşan bir diziyi gösterir. Elemanlar dizinin başına veya sonuna eklenebilir. İki Başlı Kuyruk işlemlerinin adları da kendi kendilerini açıklayıcıdır: başaEkle(x), baştanSil(), sonaEkle(x),
sondanSil().
baştanSil()
Şunu belirtmeliyiz ki, Yığıt sadece başaEkle(x) ve
işlemleri kullanılarak uygulanabilirken, FIFO Kuyruk
da sadece sonaEkle(x) ve sondanSil() işlemleri kullanılarak uygulanabilir.
| 25
Liste Arayüzü: Doğrusal Diziler
Bu kitapta, FIFO Kuyruk, Yığıt veya İki Başlı Kuyruk arayüzleri
hakkında çok az konuşacağız. Bunun nedeni, bu arayüzlerin, Liste
arayüzü tarafından kapsanmış olmasıdır.
Şekil 1.4’teki Liste, x0,…,xn-1 değerlerinden oluşan bir diziyi gösteriyor. Liste arayüzü aşağıdaki işlemleri içermektedir:
1.
boyut():
2.
al(i):
3.
belirle(i, x):
4.
ekle(i, x): xi,…,xn – 1’in
x
Listenin uzunluğu olan, n, değerini döndürür.
Listenin xi değerini döndürür.
Listenin xi değerini x’e eşitler.
değerini yerleştirir. Her j
yerini değiştirerek, listenin i konumuna
{n – 1,…,i} için xj + 1 = xj
eşitler, n’i
bir artırır, ve xi = x eşitler.
5.
sil(i): xi
siler. Her j
+ 1,…,xn – 1
’in yerini değiştirerek, xi değerini listeden
{i,…, n – 2} için xj = xj + 1 eşitler, n’i
bir azaltır.
Unutmayın ki, bu işlemler, İki Başlı Kuyruk arayüzünü de uygulamak için kesinlikle yeterlidir. Şöyle ki:
başaEkle(x)
ekle(0, x)
26|
baştanSil()
sil(0)
sonaEkle(x)
ekle(boyut(), x)
sondanSil()
sil(boyut() – 1)
Daha sonraki bölümlerde Yığıt, İki Başlı Kuyruk ve FIFO Kuyruk
arayüzleri tartışılmasa da, Yığıt ve İki Başlı Kuyruk terimleri, Liste
arayüzünü gerçekleştiren bazı veri yapılarını adlandırmakta kullanılmıştır. Bu veri yapıları, Yığıt veya İki Başlı Kuyruk arayüzlerini
çok
verimli
uygulamak
DiziİkiBaşlıKuyruk
için
kullanılmıştır.
Örneğin,
sınıfı tüm İki Başlı Kuyruk işlemlerini sabit za-
manda gerçekleştiren bir Liste arayüzü uygulamasıdır.
| 27
UKüme Arayüzü: Sıralı Olmayan
Kümeler
UKüme
arayüzü matematiksel bir diziye benzeyen, tekil elemanlar-
dan oluşan ve sıralı olmayan bir kümeyi gösterir. Bir UKüme, n
farklı eleman içerir; hiçbir eleman bir defadan fazla görünmez, ve
elemanlar hiçbir belirli sırada sıralanmamıştır. Bir UKüme aşağıdaki işlemleri desteklemektedir:
1.
boyut(): Kümedeki
2.
ekle(x): x
eleman sayısı olan, n, değerini döndürür.
elemanı kümede zaten mevcut değilse, kümeye ek-
ler. Kümede hiçbir y elemanı yoktur ki, x, y’ye eşit olarak hesaplanırsa, x elemanı kümeye eklensin. x kümeye eklendiği takdirde,
true döndürür,
3.
sil(x):
ve aksi takdirde false döndürür.
Kümeden x elemanını siler. Kümede öyle bir y elemanı
bulur ki x, y’ye eşit olarak hesaplanırsa, y’yi silsin. Bu tür bir eleman yoksa, null, varsa y elemanını döndürür.
4.
y
bul(x):
Kümede mevcutsa, x elemanını bulur. Kümede öyle bir
elemanı bulur ki y, x’e eşit olsun. Bu tür bir eleman yoksa, null,
varsa y döndürür.
Bu tanımlar, sildiğimiz veya bulduğumuz değer olan x ile, silebileceğimiz veya bulabileceğimiz değer olan y arasındaki ayrımı biraz
belirsiz yapıyor. Bunun nedeni, x ve y eşit olarak değerlendirilirse
de, aslında farklı nesneler olabilirler. Böyle bir ayrım yararlıdır,
28|
çünkü anahtarları değerlerle eşleştiren sözlük veya eşlemlerin oluşturulmasına izin verir.
Bir sözlük/eşlem oluşturmak için, her biri anahtar ve değer içeren,
Çiftler
diye adlandırılan, bileşik nesneleri oluşturmamız gerekir. İki
Çift’in
anahtarları eşitse, kendileri de eşit olarak kabul edilir. (k, v)
çifti bir UKüme’de depolanır, ve daha sonra x = (k, null) çifti kullanılarak bul(x) işlemi çağrılırsa, sonuç y = (k, v) olacaktır. Diğer
bir deyişle, sadece anahtar, k değeri verilerek, v’yi geri kazanmak
mümkündür.
| 29
SKüme Arayüzü: Sıralı Kümeler
SKüme
arayüzü, sıralanmış elemanların bir kümesini gösterir.
SKüme
elemanlarının tamamı sıralı halde depolanır, böylece her-
hangi iki eleman, x ve y karşılaştırılabilir. Kod örneklerinde bu,
karşılaştır(x, y)
adı verilen ve tanımı aşağıdaki gibi olan bir işlem-
le yapılacaktır:
SKüme, boyut(x), ekle(x), sil(x)
işlemlerini UKüme arayüzüyle
aynı anlamda olacak bir şekilde destekler. UKüme ile SKüme arasındaki fark bul(x) işlemindedir:
bul(x) :
Sıralı kümede x’i bulur. Kümede öyle bir en küçük y
elemanı bulur ki y ≥ x olsun. Bu tür bir eleman yoksa, null, varsa y
döndürür.
Bu tarzdaki bul(x) işlemi, bazen bir ardıl arama olarak adlandırılır.
UKüme.bul(x)’ten
temel bir şekilde farklıdır, çünkü kümede x’e
eşit herhangi bir eleman olmasa bile anlamlı sonuç döndürür.
bul(x)
işleminin UKüme ve SKüme uygulaması arasındaki ayrım
çok önemlidir ve çoğu kez cevapsızdır. Bir SKüme tarafından sağlanan ekstra işlevsellik, genellikle hem daha büyük bir çalışma za-
30|
manı ve hem daha yüksek bir uygulama karmaşıklığını içeren bir
bedel ile birlikte gelir. Örneğin, bu kitapta tartışılan SKüme uygulamalarının çoğunda bul(x) işlemleri küme boyutu ile logaritmik
bir çalışma zamanına sahiptir. Öte yandan, Bölüm 5’teki gibi
UKüme’nin ZincirliKarımTablosu
olarak uygulamasında sabit bek-
lenen zamanda çalışan bir bul(x) işlemi sözkonusudur. Hangi yapıyı seçeceğinize karar verirken, SKüme tarafından sunulan ekstra
işlevsellik gerçekten gerekli olmadıkça, her zaman bir UKüme kullanmalısınız.
| 31
Matematiksel Zemin
Bu bölümde, logaritma, büyük-Oh gösterimi ve olasılık teorisi de
dahil olmak üzere, bu kitap boyunca kullanılan bazı matematiksel
ifadeleri ve araçlarını gözden geçireceğiz. Bu yorum kısa olacaktır
ve giriş olarak tasarlanmamıştır. Birikimlerinin eksik olduğunu
hisseden okuyuculara, bilgisayar bilimleri için matematik [50] konusunda yazılmış çok iyi (ve ücretsiz) ders kitabını okumalarını ve
alıştırmalarını çözmelerini tavsiye ediyoruz.
Üslüler ve Logaritmalar
x
b ifadesi, b sayısının x üssüne yükseltilmiş halini gösterir. x pozitif
bir tamsayıysa, bu sadece b değerinin x – 1 defa kendisiyle çarpılmış haline eşittir:
x
-x
x negatif bir tamsayı olduğu zaman, b = 1 / b olarak hesaplanır. x
x
= 0 iken, b = 1 olarak hesaplanır. b tamsayı değilse, üssel fonksix
yon, üssel seri olarak tanımlanan e cinsinden tanımlanabilir, ancak
en iyisi bunu bir hesap analizi kitabına bırakmaktır.
Bu kitapta, logb k ifadesi k’nın b-tabanlı logaritmasını ifade eder.
Yani, tekil bir x değeri aşağıdaki koşulu sağlar.
32|
Bu kitaptaki logaritmaların çoğu taban 2’dir (ikili logaritmadır).
Bunlar için taban ihmal edilir, böylece log2 k için kısaltma log k
olarak verilir.
Logaritmaları düşünmenin biçimsel, ancak yararlı bir yolu da, logb
k için sonuç 1'e eşit veya daha az olana dek k’nın b’ye kaç defa
bölündüğünü bulmaktır. Örneğin, bir ikili arama gerçekleştirdiğimizde, her yapılan karşılaştırma, muhtemel cevapların sayısını 2
faktörü kadar azaltır. Olası en çok bir cevap kalana kadar, bu tekrarlanır. Bu nedenle, başlangıçta en fazla n + 1 olası cevap olduğunda ikili arama tarafından yapılan karşılaştırma sayısı en fazla
[log2(n+1)] olarak hesaplanır.
Bu kitapta birkaç kez ortaya çıkan başka bir logaritma türü de doğal logaritmadır. Burada loge k belirtimi için ln k gösterimi kullanılır. e – Euler sabiti – olarak aşağıda bildirilmiştir:
Doğal logaritma sık sık gündeme gelmektedir, çünkü aşağıda verilen özellik ile ifade edildiği gibi, sıkça karşılaştığımız bir integralin
değeridir:
| 33
Logaritmalar ile en çok yaptığımız iki çalışmadan birincisi, onları
bir üsse kaldırmaktır:
İkincisi, logaritmanın tabanını değiştirmektir:
Örneğin, doğal ve ikili logaritmayı karşılaştırmak için şu iki işlemi
kullanabilirsiniz:
34|
Faktöryeller
Bu kitapta, bir veya iki yerde, faktöryel fonksiyonu kullanılmıştır.
Negatif olmayan bir n tamsayısı için, n! (okunuşu "n faktöryel")
gösterimi şöyle tanımlıdır:
Faktöryellerin
ortaya
çıkmasına
sebep,
n
farklı
elemanın
permütasyon sayısını, yani, sıralamasını saymaktır. Bu sonuç n! ile
gösterilir. n = 0 özel durumu için, 0! = 1 olarak tanımlıdır.
n! sayısı, Stirling'in Yaklaşımını kullanarak da, yaklaşık olarak
tahmin edilir:
Burada,
Stirling'in Yaklaşımıyla, ln (n!) değeri de, yaklaşık olarak tahmin
edilir:
| 35
(Aslında, Stirling'in Yaklaşımı’na en kolay kanıt, ln (n!) = ln 1 + ln
2
+
…
+
ln
n
ifadesinin
değerini
yaklaşık
olarak
integrali ile tahmin ederek verilir).
Faktöryel fonksiyonu ile ilgili olarak iki terimli katsayılara değineceğiz.
k
Negatif
olmayan
bir
tamsayı
n,
ve
bir
tamsayı
{0,…,n} için şu gösterim doğru olarak hesaplanır:
ile gösterilen iki terimli katsayının okunuşu, “n’in k tercihi”
olarak telaffuz edilmelidir. n elemanlı bir kümenin, k elemanlı alt
kümelerinin sayısını saymaya yarayan bu ifade, 1,…, n kümesinden k farklı tamsayıyı seçme yollarının sayısını verir.
36|
Asimptotik Gösterim
Bu kitapta veri yapılarını analiz ederken, çeşitli işlemlerin çalışma
zamanları hakkında konuşmak istedik. Tam kesinlikteki çalışma
zamanı, tabii ki, bilgisayardan bilgisayara ve hatta tek bir bilgisayar
üzerindeki uygulamaları çalıştırmadan çalıştırmaya değişecektir.
Bir işlemin çalışma zamanı hakkında konuştuğumuzda, işlem sırasında gerçekleştirilen bilgisayar komutlarının sayısına başvuruyoruz. Basit bir kod için bile, bu miktarı tam olarak hesaplamak zor
olabilir. Bu nedenle, çalışma zamanlarını tam kesinlikte analiz etmek yerine, büyük-Oh adı verilen notasyonu kullanacağız: Bir f (n)
fonksiyonu verildiğinde, O(f (n)) ile sınırlandırılmış bir fonksiyon
kümesi şöyle tanımlanır:
Grafiksel düşünüldüğünde, bu küme fonksiyonları, g(n) fonksiyonlarından oluşur; burada c f(n),
n yeterince büyük olduğunda,
g(n)’e başat olmaya başlar.
Genellikle fonksiyonları kolaylaştırmak için asimptotik gösterim
kullanılır. Örneğin, 5n log n + 8n – 200 yerine O (n lg n) yazılabilir
ve şu şekilde kanıtlanabilir:
| 37
Bu gösteriyor ki, 5n log n + 8n – 200 fonksiyonu c = 13 ve n0 = 2
için O (n lg n) kümesinin bir üyesidir.
Asimptotik notasyonu kullanırken, bir dizi faydalı kısayollar uygulanabilir. Birincisi: Herhangi bir c1 < c2 için,
İkincisi: Herhangi a, b, c > 0, sabit olmak şartıyla,
Bu kapsama bağıntıları, herhangi bir pozitif değer ile çarpıldığında,
hala geçerlidir. Örneğin, n ile çarpıldığında şu bağıntı elde edilir:
Uzun ve seçkin bir geleneğin devamı olarak, bu notasyonu kötüye
kullanarak, gerçekte f1(n) O(f(n)) demek yerine, f1(n)= O( f(n) )
yazabilirsiniz. Yine, “bu işlemin yürütme zamanı O(f (n))’dir.” gibi
cümleler kurabilirsiniz. Gerçekte bu cümle “bu işlemin yürütme
zamanı O(f (n))’in bir üyesidir.” olmalıdır. Bu kısayollar, çoğun-
38|
lukla asimptotik notasyonu daha kolay denklem dizeleri içinde kullanmamızı sağlar.
Aşağıdaki gibi ifadeler yazarken, özellikle garip bir örnek ortaya
çıkar:
Yine, bu daha doğru bir şekilde şöyle yazılmalıdır:
O (1) ifadesi başka bir konuyu da gündeme getiriyor. Bu ifadede
hiçbir değişken bulunmadığından, hangi değişkenin rasgele büyük
olduğu açık olmayabilir. Bağlam olmadan bunu söylemenin hiçbir
yolu yoktur. Yukarıdaki örnekte, denklemin geri kalanındaki tek
değişken n olduğu için, denklemi şöyle okumamız gerektiğini varsayabiliriz: f(n) = 1 iken; T(n) = 2 log(n) + O (f(n)).
Büyük-Oh notasyonu bilgisayar bilimleri için yeni ve benzersiz
değildir. Sayı kuramcısı Paul Bachmann tarafından 1894 gibi erken
bir tarihte kullanılmıştır ve bilgisayar algoritmalarının yürütme
zamanlarını açıklamak için son derece yararlıdır. Aşağıdaki kod
parçasını düşünün:
| 39
Uygulanan bu yöntemin içerdiği işlemler şu listede sıralanmıştır:
1 atama (int i = 0),
n + 1 karşılaştırma (i < n),
n artırım (i ++),
n bağıl konum dizi hesaplaması (a[i]), ve
n dolaylı atama (a[i] = i).
Bu yüzden, çalışma zamanını şöyle yazabiliriz:
Burada a, b, c, d ve e, kodu çalıştıran makineye bağlı olan sabitlerdir, ve sırasıyla atamaları, karşılaştırmaları, artırım işlemlerini, bağıl konum dizi hesaplamalarını ve dolaylı atamaları gerçekleştirmek için gerekli zamanı gösterir. Bu ifade, iki satır kod çalışma
zamanını gösterse de, açıkça bu tür bir analiz karmaşık kod veya
algoritmalar için
kolaylıkla
işlenemeyecektir.
Büyük-Oh
notasyonunu kullanarak, çalışma zamanının basitleştirilmiş hali
şöyledir:
40|
Bu sadece daha küçük boyutlu olmakla kalmaz, ama aynı zamanda
yaklaşık olarak aynı bilgiyi verir. Yukarıdaki örnekte, çalışma zamanının a, b, c, d ve e sabitlerine bağlı olması, genel olarak, sabit
değerlerini bilmeksizin, iki çalışma zamanından hangisinin daha
hızlı olduğunu bilmek ve bu amaçla karşılaştırma yapmanın da
mümkün olamayacağı anlamına gelir. Sabit değerlerini belirlemek
için (diyelim ki, zamanlama testleri aracılığıyla) çaba göstersek
bile, sonuç sadece bizim üzerinde test yaptığımız makine için geçerli olacaktır.
Büyük-Oh notasyonuyla daha karmaşık fonksiyonları çözümleyerek, çok daha yüksek düzeyde akıl ve mantık yürütebilir ve düşünebilirsiniz. Aynı büyük-Oh çalışma zamanına sahip iki algoritmanın, hangisinin daha hızlı olduğunu bilemezsiniz ve net bir kazanan
olmayabilir. Biri tek makinede daha hızlı olabilir ve diğeri farklı bir
makinede daha hızlı olabilir. Ancak, emin olabilirsiniz ki, iki algoritmanın kanıtlanabilir farkı, daha az büyük-Oh çalışma zamanı
olan algoritmanın, yeterince büyük n değerleri için daha hızlı olacağıdır.
Büyük-Oh notasyonu, iki farklı fonksiyonu karşılaştırmaveya olanak sağlar. Şekil 1.5’teki örnek, f1(n) = 15n ve f2(n)=2n log n fonksiyonlarının büyüme hızlarını karşılaştırıyor. Burada f1(n) karmaşık
bir doğrusal zaman algoritmasının yürütme zamanı olabilir; f2(n)
böl-ve-yönet paradigmasına dayanan oldukça daha basit bir algoritmanın çalışma zamanı olabilir. Bu örnek gösteriyor ki, küçük n
değerleri için f1(n), f2(n)'den daha büyük olmasına rağmen, büyük
| 41
n
değerleri için tersi geçerlidir. Sonunda f1(n) giderek artan farkla
kazanır. Büyük-Oh gösterimini kullanarak yapılan analiz, bunun
böyle olacağını bize anlatmıştı, çünkü O (n)
O (n log n) .
Birkaç durumda, birden fazla değişkenli fonksiyonlar üzerinde de
asimptotik gösterimi kullanacağız. Bunun için herhangi bir standart
yoktur, ancak amaçlarımız için, aşağıdaki tanım yeterli olacaktır:
Bu tanım, bizim gerçekten önem verdiğimiz koşulu, n1,…,nk argümanlarının g ’nin büyük değer almasını sağlaması durumunu yakalar. Bu tanım, aynı zamanda tek değişkenli O(f (n)) tanımı ile, f (n)
n’in artan bir fonksiyonu olduğu zaman uzlaşır. Bizim amaçlarımız
için bu kadarı yeterlidir, ancak okuyucu çok değişkenli fonksiyonlar ve farklı asimptotik gösterimlerin de ele alınabileceğini bilmelidir.
42|
| 43
Rasgele Sıralama ve Olasılık
Bu kitapta sunulan veri yapılarının bazıları rasgeleleştirilmiştir,
depolanan veri değerlerinden veya üzerinde yapılan işlemlerden
bağımsız olarak, rasgele seçimler yapar. Bu gibi yapıları kullandığınızda, aynı işlem kümesinin bir defadan fazla çalışmasıyla farklı
yürütme zamanları oluşabilir. Analiz ederken, veri yapılarının ortalama veya beklenen çalışma süreleri ile ilgileniriz.
Kurallı olarak, bir rasgele veri yapısı üzerindeki işlemin çalışma
zamanı rasgele bir değişkendir ve beklenen değerini incelemek
istiyoruz. Sonlu ve sayılabilir bir U uzayından değer alan, X ile
tanımlı bir sonlu rasgele değişken için, X ’in beklenen değeri olan E
[X] aşağıdaki formül ile verilmiştir:
Burada
olay
’nin meydana gelme olasılığını gösterir. Bu
kitaptaki tüm örneklerde, bu olasılıklar yalnızca rasgeleleştirilmiş
veri yapısı tarafından yapılan rasgele seçimler hakkındadır; ne veri
yapısında depolanan verinin, ne de veri yapısı üzerinde gerçekleştirilen işlem sırasının, rasgele olduğuna dair bir varsayım yoktur.
Beklenen değerlerin en önemli özelliklerinden biri, beklentinin
doğrusallığıdır. Herhangi iki rasgele değişken, X ve Y için,
44|
Daha genel olarak, herhangi bir rasgele değişken dizisi X1,…,Xk
için,
Beklentinin doğrusallığı, karmaşık rasgele değişkenleri (yukarıdaki
denklemlerin sol tarafındakiler gibi), basit rasgele değişkenlerin bir
toplamı halinde (sağ taraflar) bölmeye olanak sağlar.
Tekrar tekrar kullanacağımız yararlı bir püf noktası, gösterge
rasgele değişkenlerini tanımlamaktır. Bu ikili değişkenler, bir şeyi
saymak istediğimizde yararlıdır; açıklayıcı en iyi bir örnek şöyle
verilir. Bir bozuk parayı k defa hilesiz fırlattığımızı varsayalım,
para yere düşünce kaç kez tura gelmesinin beklenen sayısını bilmek
istiyoruz. Sezgisel olarak, cevabın k/2 olduğunu biliyoruz, ancak
değer beklentisi tanımını kullanarak bunu kanıtlamaya çalışırsak,
| 45
Burada,
olasılığını hesaplamayı ve
ve
ikili özdeşliklerini yeterince bilmeniz gereklidir.
Gösterge değişkenlerini ve beklentinin doğrusallığı ilkesini kullanarak işler çok daha kolay hale gelir. Her i
ge rasgele değişkeni tanımlayalım:
O zaman,
Şimdi,
, bu nedenle,
1,…,k için, göster-
46|
Sözü biraz uzattık, ancak herhangi bir sihirli özdeşliği bilmemizi
veya herhangi bir kayda değer olasılık hesabını gerektirmiyor. Daha da iyisi, paraların tam olarak yarısının tura geleceği sezgisi ile
uyumludur, çünkü her para 1/2 olasılık ile tura olarak ortaya çıkıyor.
| 47
Hesaplama Modeli
Bu kitapta, çalıştığımız veri yapıları üzerindeki işlemlerin teorik
çalışma sürelerini analiz edeceğiz. Tam olarak bunu yapmak için,
bir matematiksel hesaplama modeli gereklidir. Bunun için, w-bit
sözcük-RAM modelini kullanacağız. RAM Rasgele Erişimli Makine’ye denk gelir. Bu modelde, her biri w-bit sözcük depolayan hücrelerden oluşan bir rasgele erişimli belleğe erişimimiz vardır. Bu
demektir ki, bir bellek hücresi, örneğin,
kümesin-
den bir tamsayıyı gösterebilir.
Sözcük-RAM modelinde, sözcükler üzerindeki temel işlemler sabit
zaman alır. Aritmetik işlemleri
, karşılaştırmaları
, ve bitsel-Boole işlemlerini içerir (bit-bit-VE,
VEYA, ve dışlayıcı-VEYA).
Herhangi bir hücre, sabit zamanda okunabilir veya yazılabilir. Bir
bilgisayarın belleği, istediğimiz herhangi büyüklükte bir bellek
bloğunun tahsis edilmesini veya serbest bırakılmasını sağlayacak
bir bellek yönetim sistemi tarafından yönetilmektedir. k boyutunda
bir bellek bloğunu tahsis etmek, O(k) zaman alır ve yeni ayrılan
bellek bloğu için bir işaretçi döndürür. Bu işaretçi, bir tek sözcük
ile temsil edilebilecek kadar küçüktür.
Sözcük-boyutu, w, bu modelin çok önemli bir parametresidir. w
hakkında yapılacak tek varsayım alt sınır
olmuştur, bu-
48|
rada n herhangi bir veri yapısında depolanan elemanların sayısıdır.
Bu oldukça orta halli bir varsayımdır, aksi takdirde bir veri yapısında depolanan elemanların sayısını saymak için bile sözcük yeterince büyük olmayacaktır.
Alan, bellek sözcüğü ile ölçülür, bir veri yapısı tarafından kullanılan alan miktarından bahsederken, kullanılan bellek sözcüğü sayısı
ile ilgilenmeliyiz. Veri yapılarınızın tamamı, bir genelleyici tür
olan T değeri ile tanımlı olabilir, ve T türü bir elemanın belleğin bir
sözcüğünü kapladığını varsayabilirsiniz (gerçekte, T türü nesnelere
referansları depoluyoruz, ve bu referanslar bellekte sadece bir sözcük kaplıyor). 32-bit Java Sanal Makinesi (JVM) için, w-bit sözcük-RAM modeli, w=32 olduğunda, oldukça uygundur. Bu kitapta
sunulan veri yapıları, JVM ve çoğu diğer mimari üzerinde uygulanamaz özellikte yaklaşımlar kullanmamaktadır.
| 49
Doğruluk, Zaman Karmaşıklığı ve Alan
Karmaşıklığı
Bir veri yapısının performansını incelerken, en önemli üç konu
vardır:
Doğruluk: Veri yapısı doğru şekilde arayüzünü uygulamalıdır.
Zaman karmaşıklığı: Veri yapısı üzerindeki işlemlerin çalışma
süreleri mümkün olduğunca küçük olmalıdır.
Alan karmaşıklığı: Veri yapısı mümkün olduğunca az bellek kullanmalıdır.
Bu giriş bölümünde, doğruluk veriliyor kabul edeceğiz; sorgulara
hatalı yanıtlar veren veya düzgün güncelleme yapmayan veri yapılarını dikkate almayacağız. Ancak, en az alan kullanımını çalıştırmak için ekstra bir çaba gösteren veri yapılarını göreceksiniz. Bu,
genellikle işlemlerin (asimptotik) yürütme sürelerini etkilemez,
ancak pratikte veri yapılarını biraz daha yavaşlatabilir.
Veri yapılarının çalışma sürelerini incelerken, üç farklı tür çalışma
zamanı eğilimi ile karşılaşırız:
En-kötü durum çalışma zamanı: Bunlar çalışma zamanı garantilerinin en güçlü türüdür. Veri yapısı f(n) en-kötü durum çalışma
50|
zamanıne sahipse, o zaman her bir işlemin çalışma zamanı f(n)’den
asla daha uzun zaman almaz.
Amortize çalışma zamanı: Veri yapısı içindeki bir işlemin
amortize çalışma zamanının f(n) olduğunu söylemek demek, tipik
bir işlem maliyetinin en fazla f(n) olduğu anlamına gelir. Daha kesin olarak, bir veri yapısı f(n) amortize çalışma zamanına sahipse,
bir dizi m işlemi en fazla m f(n) zamanda çalışır. Bazı işlemler bireysel olarak f(n)’den daha fazla sürebilir, ancak işlemlerin bütün
dizisi için, ortalama, en fazla f(n)’dir.
Beklenen çalışma zamanı: Veri yapısı üzerinde bir işlemin beklenen çalışma zamanınin f(n) olduğunu söylediğimizde, bu gerçek
çalışma zamanının bir rasgele değişken (bkz. Rasgele Sıralama ve
Olasılık Bölümü) olduğu ve bu rasgele değişkenin beklenen değerinin en fazla f(n) olduğu anlamına gelir. Buradaki rasgelelik veri
yapısı tarafından yapılan rasgele seçimler ile ilgilidir.
En-kötü durum, amortize ve beklenen çalışma zamanları arasındaki
farkı anlamak için bir mali örneği düşünmek yardımcı olarak hesaplanır. Bir ev satın alma maliyetini düşünün:
En-kötü durum’a karşılık amortize maliyet:
Bir ev maliyetinin
120.000$ olduğunu varsayalım. Bu evi satın almak için, 1.200$
aylık ödemeler ile 120 aylık (10 yıl) ipotek alabiliriz. Bu durumda,
bu ipoteğin ödeme maliyeti en-kötü durumda aylık 1.200$ olarak
hesaplanır.
| 51
Elimizde yeterli para varsa, 120.000$ bir ödeme ile evi doğrudan
satın almayı seçebiliriz. Bu durumda, 10 yıllık bir süre içinde, bu
evi satın almanın amortize edilmiş aylık maliyeti
120.000$ / 120 ay = 1.000$ aylık .
Bunun anlamı, eğer ipoteği ödemek zorunda kalsaydık ayda
1.200$’dan daha azdır.
En-kötü
durum’a
karşılık
beklenen
maliyet:
Şimdi, bizim
120.000$ ’lık evimizde, yangın sigortası sorununu dikkate alalım.
Yüzbinlerce olayı inceleyen sigorta şirketleri, bizimki gibi bir evde
beklenen aylık yangın hasar miktarının 10$ olduğunu belirlediler.
Bu çok küçük bir sayıdır, çünkü pek çok evde asla yangın çıkmaz,
birkaç evde biraz duman hasarı yaratan bazı küçük yangınlar olabilir, ve evlerin pek azı büyük yangın geçirir. Bu bilgilere dayanarak,
sigorta şirketi yangın sigortası için 15$ aylık ücret talep eder.
Şimdi karar zamanı. Yangın sigortası için en-kötü durumda 15$
aylık maliyeti ödemeli miyiz, veya risk alıp ayda 10$ beklenen maliyet pahasına kendi kendimizi sigortalamamız mı gerekir? Açıkçası, beklentide aylık 10$ daha az masraf yapıyor, ama biz gerçek
maliyetin çok daha yüksek olabileceği olasılığını kabul etmek zorundayız. Bütün evin yanması olası durumunda, gerçek maliyet 120.000$ olacaktır.
52|
Bu finansal örnekler neden bazen en-kötü durumda çalışan zaman
yerine amortize edilmiş veya beklenen çalışma zamanı ile yetindiğimize dair bize ışık tutuyor. Çoğunlukla en-kötü zamandan daha
düşük bir beklenen veya amortize zaman elde etmek mümkündür.
En azından, amortize veya beklenen çalışma süreleriyle yetinmeye
istekli bir kimsenin çok daha basit bir veri yapısı elde etmesi çoğu
kez mümkündür.
| 53
Kod Örnekleri
Bu kitaptaki kod örnekleri, Java programlama dilinde yazılmıştır.
Ancak, Java'nın yapıları ve anahtar sözcüklerinin tümüne aşina
olmayan okuyuculara kitabı erişilebilir hale getirmek için, kod örnekleri basitleştirilmiştir. Örneğin, bir okuyucu, public, protected,
private
veya static gibi anahtar sözcüklerden hiçbirini bulamaya-
caktır. Okuyucu, aynı zamanda sınıf hiyerarşileri hakkında da fazla
tartışma bulamayacaktır. Belirli bir sınıfın hangi arayüzleri uyguladığı veya hangi sınıfı genişlettiği, eğer tartışma ile ilgiliyse, ilişikteki metinden açık olmalıdır. Böylece, B, C, C++, C#, Objective-C,
D, Java, JavaScript dahil, ALGOL geleneğinden gelen herhangi bir
dilin birikimine sahip olan herkes tarafından kod örnekleri anlaşılabilir hale gelmiştir. Tüm uygulamaların bütün ayrıntılarını isteyen
okuyucular, bu kitaba eşlik eden Java kaynak koduna bakabilir.
Bu kitapta analiz edilen algoritmalar için çalışma zamanlarının matematiksel analizleri ile Java kaynak kodu karışık halde bulunmaktadır. Bunun anlamı, bazı denklemler kaynak kodunda da bulunan
değişkenleri içermektedir. Bu değişkenler, hem kaynak kodu içinde
ve hem denklem içinde sürekli görünür. Bu tür değişkenlerin en
çok kullanılanı, istisnasız olarak, her veri yapısında depolanan eleman sayısına karşılık gelen n’dir.
54|
Veri Yapıları Listesi
Tablo 1.1 ve 1.2, bu kitapta Arayüzler Bölümü'nde anlatılan Liste,
UKüme
ve SKüme arayüzlerini gerçekleştiren veri yapılarının per-
formansını özetliyor.
| 55
56|
Tartışma ve Alıştırmalar
Arayüzler Bölümü’nde açıklanan Liste, UKüme ve SKüme
arayüzleri Java Koleksiyonları Çerçevesi [54] tarafından etkilenmiştir. Bunlar Java Koleksiyonlar Çerçevesinde bulunan List, Set,
Map, SortedSet
ve SortedMap arayüzlerinin esas olarak basitleşti-
rilmiş versiyonlarıdır. İlişikteki kaynak kod, Set, Map, SortedSet
ve SortedMap uygulamaları içine UKüme ve SKüme uygulamalarını yerleştirmek için gerekli sarmalayıcı sınıfları içerir.
Bu bölümde tartışılan matematik, asimptotik gösterim, logaritma,
faktöriyel, Stirling yaklaşımı, temel olasılık ve daha fazlası dahil
olmak üzere mükemmel (ve serbest) bir şekilde Leyman, Leighton,
ve Meyer [50] tarafından ele alınmıştır. Üssel ve logaritmaların
biçimsel tanımlarını içeren ılımlı bir hesap kitabı için ise,
Thompson [73] tarafından kaleme alınmış (serbestçe kullanılabilir)
klasik kitaba başvurunuz.
Özellikle bilgisayar bilimleri ile ilgili olarak temel olasılık hakkında daha fazla bilgi için, Ross [65] tarafından yazılmış ders kitabına
bakmanız önerilir. Asimptotik gösterim ve olasılığı kapsayan bir
başka iyi referans da, Graham, Knuth ve Patashnik tarafından yazılan ders kitabıdır [37].
Kendi Java programlamalarını gözden geçirmek isteyen okuyucular
etkileşimli pek çok Java eğitimlerini bulabilirler [56].
| 57
Alıştırma 1.1. Bu alıştırma, doğru problem için doğru veri yapısı
seçimini okuyucuya tanıtmaya yardımcı olmak için tasarlanmıştır.
Gerçekleştirilirse, bu alıştırmanın bölümleri Java Koleksiyonları
Çerçevesi tarafından sağlanan ilgili arayüzün (Yığıt, Kuyruk, İki
Başlı Kuyruk, UKüme
veya SKüme) bir uygulamasından yararlana-
rak yapılmalıdır.
Aşağıdaki problemleri bir metin dosyasını her seferde bir satır okuyarak, ve her satır için işlemleri uygun veri yapı(ları) içinde gerçekleştirerek çözün. Uygulamalarınız, bir milyon satır içeren dosyaları
bile birkaç saniye içinde işleyebilecek kadar hızlı olmalıdır.
1.
Girdiyi bir seferde bir satır olmak üzere okuyun ve daha sonra
ters sırayla satırları yazın. Son giriş satırı ilk olarak yazılacaktır;
daha sonra sondan ikinci giriş satırı yazılacaktır, vb.
2.
Girdinin ilk 50 satırını okuyun ve daha sonra bunları ters sıray-
la yazın. Sonraki 50 satırı okuyun ve daha sonra ters sırayla bunları
yazın. Bunu okumak için artık satır kalmayana dek devam ettirin.
Bu noktada kalan satırlar ters sırayla çıktıya yazılmalıdır. Diğer bir
deyişle, çıktınız ilk satırda 50. satır, sonra 49. satır, sonra 48.satır
ile başlayacak ve bu böyle 1. satıra kadar devam edecektir. Bunu
takiben, 100.satır, sonra 99. satır yazılacak ve bu böyle 51. satıra
kadar devam edecektir, vb. Kodunuz, herhangi bir zamanda, asla 50
satırdan fazla depolamak zorunda değildir.
3.
Her seferde bir girdi satırı okuyun. İlk 42 satırı okuduktan son-
ra herhangi bir noktada, eğer bazı satırlar boşsa (yani, 0 uzunlu-
58|
ğunda bir dize) ondan 42 satır öncesindeki satırı çıktı olarak yazın.
Örneğin 242. satır boş ise, programın çıktısı 200.satır olmalıdır. Bu
program, herhangi bir zamanda, 43 satırdan fazla girdi depolamayacak şekilde uygulanmalıdır.
4.
Her seferde bir girdi satırı okuyun ve her satırı, önceki giriş
satırlarında yinelenmediyse çıktıya yazın. Çok fazla yinelenen satır
içeren bir dosyanın tekil satır sayısı için gerekli olandan daha fazla
bellek kullanmaması gerektiğine özellikle dikkat edin.
5.
Her seferde bir girdi satırı okuyun ve bu satırı daha önce zaten
okuduysanız çıktıya yazın (sonuçta, her satır ilk geçtiği yerden silinecektir). Çok fazla yinelenen satır içeren bir dosyanın tekil satır
sayısı için gerekli olandan daha fazla bellek kullanmaması gerektiğine özellikle dikkat edin.
6.
Tüm girdiyi, her seferde bir satır olacak şekilde okuyun. Sonra,
uzunluğuna göre sıralanmış tüm satırları, kısa satırlar önce olmak
üzere çıktıya yazın. İki satırın aynı uzunluğa sahip olması durumunda, her zamanki “sıralama ölçütünü” kullanarak sıralarını çözümleyin. Yinelenen satırlar sadece bir kez yazılmalıdır.
7.
Önceki soruda istenenin aynısını yapın; yalnız bu sefer yinele-
nen satırlar, girdide göründükleri satır sayısı kadar çıktıda yazılmış
olmalıdır.
8.
Her seferde bir girdi satırı okuyun ve çift sayılı satırları (0.
satır ile başlayan ilk satır ile) çıktıya yazın; daha sonra tek sayılı
satırları yazın.
9.
Tüm girdiyi her seferde bir satır olacak şekilde okuyun ve sa-
tırları çıktıya yazmadan önce rasgele permütasyon yapın. Anlaşılır
olmak gerekirse, herhangi bir satırın içeriğini değiştirmemeniz ge-
| 59
rekir. Bunun yerine, aynı satır topluluğunu yazdırmalısınız, ancak
rasgele sırayla yapılmalıdır.
Alıştırma 1.2. Dyck sözcüğü, +1 ve 1’lerden oluşur ve dizinin
herhangi bir önek toplamının negatif olmaması şartı aranır. Örneğin
+1, 1, +1, 1 Dyck sözcüğüdür, ancak +1, 1, 1, +1 değildir,
çünkü önek +1 1 – 1 0. Dyck sözcüğü ve Yığıt işlemlerinden
yığ(x)
ve sil() arasındaki herhangi bir ilişkiyi açıklayın.
Alıştırma 1.3. Uyumlu dize, düzgün eşleştirilen {, },(, ),[, ] karakterlerinden oluşan bir dizedir. Örneğin, “{{()[]}}” bir uyumlu dizedir, ancak “{{()]}” değildir, çünkü ikinci { eşleşmesi ] ile olmuştur.
n
uzunluğunda bir dize verildiğinde, bunun uyumlu dize olup ol-
madığını kontrol etmek için O(n) zamanında çalışan bir yığıttan
nasıl faydalanılabileceğini gösterin.
Alıştırma 1.4. Sadece yığ(x) ve sil() işlemlerini destekleyen bir
Yığıt, s,
olduğunu varsayalım. Sadece bir FIFO Kuyruk, q, kullana-
rak nasıl tüm elemanların sırasını tersine çevirebileceğinizi gösterin.
Alıştırma 1.5. Bir UKüme kullanarak, Torba arayüzünü uygulayınız. Torba, UKüme gibidir ekle(x), sil(x) ve bul(x) işlemlerini
destekler ancak, yinelenen elemanların depolanmasını da sağlar.
Torba’daki bul(x)
işlemi, herhangi x elemanı (varsa) döndürür.
Buna ek olarak, Torba, x’e eşit olan tüm elemanların bir listesini
döndüren hepsiniBul(x) işlemini destekler.
60|
Alıştırma 1.6. Liste, UKüme ve SKüme arayüzlerinin uygulamalarını sıfırdan yazın ve test edin. Bunların verimli olması gerekmez
(bunu yapmanın en kolay yolu, elemanları bir dizide depolamaktır).
Bu uygulamaları, daha verimli olanların doğruluğunu ve performansını test etmek için daha sonra kullanabilirsiniz.
Alıştırma 1.7. Önceki alıştırmada yazdığınız uygulamaların performansını artırmak için, aklınıza gelebilecek herhangi bir püf noktasını kullanarak çalışın. Liste uygulamasında, ekle(i, x) ve sil(i)
işlemlerinin performansını nasıl artıracağınızı düşünün ve deneyin.
UKüme
ve SKüme uygulamalarında bul(x, i) işleminin performan-
sını artırmayı düşünün. Bu alıştırma, size, bu arayüzlerin verimli
uygulamalarını elde etmenin ne kadar zor olabileceğine dair fikir
vermek için tasarlanmıştır.
| 61
Bölüm 2
Dizi-Tabanlı Listeler
Bu bölümde, Liste ve Kuyruk arayüzü uygulamalarını öğreneceğiz.
Bu uygulamaların belli başlı verileri, takviye dizi adı verilen bir
dizide depolanmıştır. Bu bölümde sunulan veri yapılarının temel
işlemleri aşağıdaki tabloda verilen çalışma zamanlarıyla özetlenmiştir:
Sadece bir tek diziye veri depolayan veri yapıları için birçok avantaj ve sınırlamalar bulunmaktadır:
Herhangi bir değere sabit zamanlı erişim sunmak için diziler
yeterlidir. al(i) ve belirle(, x) işlemleri sabit zamanda çalışır.
Dinamik olma özelliği aranmadığı için, dizinin ortasına yakın
bir konumuna eleman eklenmesi veya silinmesi, çok sayıda kaydırma hareketinin hesaplanmasına neden olur. Dizinin alan boşluğunu iyi değerlendirmek için, çok sayıda elemanın yeni eklenen
elemana yer açması veya silinen eleman tarafından yaratılan boşlu-
62|
ğu doldurması gerekir. Bu nedenle ekle(i, x) ve sil(i) işlemlerinin
çalışma süreleri, n ve i’ye bağlıdır.
Dizileri genişletmek veya küçültmek çoğu zaman mümkün
değildir. Veri yapısında bulunan eleman sayısı, takviye dizinin boyutunu aşarsa, yeni bir dizinin tahsis edilmesi ve eski diziye ait
verilerin yeni diziye kopyalanması gerekir. Bunu gerçekleştirmek
pahalı bir işlemdir.
Üçüncü nokta önemlidir. Yukarıdaki tabloda belirttiğimiz çalışma
süreleri içinde, takviye dizinin büyümesi ve küçülmesi ile ilişkili
maliyetleri dahil etmedik. Ancak dikkatli uygulandığı takdirde,
takviye dizinin büyümesi ve küçülmesiyle birlikte gelen maliyetin,
ortalama bir işlem maliyetinden fazla olmadığını görürüz. Daha
doğrusu, boş bir veri yapısı ile başladığınızda, herhangi bir sırada m
adet ekle(i, x) ve sil(i) işlemi çalıştırılırsa, takviye diziyi büyültüp,
küçültmenin tüm bu m işlem sırasındaki maliyeti O(m) olarak hesaplanır. Birbirinden ayrı bazı işlemler daha pahalı olmasına rağmen, m adet işlemin tümü üstünden amortize maliyet hesaplandığı
takdirde, her işlem için sadece O(1) çalışma zamanı vardır.
| 63
Dizi Yığıtı: Dizi Kullanan Hızlı Yığıt
İşlemleri
Dizi Yığıtı,
liste arayüzünü, a, takviye dizisini kullanarak uygulama-
ya koymuştur. i konumunda bulunan liste elemanı a[i] içinde depolanmaktadır. Çoğu zaman, a boyutunu tam olarak gerekli olduğundan daha büyük olarak belirleyebiliriz, bu nedenle, a dizisinde herhangi bir anda depolanan elemanların sayısını tutan n tamsayısını
kullanırız. Listenin elemanları a[0],…,a[n-1] içinde depolanmışken, her zaman için a.boyut n koşulu geçerlidir.
64|
Temel Bilgiler
Dizi Yığıtı
le(i, x)
elemanlarına erişmek ve değiştirmek için al(i) ve belir-
işlemlerini gerçekleştiririz; bu kolay anlaşılırdır. Gerekli
sınır denetimini yaptıktan sonra geriye sadece, sırasıyla, a[i] değeri
döndürmek veya değiştirmek kalır.
Dizi Yığıtı’na
eleman ekleme ve kaldırma işlemlerinin örnek çalış-
tırmaları Şekil 2.1’de gösterilmiştir. ekle(i, x) işlemini gerçekleştirmek için, ilk olarak, a dizisinin halen dolu olup olmadığını kontrol ederiz. Eğer öyleyse, a’nın boyutunu artırmak için yeniden_boyutlandır()
işlemini çağırırız. yeniden_boyutlandır() işle-
minin nasıl gerçekleştirildiğini daha sonra ele alacağız. Şimdilik,
yeniden_boyutlandır()
emin
olmak
çağrısından sonra, a.boyut > n olduğundan
yeterlidir.
Bu
arada,
x’e
yer
açmak
için
elemanlarını bir konum sağa kaydırıyoruz, sonra
a[i]
elemanını x değerine eşitliyoruz ve n değerini 1 artırıyoruz.
| 65
yeniden_boyutlandır()
işlemi için yapılan potansiyel çağrı maliyeti
önemsenmediği takdirde, ekle(i, x) işleminin maliyeti, x’e yer açmak için kaydırılması gereken eleman sayısı ile orantılıdır. Bu nedenle, kaydırma hareketlerinin çalışma maliyeti (boyutlandırma
maliyeti önemsenmediği takdirde), O(n – i + 1) olarak hesaplanır.
sil(i)
işlemini uygulamak benzer şekilde gerçekleşir.
elemanlarını bir konum sola kaydırırız (a[i]
üzerine yazarak), ve n değerini 1 azaltırız. Sonra, a.length
3n
koşulunu test ederek, n değerinin a.length uzunluğundan azımsanmayacak kadar küçük olup olmadığını kontrol ediyoruz. Eğer öyleyse, a’nın boyutunu azaltmak için yeniden_boyutlandır() işlemini çağırıyoruz.
66|
yeniden_boyutlandır()
sil(i)
işleminin maliyeti önemsenmediği takdirde,
işleminin çalışma maliyeti, kaydırılan elemanların sayısı ile
orantılı, O(n
i)
olarak hesaplanır.
| 67
Büyültme ve Küçültme
yeniden_boyutlandır()
işlemi yeterince anlaşılırdır; boyutu 2n olan
yeni bir b dizisi tahsis eder, b’nin ilk n pozisyonuna n elemanı
kopyalar, ve daha sonra a’yı b’ye belirler. Böylece bir yeniden_boyutlandır()
çağrısından sonra a.length=2n olarak hesap-
lanır.
yeniden_boyutlandır()
işleminin gerçek maliyetini analiz etmek
kolaydır. 2n boyutuna sahip olan, b dizisini bellekten tahsis eder,
ve n elemanı b içine kopyalar. O(n) çalışma zamanı vardır.
Önceki bölümde yaptığımız çalışma zamanı analizinde, yeniden
boyutlandırmak için yapılan çağrıların maliyetini önemsememiştik.
Amortize analiz diye bilinen bir tekniği kullanarak maliyet analizine devam edeceğiz. Bu teknik, her ekle(i, x) ve sil(i) işlemi sırasında gerçekleştirilen yeniden boyutlandırma maliyetini hesaplamaz. ekle(i, x) ve sil (i) işlemlerinin m defa çağrılması sırasında,
yeniden boyutlandırmak için yapılan tüm çağrıların maliyetini çözer. Bu bölümde özellikle şunu göstereceğiz:
68|
Öneri 2.1: Başlangıçta Dizi Liste elemanları boş iken, ekle(i, x) ve
sil(i)
işlemleri sıralı olarak m
den_boyutlandır()
1 defa çağrılırsa, o zaman yeni-
için yapılan tüm çağrılar sırasında harcanan
toplam zaman O(m) olarak hesaplanır.
Kanıt: yeniden_boyutlandır() işlemi her çağrıldığında, son çağrıdan bu yana gerçekleştirilen ekle veya sil işlem sayısının en az n/2-1
olduğunu göstereceğiz. Bu nedenle, yeniden_boyutlandır() için
yapılan i'inci çağrı sırasındaki n değeri ni ile, ve yeniden_boyutlandır()
toplam çağrı sayısı r ile gösterilirse, ekle(i, x)
veya sil(i) için yapılan toplam çağrı sayısı en az,
olarak yazılır, ve şuna eşittir:
Öte yandan, yeniden_boyutlandır() için yapılan tüm aramalar sırasında harcanan toplam zaman, r değeri m’den fazla olmadığından,
olarak belirlenir. Geriye kalan tek yapmamız gereken, yeniden_boyutlandır()
için gerçekleştirilen (i – 1)’inci ve i’inci arama-
| 69
lar arasında yapılan ekle(i, x) veya sil(i) çağrı sayısının en az ni / 2
olduğunu göstermektir.
Dikkate alınması gereken iki durum vardır. Birinci durumda, takviye dizisi, a, dolu olduğundan ekle(i, x) tarafından yeniden_boyutlandır()
çağrılıyor. Bu durumda, a.length
n
ni
ol-
muştur. Yeniden boyutlandırmak için yapılan bir önceki çağrıyı
düşünün: Bir önceki çağrıdan sonra, a’nın uzunluğu a.length, ve a
içinde depolanmış elemanların sayısı en fazla a.length/2 = ni /2
olarak hesaplanır. Fakat şimdi, a, içinde depolanmış elemanların
sayısı ni = a.length olup, bir önceki yeniden_boyutlandır() çağrısından bu yana, ekle(i, x) işlemi için en az ni /2 çağrı yapılmıştır.
İkinci durumda, yeniden_boyutlandır() çağrısı, sil(i) tarafından
yapılmıştır, bu durumda a.length
3n = 3ni
olduğunu düşünme-
liyiz. Yeniden boyutlandırmak için yapılan bir önceki çağrıdan sonra, a içinde depolanmış elemanların sayısı en az a.length/2
olmuştur.
ni
Şu
anda,
a.length/3
a
içinde
depolanmış
eleman
1
sayısı
kadar olduğu için, yeniden boyutlandırmak için
yapılan en son çağrıdan bu yana, gerekli sil(i) işlem sayısı en az
olarak,
70|
Her
iki
durumda
da,
yeniden_boyutlandır()
için
yapılan
(i – 1)’inci ve i’inci aramalar sırasında ekle(i, x), veya sil(i) için
yapılan çağrı sayısı en az ni / 2
1 olmuştur.
| 71
Özet
Aşağıdaki teorem Dizi Yığıt’ının performansını özetlemektedir:
Teorem
2.1.
Dizi
den_boyutlandır()
Yığıt,
Liste
arayüzünü
uygular.
yeni-
için yapılan işlem çağrısının maliyeti önem-
senmediği takdirde, Dizi Yığıt şu işlemleri destekler:
al(i)
ekle(i, x)
ve belirle(i, x) işlem başına O(1) zamanda çalışır,
ve sil(i) işlem başına O(1 + n - i) zamanda çalışır.
Başlangıçta, Dizi Yığıt elemanları boş değer taşırken, ve
ekle(i, x)
ve sil(i) işlemleri sıralı olarak m defa çağrılırsa, yeni-
den_boyutlandır()
işlemi için yapılan tüm çağrılar O(m) toplam
zamanda çalışır.
Dizi Yığıt
uygulaması, Yığıt arayüzünü gerçekleştirmek için etkili
bir yoldur. Özellikle, yığ(x) işlemini ekle(n, x) çağrısı ile gerçekleştirebiliriz. sil(x) işlemini gerçekleştirmek için sil(n - 1) çağrısı
yaparız. Bu işlemler, O(1) amortize zamanda çalışır.
72|
Hızlı Dizi Yığıtı: Optimize Dizi Yığıtı
Dizi Yığıtı
tarafından yerine getirilen görevlerin çoğu, veri karşılaş-
tırmak (ekle(n, x) ve sil(x) tarafından gerçekleşir) ve kopyalamaktır (yeniden_boyutlandır() tarafından gerçekleşir). Yukarıda gösterilen uygulamalarda, for döngüleri içinde bunu uyguladık. Oysa ki,
birçok programlama ortamlarının veri bloklarını kopyalama ve taşıma konusunda çok verimli olan özel işlevlere sahip olduğu ortaya
çıkmıştır.
C
programlama
memmove(d, s, n)
a1, b)
dilinde
memcpy(d,
s,
n)
ve
fonksiyonları vardır. C++ içinde std::copy(a0,
algoritması vardır. Java’da System:arraycopy (s, i, d, j, n)
metotu vardır.
| 73
Bu fonksiyonlar genellikle oldukça optimize edilmiştir ve hatta for
döngüsü kullanarak yapabileceğimiz kopyalamadan çok daha hızlı
özel makine komutlarını kullanır. Bu işlevleri kullanarak asimptotik çalışma saatlerini azaltmak mümkün olmasa da, hala değerli
birer optimizasyon sayılabilir. Buradaki Java uygulamalarında,
System.arraycopy(s, i, d, j, n)
çağrısıyla, işlem türüne bağlı ola-
rak 2 ila 3 faktör arasındaki hız artışları kaydedilmiştir. Sizin ölçümleriniz değişiklik gösterebilir.
74|
Dizi Kuyruğu: Dizi-Tabanlı Kuyruk
Bu bölümde, FIFO (ilk-giren-ilk-çıkar) Kuyruğu’nu uygulayan Dizi
Kuyruğu
veri yapısını sunacağız. Elemanlar (ekle() işlemi ile ger-
çekleşen), eklendikleri sırada silinir (silme işlemi sil() çağrısı ile
gerçekleşir).
Dizi Kuyruğu’nun, FIFO Kuyruğu’nu
uygulamak için kötü bir se-
çim olduğuna dikkat edin. İyi bir seçim değildir, çünkü elemanları
eklemek için, önce listenin bir ucunu seçmeliyiz ve daha sonra listenin diğer ucundan elemanları silmeliyiz. İki işlemden birinin listenin başında, i = 0 değerindeyken, çalışması gereklidir. Ekle(x, i)
veya sil(i) işlemi için yapılan çağrının çalışma zamanı, eleman sayısı, n ile orantılıdır.
Dizi-tabanlı uygulamadan verim elde etmek için öncelikle sonsuz
bir, a, dizisi olsaydı, sorun kolaylıkla çözülebilirdi. j endeksi bir
sonraki silinecek elemanın konumunu, ve n tamsayısı kuyruktaki
eleman sayısını tutsun. Kuyruk elemanları, her zaman için şu konumlarda bulunacaktır:
Başlangıçta, j endeksi ve n tamsayısı da 0 ile başlamıştır. Bir elemanı eklemek için a[j + n] konumuna yerleştiririz, ve n değerini 1
| 75
artırırız. Bir elemanı silmek için, a[j] konumundan kaldırırız, j değerini 1 artırırız, ve n değerini 1 azaltırız.
Tabii ki, bu çözümdeki sorun, sonsuz bir dizi gerektirmesidir. Dizi
Yığıtı
sonlu bir, a, dizisini ve modüler aritmetik kullanarak, bu çö-
züm yoluna benzetim yapar. Günün zamanı hakkında konuştuğumuzda kullandığımız aritmetik türü modüler aritmetiktir. Örneğin,
saat 10:00’dan başlayarak beş saat ileri gittiğinizde saat 03:00 elde
edilir. Biçimsel olarak demek istiyoruz ki,
Bu denklemin ikinci bölümü “15 modülo 12 denktir 3” şeklinde
okunur. İkili işleç mod olarak da ele alınabilir; şöyle ki,
Daha genel olarak, bir a tamsayısı ve pozitif bir m tamsayısı için, a
mod m benzersiz bir r tamsayısına denktir, öyle ki
ve herhangi bir k tamsayısı için a = r + km eşitliği sağlanmalıdır.
Daha az biçimsel olarak hesaplarsak, r değeri a, m’e bölündüğünde
ortaya çıkan kalandır. Java gibi birçok programlama dilinde, mod
işleci % simgesi ile gösterilir.
Modüler aritmetik sonsuz bir diziye benzetim yapmak için yararlıdır, çünkü i mod a.length her zaman 0,…,a.length
1
aralığında
76|
bir değer verir. Modüler aritmetik kullanarak kuyruk elemanlarını
aşağıdaki dizi konumlarında depolayabiliriz:
Burada a dizisi bir dairesel dizi gibi değerlendirilmiştir. a.length 1’den
daha büyük olan dizi endeksleri, dizinin başlangıcına doğru
"sarar".
Endişelenmesi ve dikkat edilmesi gereken tek şart, Dizi Kuyruk
içinde bulunan eleman sayısı, takviye dizisi olan a’nın boyutunu
aşmamalıdır.
Dizi Kuyruk
işlemlerinden ekle(x) ve sil() çalıştırmaları için birer
örnek Şekil 2.2'de gösterilmiştir. ekle(x) işlemini gerçekleştirmek
için, öncelikle a’nın dolu olup olmadığını kontrol ederiz, ve gerekirse, a’nın boyutunu artırmak için yeniden_boyutlandır() işlem
çağrısı yaparız. a[(j + n) % a.length] konumunda x değerini belirledikten sonra, n değerini 1 artırırız.
| 77
sil()
işlemini gerçekleştirmek için öncelikle, a[j] elemanına daha
sonra geri dönmek üzere, yedeğini alırız. n değerini 1 azaltırız ve j
= (j + 1) mod a.length
belirlemesiyle, j mod (a.length) değerini
1 artırırız. a[j] konumunda önceden depolamış olduğumuz değeri
işlem sonucu olarak döndürürüz, ve gerekiyorsa, a boyutunu azaltmak için yeniden_boyutlandır() işlemini çağırırız.
Son olarak, yeniden_boyutlandır() işlemi Dizi Yığıt içinde çalışan
yeniden boyutlandırmaya çok benzer. Boyutu 2n olan, yeni bir b
dizisi tahsis eder, ve aşağıdaki elemanları,
78|
yeni dizi elemanlarının üzerine yazar:
ve j = 0 olarak belirler.
| 79
Özet
Aşağıdaki teorem Dizi Kuyruk veri yapısının performansını özetlemektedir:
Teorem 2.2. Dizi Kuyruk veri yapısı, (FIFO) Kuyruk arayüzünü
uygular. yeniden_boyutlandır() için yapılan işlem çağrısı maliyeti
önemsenmediği takdirde, Dizi Kuyruk işlemlerinden ekle(x) ve sil()
O(1) zamanda çalışır. Başlangıçta, Dizi Kuyruk elemanları boş
değer taşırken, ekle (i, x) ve sil (i) işlemleri sıralı olarak m defa
çağrılırsa, yeniden_boyutlandır() işlemi için yapılan tüm çağrılar,
O(m) toplam zamanda çalışır.
80|
Dizi İki Başlı Kuyruk: Dizi Kullanan Hızlı
İki Başlı Kuyruk
Daha önceki bölümde gördüğümüz Dizi Kuyruk, dizinin bir ucuna
ekleyen ve diğer ucundan silen Kuyruk veri yapısıdır. Dizi İki Başlı
Kuyruk,
her iki uca da verimli şekilde ekler veya siler. Liste
arayüzünün bir uygulaması olan Dizi Kuyruk’ta kullanılan dairesel
dizi tekniğinin aynısını kullanır.
Dizi İki Başlı Kuyruk
işlemlerinden al(i) ve belirle(i, x) işlemlerini
gerçekleştirmeyi kolayca anlayabilirsiniz. Dizinin a[(j + i) mod
a.length]
konumunda bulunan elemanını getirir veya o değeri be-
lirler.
ekle(i, x)
uygulaması biraz daha ilginçtir. Her zamanki gibi, a’nın
dolu olup olmadığını kontrol ediyoruz, ve gerekirse, a’yı yeniden
boyutlandırmak için yeniden_boyutlandır() işlem çağrısı yapıyo-
| 81
ruz. Önemli olan gereksinim, i değeri küçük (0’a yakın) olduğunda
veya büyük (n’e yakın) olduğunda, bu işlemin hızlı olması şartıdır.
Bunu gerçekleştirmek için önce, i < n/2 koşulunu kontrol ediyoruz.
Eğer öyleyse, a[0],…,a[i - 1] elemanlarını 1 konum sola doğru
kaydırıyoruz. Değilse, (i
n/2)
iken, a[i],…,a[n - 1] elemanlarını
1 konum sağa doğru kaydırıyoruz. Dizi İki Başlı Kuyruk işlemlerinden ekle(i, x) ve sil (i) çalıştırmalarına birer örnek için bkz. Şekil
2.3.
82|
ekle(i, x)
min(i, n
işlemi sırasında gerçekleşen kaydırma hareketi sayısı,
- i) elemandan fazla olamaz. Bundan emin olduğumuz
için, ekle(i,x) işleminin çalışma zamanı (yeniden_boyutlandır()
işleminin maliyeti önemsenmediği takdirde),
olarak hesaplanır.
sil(i)
işleminin uygulaması benzer şekildedir. i < n/2 koşuluna bağlı
olarak, a[0],…,a[i
1]
elemanlarını 1 konum sağa doğru kaydır-
mamız gerekir. Koşul sağlanmazsa, a[i + 1],…,a[n
1]
elemanla-
rını sola doğru 1 konum kaydırırız. sil(i) işlemi sırasında gerçekleşen kaydırma
hareketi
sayısı,
bu nedenle
elemandan fazla olamaz.
hiçbir zaman,
| 83
Özet
Aşağıdaki teorem Dizi İki Başlı Kuyruk veri yapısının performansını özetlemektedir:
Teorem 2.3. Dizi İki Başlı Kuyruk veri yapısı, Liste arayüzünü uygular. yeniden_boyutlandır() için yapılan işlem çağrısı maliyeti
önemsenmediği takdirde, Dizi İki Başlı Kuyruk, aşağıdaki işlemleri
destekler:
al(i)
ekle(i, x)
ve belirle(i, x), işlem başına O(1) zamanda çalışır,
ve sil(i), işlem başına
zaman-
da çalışır.
Başlangıçta, Dizi İki Başlı Kuyruk elemanları boş değer taşırken,
ekle(i, x)
ve sil(i) işlemleri sıralı olarak m defa çağrılırsa, yeni-
den_boyutlandır()
zamanda çalışır.
işlemi için yapılan tüm çağrılar, O(m) toplam
84|
Çifte Dizi İki Başlı Kuyruk: İki Yığıt’tan İki Başlı
Kuyruk Oluşturulması
Bu bölümde, Dizi İki Başlı Kuyruk ile aynı performans sınırını sağlayan, ve iki adet Dizi Yığıt kullandığı için Çifte Dizi İki Başlı Kuyruk
adı verilen bir veri yapısını anlatacağız. Çifte Dizi İki Başlı
Kuyruk’un
asimptotik performansı, Dizi İki Başlı Kuyruk’tan daha
iyi değildir, ancak hala üzerinde düşünmeye ve incelemeye değerdir, çünkü iki basit veri yapısını birleştirerek, nasıl daha gelişmiş
bir veri yapısının elde edilebileceğine dair iyi bir örnek sunuyor.
Çifte Dizi İki Başlı Kuyruk
veri yapısı, iki tane Dizi Yığıt listesi kul-
lanıyor. Dizi Yığıt, elemanlarını değiştirirken, listenin uç konumlarında daha hızlı performans gösteriyor. Çifte Dizi İki Başlı Kuyruk,
front
ve back adlarında karşılıklı birer Dizi Yığıt’ı bünyesinde ba-
rındırırken, her iki uçta da işlemleri daha hızlı hale getirir.
Çifte Dizi İki Başlı Kuyruk’ta
bulunan eleman sayısı, n, açık şekilde
belirtilmemiştir. Buna gerek yoktur, çünkü
back.boyut()
ruk’u
n = front.boyut() +
ile hesaplanmıştır. Yine de, Çifte Dizi İki Başlı Kuy-
analiz ederken, n değişkenini kullanmaya devam edeceğiz.
| 85
front Dizi Yığıtı,
endeksleri 0,…,front.boyut()
1
olan liste ele-
manlarını ters sırada depolarken, back Dizi Yığıtı, endeksleri
front.boyut(),…,boyut()
- 1 olan liste elemanlarını normal sırada
depolar. Bu şekilde, al(i) ve belirle(i, x) işlemleri, front veya back
için karşılık gelen uygun al(i) ve belirle(i, x) işlem çağrılarına tercüme edilir ve işlem başına O(1) zamanda çalışır.
86|
i < front.boyut()
koşulunu sağlayan, i endeksindeki herhangi bir
eleman, front.boyut() - i - 1 konumunda, ve front yığıtında depolanır, çünkü front yığıtında bulunan elemanlar ters sırada depolanmaktadır.
Çifte Dizi İki Başlı Kuyruk’a
eleman ekleme ve çıkarma işlemleri-
nin çalıştırılmasına birer örnek için bkz. Şekil 2.4. ekle(i, x) işlemi,
uygun olan, ya front veya back yığıtı üzerinde çalışır:
| 87
ekle(i, x)
işlemi, dengele() işlemini çağırarak front ve back Dizi
Yığıt’larını
dengeliyor. Dengeleme sonucunda boyut() < 2 olmadı-
ğı sürece, front.boyut() ve back.boyut() arasındaki fark kesinlikle
3 kattan daha büyük olamaz. 3*front.boyut()
3*back.boyut()
front.boyut()
back.boyut()
ve
koşulu dengele() tarafından de-
ğişmez olarak garanti edilir.
Şimdi, dengele() için yapılan çağrıların maliyeti önemsenmediği
takdirde,
ekle(i,
i< front.boyut()
x)
maliyetinin
analizine
değineceğiz.
iken, ekle(i, x) işlemi, front.ekle(front.boyut() - i
- 1, x) çağrısına göre yapılmaktadır. front yapısı Dizi Yığıt olduğu
için çalışma zamanı maliyeti şöyle hesaplanır:
Öte yandan, i
(i
front.boyut()
iken, ekle(i, x) işlemi, back.ekle
- front.boyut(), x) çağrısına göre yapılmaktadır. Bunun maliyeti,
Dikkat ederseniz, (2.1) durumunun, i < n/4 koşulu altında ve (2.2)
durumunun i
n/4
i < 3n/4
3n/4
için oluştuğunu fark edebilirsiniz.
koşulunda ise, front veya back yığıtlarından hangi-
sinde işlem görüldüğünden emin olamayız, fakat her iki durumda
ve n
olduğundan, ekleme işlemi, O(n) = O(i)
da, i
n/4
= O(n
- i) zamanda çalışır. Özetlersek,
i > n/4
88|
Bu nedenle, ekle(i, x) işlemine yapılan bir çağrının çalışma zamanı, dengele() için gerekli maliyet önemsenmediği takdirde,
olarak hesaplanır.
ekle(x, i)
işlemi ve analizine benzeyen, sil(i) işleminin uygulaması
aşağıda gösterilmiştir:
| 89
Dengeleme
Bu bölümde, dengele() işlemini anlatacağız. ekle(i, x) ve sil(x)
tarafından çağrısı yapılan bu işlem, front ve back yığıtlarının ne
çok dolu ne de çok boş olmamasını sağlar. İki elemandan daha az
boyutta olmadıkları sürece, front ve back yığıtlarının her biri en az
n/4
eleman içermelidir. Bu koşul sağlanmadıysa, elemanların ko-
numlarını kendi aralarında yer değiştirerek hareket ettirmeliyiz.
Böylece, front ve back tam olarak, sırasıyla
depolayacak şekilde dengeli hale gelmelidir.
ve
eleman
90|
Burada analiz edilmesi gereken küçük bir konu var. dengele() işlemi dengelemeyi yapıyorsa, o zaman O(n) eleman bir konumdan
bir başka konuma taşınmış demektir, ve çalışma zamanı O(n) olarak belirlenir. ekle(i, x) ve sil(x) için yapılan her çağrının, dengele()
işlemini çağırdığını göz önünde tutarsanız, bunun iyi bir sonuç
olmadığını fark edersiniz. Ortalama olarak, aşağıdaki öneri gösteriyor ki, dengele(), işlem başına sabit miktarda zaman çalışır.
Öneri 2.2. Başlangıçta, Çifte Dizi İki Başlı Kuyruk elemanları boş
değer taşırken, ekle(i, x) ve sil (i) işlemleri sıralı olarak
m
1
defa çağrılırsa, o zaman dengele() için yapılan tüm çağrılar O(m)
toplam zamanda çalışır.
Kanıt. Eğer dengele(), elemanları kaydırmak zorunda kalırsa, son
kaydırmadan bu yana çağrılmış bulunan ekle(i, x) ve sil(i) işlemlerinin sayısı en az n/2 – 1 olarak hesaplanır. Öneri 2.1’in kanıtında
olduğu gibi, dengele() toplama çalışma zamanının O(m) olduğunu
kanıtlamak için bu yeterlidir.
Burada potansiyel işlemi olarak adlandırılan bir teknik kullanarak
analiz gerçekleştireceğiz. Çifte Dizi İki Başlı Kuyruk’un potansiyeli,
, front ve back boyutları arasındaki fark olarak tanımlanır.
Bu potansiyel hakkında ilginç olan gözlem şudur ki, ekle(i, x) veya
sil(i)
çağrıları dengelemeye gerek duymuyorsa, potansiyel üzerinde
en çok 1 artırım etkisine sahiptir.
| 91
Şöyle ki, dengele() çağrısı elemanları kaydırdıktan hemen sonra,
potansiyel
, en çok 1’dir, çünkü,
Elemanları kaydıran bir dengele () çağrısından hemen önceki durumu düşünün ve detayları atlayarak varsayın ki, 3*front.
boyut()<back.boyut()
koşulu sağlandığı için, dengele() işlemiyle
elemanlar kaydırılacaktır. Farkında olmalısınız ki,
Ayrıca, bu andaki potansiyel,
olarak hesaplanır.
Bu nedenle, dengele() tarafından yapılan son kaydırmadan itibaren
ekle(i, x)
ve sil(i) işlemlerine yapılan çağrıların sayısı en az
olarak hesaplanır.
92|
Özet
Aşağıdaki teorem Çifte Dizi İki Başlı Kuyruk’un özelliklerini özetlemektedir:
Teorem 2.4. Çifte Dizi İki Başlı Kuyruk, Liste arayüzünü uygular.
yeniden_boyutlandır()
ve dengele() için yapılan işlem çağrısı
maliyeti önemsenmediği takdirde, Çifte Dizi İki Başlı Kuyruk aşağıdaki işlemleri destekler:
al(i)
ekle(i, x)
ve belirle(i, x) işlem başına O(1) zamanda çalışır,
ve sil(i) işlem başına
za-
manda çalışır.
Başlangıçta, Çifte Dizi İki Başlı Kuyruk elemanları boş değer taşırken, ekle(i, x) ve sil(i) işlemleri sıralı olarak m defa çağrılırsa,
yeniden_boyutlandır()
ve dengele() işlemleri için yapılan tüm
çağrılar, O(m) toplam zamanda çalışır.
| 93
Kök Dizi Yığıt: Alan Kriteri Verimli Olan Dizi
Yığıt Uygulaması
Önceki bölümlerde anlatmış olduğumuz veri vapılarındaki ortak
sorun, kendi verilerini bir veya iki dizide depoladıkları halde, sık
sık dengeleme veya yeniden boyutlandırma gerçekleştiği için hiçbir
zaman çok dolu hale gelmemeleridir. Örneğin, Dizi Yığıt üzerinde
gerçekleştirilen yeniden_boyutlandır () işleminden hemen sonra,
takviye a dizisinin sadece yarısı doludur. Daha da kötüsü, a’nın
sadece 1/3 oranında veri içerdiği zamanlar vardır.
Bu bölümde, boşa harcanan alan sorununu ele alan Kök Dizi Yığıt
veri yapısını tartışacağız. Kök Dizi Yığıt, n elemanı
diziyi
kullanarak depolar. Bu dizilerde, herhangi bir anda, en çok
adet kullanılmayan dizi konumu bulunur. Kalan tüm dizi konumları
veri depolamak için kullanılır. Bu nedenle, bu veri yapıları n elemanı depolarken en çok
alanı boşa harcamıştır.
94|
Kök Dizi Yığıt
veri yapısı, 0, 1,…,r - 1 olarak numaralandırılan ve
blok adı verilen r adet dizi listesinde elemanları depolar, bkz. Şekil
2.5. b bloğu b + 1 elemanı depolar. Bu nedenle, r adet blok toplam
olarak,
eleman depolar.
Yukarıdaki formül Şekil 2.6'de gösterildiği gibi elde edilmiştir.
| 95
Tahmin edebileceğiniz gibi, listenin elemanları blok içinde sırayla
düzenlenmiştir. Endeksi 0 olan liste elemanı, blok 0’da depolanır,
endeksleri 1 ve 2 olan liste elemanları, blok 1’da depolanır, liste
endeksleri 3, 4, 5 olan elemanlar blok 2’de depolanır, vb. Üzerinde
durmamız gereken başlıca sorun, endeks i verildiğinde hangi bloğun i içerdiğini ve ikincisi bu blok içinde i’ye karşılık gelen endeksi
belirlemektir.
Kendi bloğu içinde i endeksini belirlemek kolaydır. i endeksi b bloğunun içinde kalıyorsa, blok 0, 1,…,b – 1 içinde bulunan toplam
eleman sayısı b(b+1)/2 olarak belirlidir. Bu nedenle, b bloğu içinde i konumu,
olarak hesaplanır. Biraz daha zor olanı, b değerini belirleme sorunudur. Endeksi i’den daha az, veya eşit olan elemanların sayısı i +
96|
1’e
eşittir. Diğer taraftan, 0,…,b bloklarındaki toplam eleman sayısı
(b+1)(b+2)/2’dir. Bu nedenle, b,
koşulunu sağlayan en küçük tamsayıdır. Bu denklemi,
olarak tekrar yazabiliriz. Buna karşılık gelen b2 + 3b – 2i = 0 ikinci dereceden denkleminin iki çözümü vardır:
ve
. İkinci çözüm, bizim uygulamamız için hiç
mantıklı gelmiyor, çünkü her zaman negatif değer verir. Bu nedenle,
çözümünü elde ederiz. Genel olarak, bu
çözüm bir tamsayı değildir, ama eşitsizliğimize geri dönersek,
koşulunu sağlayan en küçük tamsayı olan b’yi
istiyoruz. Sade bir şekilde bu,
olarak hesaplanır.
| 97
Bu arada, al(i) ve belirle(i, x) metotları açık hale geldi. İlk olarak,
uygun b bloğunu ve blok içindeki uygun j endeksini hesaplarız ve
daha sonra uygun işlemi gerçekleştiririz:
Blok listesini temsilen bu bölümdeki veri yapılarından herhangi
birini kullanırsanız, o zaman al(i) ve belirle(i, x) işlemlerinin her
ikisi de sabit sürede çalışır.
ekle(i, x)
işlemi, artık, tanıdık gelir. Öncelikle, blok sayısının
r(r+1)/2 = n
eşitliğini sağlayıp sağlamadığını kontrol ettikten son-
ra, veri yapısının tam dolu olup olmadığını belirleriz. Burada r blok
sayısıdır. Eşitlik sağlanmışsa, bir başka blok eklemek için büyült()
çağrısı yaparız. Bu işlem sırasında endeksi i olan yeni elemana yer
açmak için i,…,n - 1 endeksli elemanlar sağa doğru 1 konum kaydırılır.
98|
büyült()
işlemi, beklendiği gibi, yeni bir blok ekler:
Büyültme işleminin maliyeti önemsenmediği takdirde, işlem başına
ekle(i, x)
maliyetinin en önemli parçası kaydırma hareketi için ge-
rekli maliyettir, ve Dizi Yığıt’daki gibi sadece O(1+n - i) zamanda
çalışır.
sil(i)
işleminin uygulaması, ekle(i, x) işlemine benzer şekildedir.
i+1,…,n
endeksli elemanları sola doğru 1 konum kaydırır, ve daha
sonra, kullanılmayan blokların birini ortadan kaldırmak için küçült() işlemine
çağrı yapar.
| 99
küçült()
işleminin maliyeti önemsenmediği takdirde, sil(i) maliye-
tinin en önemli parçası, kaydırma hareketlerine aittir, ve bu nedenle
O(n – i) zamanda çalışır.
100|
Büyültme ve Küçültmenin Analizi
Yukarıdaki ekle(i, x)
ve sil(i) analizi, büyült() ve küçült() maliye-
tini dikkate almadı. Dizi Yığıt’ın yeniden_boyutlandır() işleminden
farklı olarak, büyült() ve küçült() işlemleri herhangi bir veri kopyalamaz. Sadece, r boyutlu bir diziyi bellekten tahsis eder veya
serbest bırakır. Bu işlem bazı ortamlarda, sabit zaman, diğerlerinde,
r orantılı
zaman gerektirebilir.
büyült()
veya küçült() çağrısından hemen sonra durum berrak hale
gelir. Son blok tamamen boştur ve diğer tüm bloklar tamamen doludur. En az r - 1 elemanı ekleyene veya silene kadar, büyült()
veya küçült() için hiçbir çağrı yapılmayacaktır. büyült() ve küçült()
işlemleri, O(r) zamanda çalışsa bile, bu maliyet en az r - 1
adet ekle(i, x) veya sil(i) işlemi üstünden amortize edilir. Bu nedenle, ekle(i, x) veya sil(i) işlemlerinin amortize maliyeti, işlem
başına O(1) zamanda çalışır.
| 101
Alan Kullanımı
Ardından, Kök Dizi Yığıt veri yapısının kullandığı ek alan miktarını
çözümlüyoruz. Özellikle, Kök Dizi Yığıt veri yapısı içinde kullanılabilir olan, fakat halen bir liste elemanını barındırmayan boş alanı
saymak istiyoruz. Bu tür elemanların kapladığı alana israf alanı
diyoruz.
Kök Dizi Yığıt
işlemlerinden sil(i), tamamen dolu olmayan iki blok-
tan daha fazlasını tutmaya izin vermez. n elemanı depolayan Kök
Dizi Yığıt’ın
kullandığı blok sayısı, r, bu nedenle,
koşulunu sağlar. Bunu ikinci dereceden denklem olarak çözersek,
elde edilir. Son iki bloğun boyutları r ve r - 1’dir. Bu yüzden, bu iki
blok tarafından israf edilen alan en fazla
olarak
hesaplanır. Blokları, örneğin, bir Dizi Liste halinde depoluyorsanız,
r
bloğu depolayan Liste’nin israf alan miktarı,
olacak-
tır. n ve diğer uygulama bilgilerini depolamak için gerekli alan
miktarı O(1)’dir. Bu nedenle, Kök Dizi Yığıt’da israf edilen toplam
alan miktarı,
olarak hesaplanır.
102|
Başlangıçta boş olan ve her seferinde bir eleman ekleyebilen herhangi bir veri yapısı için, bu alan kullanımının en uygun olduğunu
ispat edeceğiz. Daha açık olarak, n eleman eklerken, veri yapısının
israf ettiği alan miktarı, anlık olsa bile, en azından
olur.
Boş bir veri yapısı ile başladığımızı ve her seferinde bir tane olmak
üzere toplam n elemanı eklediğimizi varsayalım. Bu işlem sonunda,
n
elemanın tamamı veri yapısında depolanmış ve r bellek blokları-
nın arasında dağıtılmış olacaktır.
sağlanıyorsa, veri yapısı r
bloğun izini kaybetmemek için, r işaretçi (veya referans) kullanmalıdır, ve bu işaretçiler israf alanıdır.
sağlanmışsa, yazı ma-
sası çekmecesi ilkesi (pigeon hole principle) ile, bir blok en azından
boyutunda olacaktır. Böyle bir bloğu öncelikle tahsis
ettiğimizi düşünün. Bu tahsisten hemen sonra, blok boştur ve bu
nedenle
n
alan miktarını israf eder. Böylece bir an için olsa bile,
elemanın yerleştirilmesi sırasında, veri yapısı
israf etmiştir.
alan miktarını
| 103
Özet
Aşağıdaki teorem Kök Dizi Yığıt veri yapısı ile ilgili tartışmamızı
özetlemektedir:
Teorem 2.5. Kök Dizi Yığıt, Liste arayüzünü uygular. büyült() ve
küçült()
için yapılan işlem çağrısı maliyeti önemsenmediği takdir-
de, Kök Dizi Yığıt aşağıdaki işlemleri destekler:
al(i)
ekle(i, x)
ve belirle(i, x) işlem başına O(1) zamanda çalışır,
ve sil(i) işlem başına O(1 + n - i) zamanda çalı-
şır.
Başlangıçta, Kök Dizi Yığıt elemanları boş değer taşırken, ekle(i,
x)
ve sil(i) işlemleri sıralı olarak m defa çağrılırsa, büyült() ve
küçült()
işlemleri için yapılan tüm çağrılar, O(m) toplam zamanda
çalışır.
n
eleman depolayan Kök Dizi Yığıt’ın kullandığı alan (bellek söz-
cüğü cinsinden),
olarak belirlidir.
104|
Karekökleri Hesaplamak
Hesaplama Modeli Bölümü’nü okuyan bir okuyucu, Kök Dizi Yığıt
veri yapısının, RAM-sözcük hesaplama modeline her zaman uymadığını fark edecektir. Bunun nedeni, karekök işlemi genellikle temel bir işlem olarak kabul edilmediği için, çoğu zaman RAMsözcük modelinin bir parçası değildir.
Bu bölümde, karekök işleminin etkin bir şekilde uygulanabilir olduğunu göstereceğiz. Özellikle,
da,
zamanlı ön işleme sonrasın-
uzunluğunda iki dizi oluşturarak, herhangi bir tamsayı
için, sabit zamanda
değerini hesaplayabileceği-
mizi göstereceğiz. Aşağıdaki önerme, x karekökünü hesaplama
problemini, bağlı bir x’ karekökünü hesaplamaya indirgemiştir.
Öneri 2.3.
iken, x ≥1 ve x’ = x - a olsun. Bu durumda,
olarak hesaplanır.
Kanıt. Şu bağıntının doğru olduğunu göstermek yeterlidir:
Her iki tarafın karesini aldığımızda,
| 105
elde ederiz. Terimler bir araya getirildiğinde, herhangi bir x ≥ 1
için,
sade bir şekilde
Başlangıçta problemi biraz daraltalım, 2r ≤ x ≤ 2r+1 için
varsayalım; yani, x, ikili tabanda r + 1 bitlik bir tamsayıdır.
değerini aldığında, Öneri 2.3’ün ko-
şullarını yerine getiren bir x’, ve dolayısıyla
elde
ederiz. Ayrıca, x’ değerini oluşturan en sağdaki r/2 bitin hepsi 0
değerine sahip olduğu için, mümkün olan her x’ değeri şu bağıntıyı
geçerli kılar:
Bunun anlamı, olası her x’ değeri için
sqrttab
değerini depolayan
adında bir dizi kullanmalıyız. Biraz daha kesin olmak gere-
kirse,
Buradan, her
nin,
için, sqrttab[i] değeri-
’in 2 katı ile sınırlı olduğunu görebilirsiniz. Diğer bir deyiş-
le, dizinin
değeri
konumunda bulunan eleman
, veya
olmuştur. s yardımıyla
106|
değerini de belirleyebilirsiniz. Bunu gerçekleştirmek için, (s+1)2
x
koşulunu sağlayana kadar, s, değerini 1 artırın.
Bu uygulama sadece
ve
belirli
değeri için çalışmaktadır. Tümü için çalıştırmak istediğinizde, her
değeri için birer tane olacak şekilde
sqrttab
adet farklı
dizisini hesaplamalısınız. Dizinin boyutu
olup , en çok
ile sınırlı
olur.
Şimdi ortaya çıkıyor ki, birden fazla sqrttab dizisi gereksizdir; sadece
= r’
değeri için bir sqrttab dizisine gerek duyarız. log x
r
denklemini sağlayan herhangi bir x değeri, 2r-r’ ile çarpıla-
rak ve,
denklemini kullanarak düzeltilebilir.
2
r-r’
x ifadesi
aralığında bir değerdir, ve karekökü-
nü sqrttab içinde arayabiliriz. Aşağıdaki kod,
aralı16
ğındaki negatif olmayan tüm x tamsayıları için, ve 2 boyutundaki
sqrttab
dizisini kullanarak,
değerini hesaplıyor.
| 107
Şimdiye kadar
’in nasıl hesaplanacağına kesin gözle
baktık. Bu problemi 2r/2 boyutundaki bir logtab dizisiyle şöyle çözebiliriz.
ikili x gösteriminin en soldaki bit endeksi olduğu
için, logtab dizininde bir endeks olarak kullanılmadan önce,
x
2
r/2
için, x bitlerini sağa doğru r/2 konum kaydırılabiliriz.
Aşağıda verilen kolay anlaşılır kod, 216 büyüklüğündeki logtab
dizisini kullanarak
aralığındaki tüm x verileri için
değerini hesaplıyor.
Son olarak, bütünlük için, logtab ve sqrttab dizilerini başlatan kodu da ekliyoruz:
108|
Özetlemek gerekirse sözcük-RAM modelinde, i2b(i) metotuna ait
hesaplamalar, sqrttab ve logtab dizilerini depolamak için gerekli
olan
ekstra belleği kullanarak sabit zamanda çalışır. n iki kat
arttığı veya azaldığı zaman, bu diziler yeniden yapılandırılır, ve
bunun maliyeti, Dizi Yığıt uygulamasında analiz edilen yeniden_boyutlandır()
maliyetiyle aynı şekilde, n’de değişikliğe sebep
olan, ekle(i, x) ve sil(i) işlemlerinin sayısı üstünden amortize edilir.
| 109
Tartışma ve Alıştırmalar
Bu bölümde açıklanan veri yapılarının çoğu, 30 yıl öncesindeki
uygulamalarda rastladığımız benzerlik ve çeşitliliği içerir. Örneğin,
Dizi Yığıt, Dizi Kuyruk
Kuyruk
ve Çifte Dizi İki Başlı Kuyruk yapıları, Yığıt,
ve Çift Başlı Kuyruk kullanarak kolayca uygulanabilir.
Knuth bu yapıları gerçekleştirdi [46, bkz.Hızlı Dizi Yığıtı: Optimize Dizi Yığıtı Bölümü].
Kök Dizi Yığıtı’nı,
ilk olarak, Brodnik ve arkadaşları [13] tanımladı
ve Alan Kullanımı Bölümü’nde verilen sınıra benzer bir
alt
sınırı ispatladı. Aynı zamanda, i2b(i) işlemi sırasında karekök hesabından kaçınmak amacıyla, daha karmaşık blok boyutlarını kullanan farklı bir yapı kullanılabilir. Böyle bir tasarımda, i’nin dahil
olduğu blok
ile endekslenen bloktur. i+1 sayısının ikili
gösteriminde, en önemli konumdaki 1 biti, endeksi gösterir. Bazı
bilgisayar mimarilerinde, 1-bitinin konumu, verilen bir tamsayı için
otomatik olarak çalıştırılan komutlarla hesaplanmaktadır.
Kök Dizi Yığıtı
ile ilgili bir başka veri yapısı da, Goodrich and
Kloss’un iki seviyeli katmanlı vektörüdür [35]. al(i, x) ve belirle(i,
x)
işlemlerini sabit sürede, ve ekle(i, x) ve sil(i) işlemlerini
zamanda çalıştırır. Kök Dizi Yığıt veri yapısı ile ilgili olarak, Alıştırma 2.11’de önerilen uygulamaya benzer daha iyi performans
gösterebilir.
110|
Alıştırma 2.1. Dizi Yığıt uygulamasında, sil(i) metoduna yapılan
birinci çağrı sonrasında, a, takviye dizisi, n + 1 adet null-olmayan
değeri içerir. Dizi Yığıt, sadece n eleman depoladığı için, nullolmayan fazladan değer nereye gitmiştir? Java Çalışma Zamanı
Ortamı’nın bellek yöneticisi bundan nasıl etkilenir? Tartışın.
Alıştırma 2.2. Liste arayüzüne ait, hepsiniEkle(i, c) işlemi, c koleksiyonunda bulunan her elemanı listenin i’nci konumuna yerleştirir (ekle(i, x) işlemi, c = {x} özel durumudur). Bu bölümde anlatılan veri yapılarını kullanarak, hepsiniEkle(i, c) işlemini, verimli
olarak tasarlayın ve uygulayın. ekle(i, x) işlemini yineleyerek çağırmak neden verimli olmaz? Açıklayın.
Alıştırma 2.3. Kuyruk arayüzünün bir uygulaması olan, Rasgele
Kuyruk
veri yapısını tasarlayın ve uygulayın. sil() işlemi, kuyrukta
bulunan tüm elemanlar arasından rasgele seçilmiş bir elemanı siler.
(Rasgele Kuyruk’u, eleman ekleyen, değerini getiren ve rasgele
konumdan eleman silen bir torba (bag) gibi düşünün). Rasgele
Kuyruk’un ekle(x)
ve sil() işlemleri sabit zamanda çalışır.
Alıştırma 2.4. Liste arayüzünün bir uygulaması olan, Üç Uçlu Kuyruk’u
tasarlayın ve uygulayın. al(i) ve belirle(i, x) işlemleri sabit
zamanda çalışırken, ekle(i, x) ve sil(i) işlemleri,
zamanda çalışır.
| 111
Başka bir deyişle, listenin her iki ucunda veya orta konumunda
bulunan veriler için işlemler en hızlı çalışır.
Alıştırma 2.5. a dizisi üzerinde çalışan, yer_değiştir(a, r) işlemi,
her i {0,…,a.length} için, a[i] elemanını, a[(i + r) mod
a.length]
konumuna taşır, ve yerini değiştirir. yer_değiştir(a, r)
işlemini uygulayın.
Alıştırma 2.6. Liste’nin i konumunda bulunan elemanları
[(i + r) mod n]
konumuna taşıyan, yer_değiştir(r) işlemini uygu-
layın. Dizi İki Başlı Kuyruk veya Çifte Dizi İki Başlı Kuyruk veri
yapısına ait, yer_değiştir(r) işlemi, O(1 + min{r, n – r}) zamanda
çalışmalıdır.
Alıştırma 2.7. Dizi İki Başlı Kuyruk veri yapısına ait, ekle(i, x),
sil(i),
ve yeniden_boyutlandır() işlemlerini yeniden yazın. Yeni
uygulamanızda, kaydırma hareketlerini gerçekleştirirken, daha hızlı
çalışabilen System.arraycopy(s, i, d, j, n) fonksiyonunu kullanın.
Alıştırma 2.8. Dizi İki Başlı Kuyruk uygulamasında kullanılan %
işleci bazı sistemlerde masraflı çalışır. Bunu kullanmak yerine,
a.length,
2 üssüne ait bir sayı iken,
gerçeğinden yararlanın.
(Burada, & işleci, bitdüzeyi-ve işlemini gösterir).
112|
Alıştırma 2.9. Modüler aritmetik hesabı yapmayan, Dizi İki Başlı
Kuyruk
veri yapısını tasarlayın ve uygulayın. Verilerin tamamı, bir
dizi içinde, sırayla ardışık bloklar üzerinde yerleştirilmiştir. Dizi,
başlangıç
veya
den_yapılandır()
son
sınırdan
dışarı
taştığı
anda,
yeni-
işlemi çalışır. Veri yapısı üzerindeki tüm işlemle-
rin amortize maliyeti, Dizi İki Başlı Kuyruk ile aynı zamanda performansı göstermelidir.
Alıştırma 2.10. İsraf alanı
sil(i, x)
işlemleri O(1 + min{i, n - i}) zamanda çalışan Kök Dizi
Yığıt versiyonunu
tasarlayın ve uygulayın.
Alıştırma 2.11. İsraf alanı
sil(i, x)
Yığıt
olan, ancak ekle(i, x) ve
işlemleri
olan, ancak ekle(i, x) ve
zamanda çalışan Kök Dizi
versiyonunu tasarlayın ve uygulayın (Fikir için, bkz. AVListe:
Alan-Verimli Liste Bölümü).
Alıştırma 2.12. İsraf alanı
sil(i, x)
Yığıt
işlemleri
olan, ancak ekle(i, x) ve
zamanda çalışan Kök Dizi
versiyonunu tasarlayın ve uygulayın (Fikir için, bkz. AVListe:
Alan-Verimli Liste Bölümü).
Alıştırma 2.13. Kübik Dizi Yığıtı veri yapısını tasarlayın ve uygulayın. Üç seviyeli bu yapı, Liste arayüzünü uygular. Kullandığı
O(n
2/3
)
israf alanıyla, ekle(i, x) ve sil(i) işlemlerini O(n1/3)
amortize maliyetle çalıştırırken, al(i) ve belirle(i, x) işlemleri sabit
zamanda çalışır.
| 113
Bölüm 3
Bağlantılı Listeler
Bu bölümde, Liste arayüzü uygulamalarını çalışmaya devam edeceğiz; bu kez dizi tabanlı veri yapıları yerine, işaretçi-tabanlı veri
yapılarını kullanacağız. İnceleyeceğimiz yapılar, liste elemanlarını
içeren düğümlerden oluşuyor. Düğümler, referanslar (işaretçiler)
yoluyla bir dizi halinde bir araya bağlanmaktadır. İlk olarak, teklibağlantılı listeleri çalışacağız. Bu veri yapısı, Yığıt ve (FIFO) Kuyruk
işlemlerini, işlem başına sabit zamanda çalıştırır. Daha sonra,
çifte-bağlantılı listelere geçeceğiz. Bu yapı, İki Başlı Kuyruk işlemlerini sabit zamanda çalıştırır.
Liste
arayüzünün dizi tabanlı uygulamaları, bağlantılı listeler ile
kıyaslandığında, bazı avantaj ve dezavantajlar ile karşılaşılır. Birinci dezavantajı, herhangi bir elemana erişmek için, sabit zamanlı
al(i)
ve belirle(i, x) işlemlerini kullanma yeteneğimizi kaybedebili-
riz. Bunun yerine, i'nci elemana ulaşana kadar, liste üzerindeki her
bir eleman üzerinden yürümek zorunda kalırız. En önemli avantajı
ise, daha dinamik olmasıdır: u herhangi bir liste düğümü olduğu
takdirde, u listenin hangi konumunda bulunursa bulunsun, u için
bir referans verilirse, u silinebilir veya u’ya bitişik bir düğüm, sabit
zaman içinde eklenebilir.
114|
TBListe: Tekli-Bağlantılı Liste
TBListe
(tekli-bağlantılı liste), bir dizi Düğüm’den oluşur. Her u
düğümü, u.x verisi, ve dizinin bir sonraki düğümüne referans veren, u.next işaretçisini depolar. Dizinin son düğümü, w için,
w.next = null
olarak hesaplanır.
Verimliliği artırmaya yarayan head ve tail değişkenleri, listenin
birinci düğümü ile son düğümünü izlemek için kullanılır. Bunun
yanı sıra, dizinin uzunluğunu takip etmek için, n tamsayısı kullanılır:
| 115
TBListe
üzerinde uygulanan Yığıt ve Kuyruk işlemlerinden bazıları
Şekil 3.1'de gösterilmiştir.
Dizinin başındaki elemanları ekleyerek ve silerek, Yığıt işlemlerinden yığ() ve yığıttan_kaldır() işlemleri, TBListe tarafından verimli
şekilde gerçekleştirilir. yığ() işlemi, veri değeri x olan yeni bir u
düğümü oluşturur; bunu u.next değişkenini kullanarak eski listeye
ekler, ve listenin yeni başı, u olarak hesaplanır. En sonunda, n, 1
artırılır, çünkü TBListe’in boyutu 1 artmıştır:
yığıttan_kaldır()
işlemi, TBListe düğümlerinin boş olup olmadığını
kontrol ettikten sonra, listenin başını head=head.next olarak belirler, ve n, 1 azaltılır. Son eleman silinirken özel bir durum oluşur ki,
burada, listenin sonu tail=null olarak belirlenmiştir.
116|
Açıktır ki, yığ(x) ve yığıttan_kaldır() işlemlerinin her ikisi de O(1)
zamanda çalışır.
| 117
Kuyruk İşlemleri
Bir TBListe, FIFO Kuyruk işlemlerinden ekle(x) ve sil() işlemlerini
sabit zamanda gerçekleştirir. Silmeler, listenin başından yapılır, ve
yığıttan_kaldır()
işlemi ile eşdeğerdir:
Diğer yandan eklemeler, listenin sonundan yapılır. Çoğu durumda
bu, tail.next = u belirlenmesi ile gerçekleştirilir, burada u, x verisini içeren, yeni oluşturulan düğümdür. Ancak n=0 olduğunda,
özel bir durum ortaya çıkar. Bu özel durumda, tail = head = null
olarak belirlenmiştir. Ekleme sonucunda, hem tail ve hem head, u
olarak belirlenir.
118|
Açıktır ki, ekle(x) ve sil() işlemlerinin her ikisi de O(1) zamanda
çalışır.
Özet
Aşağıdaki teorem TBListe performansını özetlemektedir:
Teorem 3.1. TBListe, Yığıt ve (FIFO) Kuyruk arayüzlerini uygular.
yığ(x), yığıttan_kaldır(), ekle(x)
ve sil() işlemleri, işlem başına
O(1) zamanda çalışır.
TBListe,
neredeyse, İki Başlı Kuyruk işlemlerinin tamamını uygu-
lar. Tek eksik işlem, TBListe düğümlerinin sonuncusunu ortadan
kaldırmaktır. Son TBListe düğümünün silinmesi zordur, çünkü öyle
bir şekilde güncellenmesi gerekir ki bu, TBListe içindeki sondan bir
önceki w düğümüne işaret etsin; bu, w.next = tail olan w düğümüdür. Ne yazık ki, w’ya ulaşan tek yol, TBListe’nin en başındaki düğümden başlanıp, adım adım ilerleyerek n – 2 adım atılmasıdır.
| 119
ÇBListe: Çifte-Bağlantılı Liste
ÇBListe
(çifte-bağlantılı liste) veri yapısı, TBListe’ye çok benzerdir,
ancak ÇBListe’deki her u düğümünün ardından u.next, ve öncesinden u.prev bağlantılarına referans verilmiştir.
TBListe
uygulamasında, dikkate alınması gereken sadece birkaç
özel durum olduğunu öğrendik. Örneğin, son elemanı silmek, veya
boş bir TBListe’ye eleman eklemek için, listenin baş ve son elemanları doğru olarak güncellenmelidir. ÇBListe’ye baktığımızda, özel
durum sayısının önemli ölçüde arttığını görürüz. Belki de, ÇBListe
için, tüm bu özel durumların üstesinden gelmenin en temiz yolu,
herhangi bir veri içermeyen, sadece yer tutucu görevini gören bir
dummy
düğümünü tanıtmaktır. Bu sayede, özel düğüm kavramı
ortadan kalkar; her düğümün, bir sonraki ve bir önceki bağlantısı
mevcut olur. Listedeki son düğümü izleyen düğüm, dummy düğümdür. Listedeki ilk düğümden önce gelen düğüm, yine dummy
düğümdür. Böylece, Şekil 3.2’de gösterildiği gibi, listenin düğümleri, bir döngü içinde iki kat olmak üzere çifte bağlanmıştır.
120|
ÇBListe
elemanlarına belirli bir endeks pozisyonundan erişmek zor
değildir; ya listenin başından (dummy.next) başlar, ve ileri yönde
çalışırız, veya listenin sonundan (dummy.prev) başlar ve geri yönde çalışırız. i'nci düğüme erişmek işlemi, O(1 + min
{i, n – i})
zamanda çalışır:
al(i)
ve belirle(i, x) işlemleri de artık kolaydır. Gerçekleştirmek
için ilk olarak, i'nci düğümü buluruz ve daha sonra x değerini alır,
veya belirleriz.
| 121
Bu işlemlerin çalışma zamanı, i’nci düğümü bulmak için gerekli
zaman ile sınırlıdır, ve bu nedenle O(1 + min {i, n – i}) olarak
hesaplanır.
122|
Ekleme ve Çıkarma
ÇBListe’nin w
düğümüne referansınız varsa, ve w düğümünden
önce u düğümünü eklemek istiyorsanız, o zaman u.next=w, ve
u.prev = w.prev
u.next.prev
olarak belirledikten sonra gerekli u.prev.next ve
düzenlemelerini yapmalısınız (bkz. Şekil 3.3). Dummy
düğüm sayesinde, w.prev ve w.next’in mevcut olmaması mümkün
değildir.
ekle(i, x)
liste işlemini gerçekleştirmek, şimdi çok kolay hale gel-
miştir. ÇBListe’de yer alan i’nci düğümü buluruz. x verisini taşıyan
yeni bir u düğümünü hemen öncesine ekleriz.
ekle(i, x)
işleminin sabit olmayan tek çalışma zamanı bileşeni, i'nci
düğümü bulmak için gereken zamandır (alDüğüm(i) kullanarak).
| 123
Bu nedenle, ekle(i, x) işlemi, O(1 + min {i, n – i}) zamanda çalışır.
ÇBListe’den w
w.next
düğümünü silmek kolaydır. Sadece w.prev ve
işaretçilerini belirlemelisiniz; öyle ki listenin geri kalanı, w
düğümünü atlasın. Yine, dummy düğümün kullanımıyla herhangi
bir özel durumu dikkate alma ihtiyacı ortadan kalkar:
Şimdi sil(i) işlemi çok kolay hale gelir. i endeksli düğümü bulup
listeden çıkarırız:
Bu işlemin en masraflı bileşeni, alDüğüm(i) kullanarak i’nci düğümü bulmaktır. Bu nedenle, sil(i) işlemi, O(1+min {i, n – i})
zamanda çalışır.
124|
Özet
Aşağıdaki teorem ÇBListe performansını özetlemektedir:
Teorem 3.2. ÇBListe, Liste arayüzünü uygular. al(i), belirle(i, x),
ekle(i, x)
ve sil(i) işlemleri, işlem başına O(1+min {i, n – i}) za-
manda çalışır.
Değinilmesi gereken bir başka konu da, alDüğüm(i) için yapılan
işlem çağrısı maliyeti önemsenmediği takdirde, tüm ÇBListe işlemleri sabit zaman alır. Bu durumda, ÇBListe üzerindeki işlemlerin tek
masraflı bileşeni, ilgili düğümü bulmaktır. İlgili düğüme eriştikten
sonra, düğüm ekleme, silme veya o düğüme ait veri erişimi, sadece
sabit zaman alır.
Bölüm 2’deki dizi tabanlı Liste uygulamalarında, bunun tersi durum sözkonusudur. Bu uygulamalarda, ilgili dizi elemanına sabit
zamanda erişilir. Bununla birlikte, ekleme veya silme işlemleri, dizi
elemanlarının yerlerini değiştireceği için, genellikle, sabit olmayan
zamanda çalışır.
Bağlantılı liste yapıları, liste düğümlerine referansların, dış yollarla
elde edilebildiği uygulamalar için çok uygundur. Bunun bir örneği,
Java Koleksiyonlar Çerçevesi’nde bulunan LinkedHashSet veri
yapısıdır. Bu yapı, veri elemanlarını çifte bağlı listede saklarken,
çifte-bağlantılı liste düğümlerini de karma bir tabloda (bkz. Bölüm
| 125
5) depolar. LinkedHashSet elemanını silmek istediğinizde, karma
tablo, sabit zamanda ilgili liste düğümünü bulmak için kullanılır ve
daha sonra listedeki düğüm, sabit zamanda silinir.
126|
AVListe: Alan-Verimli Liste
Bu bölümde, bağlantılı listenin derinlerinde bulunan elemanlara
erişmek için gereken zamanın yanı sıra, kullanım alanı ile ilgili
sorunu çözmeye çalışacağız. Bir AVListe’nin her düğümü, kendisinden sonraki ve önceki düğümlere ait, iki ek referans gerektirir.
Bir düğümün iki bilgi alanı, listenin bakımı için ve sadece bir alan
veri depolamak için ayrılmıştır!
Bir AVListe (Alan-Verimli Liste), basit bir fikir kullanarak, harcanan bu alanı azaltır: Liste elemanlarını ÇBListe’de depolamak yerine, çeşitli elemanları içeren bir (dizi) blokta depolarız. Daha doğrusu, AVListe b blok boyutu tarafından parametrelendirilmiştir.
AVListe’de
yer alan her tek düğüm, b + 1 elemanı saklayacak kadar
alana sahip bir blok depolar.
Daha sonra açık hale gelecek nedenlerden dolayı, eğer her blokta
İki Başlı Kuyruk
işlemlerini yapabilirsek yararlı olacaktır. Bunun
için seçtiğimiz veri yapısı, Dizi İki Başlı Kuyruk: Dizi Kullanan
Hızlı İki Başlı Kuyruk Bölümü'nde anlatılan, Dizi İki Başlı Kuyruk
yapısından türetilmiş olan Sınırlı İki Başlı Kuyruk’tur. Sınırlı İki
Başlı Kuyruk,
küçük bir farkla Dizi İki Başlı Kuyruk’tan ayrılır:
Yeni bir Sınırlı İki Başlı Kuyruk oluşturulduğunda, takviye dizisi
olan, a dizisinin büyüklüğü, b + 1 ile sabitlenmiştir; boyutu hiçbir
zaman artmaz veya azalmaz. Sınırlı İki Başlı Kuyruk’un önemli bir
özelliği de, elemanları başa veya sona, sabit zamanda eklemeye
| 127
veya silmeye olanak tanır. Elemanların, bir bloktan, bir başka bloğa kaydırılması sırasında, bu özellikten yararlanacağız.
Bunun anlamı, AVListe, çifte-bağlantılı liste bloklarından oluşur:
128|
Alan Gereksinimleri
Bir bloğun eleman sayısı, AVListe’de çok sıkı kısıtlanmıştır: Bir
blok, son blok olmadığı sürece, o blok, en az b – 1 ve en çok
b+1
eleman içerir. Bunun anlamı, AVListe, n eleman içeriyorsa, o
zaman blok sayısı en fazla,
olarak hesaplanır. Sınırlı İki Başlı Kuyruk, her blok için, b + 1
uzunluğunda bir dizi içerir, ancak, sonuncu blok dışındaki her blok
için, en fazla sabit miktarda bir alan, bu dizide israf edilir. Bir blok
tarafından kullanılan bellek de, sabittir. Bunun anlamı, AVListe’nin
israf alanı, sadece O(b + n/b) olur. Sabit bir
faktörü içinde bir b
değeri seçerek, AVListe’nin alan gereksinimini, Kök Dizi Yığıt:
Alan Kriteri Verimli Olan Bir Dizi Yığıt Uygulaması, Alan Kullanımı Bölümü'nde verilen
alt sınırına yaklaştırabiliriz.
Elemanların Bulunması
AVListe
ile yüzleştiğimizde, ilk motivasyonumuz, belirli bir i en-
deksine ait, liste elemanını bulmaktır. Bir elemanın, listedeki yerini
oluşturan iki bölüm şunlardır:
1. i endeksli elemanı içeren bloğu içeren u düğümü; ve
2. kendi bloğu içinde elemanın j endeksi.
| 129
Belirli bir elemanı içeren bir bloğu bulmak için, ÇBListe’de olduğu
gibi, aynı şekilde devam etmeliyiz. Listenin başından başlayıp, ileri
yönde hareket etmeliyiz veya listenin sonundan başlayıp, istenen
düğüme ulaşana kadar, geriye doğru hareket etmeliyiz. Bir düğümden ötekine geçerken, bütün bloğu, bir seferde atlamalıyız.
Unutmayın ki, en fazla bir blok dışında, her blok en az b – 1 eleman içerir, bu nedenle, aramamız sırasında atılan her adım, bizi
130|
aradığımız elemana, b – 1 eleman kadar yaklaştırır. İleriye doğru
arama yapıyorsanız, O(1 + i / b) adım sonrasında, istediğiniz düğüme ulaşılırsınız. Geriye doğru arama yapıyorsanız, O(1 + (n – i)
/ b)
adım sonrasında, istediğiniz düğüme ulaşırsınız. Algoritma, i
değerine bağlı olarak, bu iki miktarın daha küçüğünü ele alır, böylece, i endeksli elemanı bulmak O(1 + min {i, n – i} / b) zamanda çalışır.
i
endeksli elemanı nasıl bulacağınızı biliyorsanız, al(i) ve belirle(i,
x)
işlemleri için doğru blokta belirli bir endeksi almayı, veya belir-
lemeyi kodlamanız gerekir:
Bu işlemlerin çalışma zamanları, elemanı bulmak için gereken zaman ile kısıtlanmıştır, bu nedenle, O(1 + min {i, n – i} / b) zamanda çalışır.
| 131
Elemanların Eklenmesi
AVListe’ye
eleman eklenmesi biraz daha karmaşıktır. Genel duru-
mu dikkate almadan önce, daha kolay olan, x elemanını listenin
sonuna ekleyen, ekle(x) işlemini gözden geçirelim. Son blok doluysa, (veya hiçbir blok henüz mevcut değilse), o zaman önce yeni
bir blok tahsis ederiz, ve blok listesine ekleriz. Şimdi, son bloğun
var olduğundan, ve onun boş olmadığından emin halde, x elemanını
bu bloğa ekleriz.
ekle(i, x)
kullanarak, listenin içinde bir yere eleman eklediğimizde,
işler biraz daha karışık hale gelir. i'nci liste elemanını içeren u düğümünün bloğuna erişmek için, ilk olarak, i bulunur. u bloğunun
içine, x elemanını eklemek sorununu çözmek için, u bloğunun, zaten b + 1 eleman içerdiği dolu olan durumu için hazırlıklı olmak
zorundayız. Bunun anlamı, x için o blokta yer yoktur.
u0, u1, u2,...
düğümlerinin işaretçilerini u, u.next, u.next.next
olarak belirleyelim. u0, u1, u2,… düğümleri, x elemanını eklemek
132|
için bir alan sağlanmasını araştırırken üç durumla karşılaşabilirsiniz
(bkz. Şekil 3.4):
1.
Dolu olmayan bir ur düğümünü hızlıca (r + 1 ≤ b adımda)
buluruz. ur düğümüne ait bloktan diğerine r eleman yer değiştirir,
böylece x elemanını eklemek için ur düğümünde serbest alan oluştururuz.
2.
Hızlıca (r + 1 ≤ b adımda) bulduğumuz blok listelerinin sonu-
na geliriz. Bloğun sonuna yeni bir boş blok ekleriz ve birinci halde
olduğu gibi devam ederiz.
3.
Dolu olmayan bir ur düğümünü bulamıyoruz. Bu durumda,
u0,…,ub-1
dizi bloklarının toplam sayısı, b iken, bu blokların her
biri, b + 1 eleman içerir. En son bloğun ardına, yeni bir blok ub
bloğu ekleriz, ve orijinal b(b + 1) elemanları yayarız. Böylece her
| 133
bir u0,…,ub bloğu tam olarak b eleman içerir. u0 bloğu, şimdi, tam
olarak b eleman içermektedir, ve bu nedenle eleman eklenebilir.
ekle(i, x)
işleminin çalışma zamanı, yukarıda ortaya konan üç du-
rumdan hangisine bağlı olduğuna göre değişir. 1. ve 2. durumlar,
elemanları incelemek ve değiştirmek için, en çok b blok kullanır,
bu nedenle O(b) zamanda çalışır. 3. durumda yayıl(u) işlemi çağrıldığında, b(b + 1) eleman yer değiştirir ve O(b2) zamanda çalışır.
3.durumun
maliyeti
önemsenmediği
takdirde
(daha
sonra
amortizasyon hesabıyla ele alınacaktır), i endeksinin yerini belirlemek, ve x elemanını eklemek, O(b + min {i, n – i} / b) zamanda
çalışır.
134|
Elemanların Silinmesi
Bir AVListe’den eleman silinmesi, eklemeye benzerdir. i endeksini
içeren u düğümünün yerini bulduktan sonra, u düğümüne ait blok,
b – 1
elemandan daha azına sahip olduğu için, bir elemanı u dü-
ğümünden silmenin olanaksız olduğu durum için hazırlıklı olmalıyız.
Yine, u0, u1, u2,... düğümlerinin işaretçilerini u, u.next,
u.next.next
b – 1
olarak belirleyelim. u0 bloğunun boyutunun en azından
olması için u0, u1, u2,… düğümlerinden herhangi birinden bir
eleman ödünç almalıyız. Bunu araştırırken, üç durum oluşabilir
(bkz. Şekil 3.5):
1.
Hızlıca (r + 1 ≤ b adımda) bloğu b – 1 elemandan daha fazla
eleman içeren bir düğüm buluruz. Bu durumda, bir bloktan öncekine r eleman yer değiştirir. Böylece ur düğümünün ekstra blok elemanı, u0 düğümünün ekstra blok elemanı haline gelir. Bunu takiben
u0
2.
bloğundan istenen elemanı sileriz.
Hızlıca (r + 1 ≤ b adımda) bulduğumuz, blok listelerinin so-
nuna geliriz. Bu durumda, ur düğümüne ait blok son bloktur ve ur
düğümüne ait bloğunun en az n – 1 eleman içermesine gerek yoktur. Bu nedenle, yukarıdaki gibi devam etmeliyiz ve u0 düğümünün
ekstra elemanı yapmak için ur düğümünden bir elemanı ödünç al-
| 135
malıyız. Bu ödünç alma sonrasında, ur düğümünün bloğu boş hale
gelirse, listeden sileriz.
3.
b
adım sonrasında, en fazla b – 1 eleman içeren herhangi bir
blok bulamadığımız takdirde, u0,...,ub-1 dizi bloklarının her biri b –
1
eleman içerir. Tüm bu b(b – 1) elemanı b – 1 adet bloğun her
birinde tam olarak b eleman olacak şekilde, u0,..., ub-2 düğümleri
halinde yeniden yapılandırırız, ve şimdi boş olan, ub-1 düğümünü
sileriz. u0 bloğu şimdi b eleman içermektedir ve bu nedenle eleman
silinebilir.
136|
ekle(i, x)
işlemine benzer şekilde, sil(i) işlemi, 3.durumdaki
birarayagetir(u)
işleminin maliyeti önemsenmediği takdirde,
O(b + min {i, n – i} / b) zamanda çalışır.
| 137
yayıl(u) ve birarayaGetir(u) Yöntemlerinin Amortize Edilmiş Analizi
Şimdi, ekle(i, x) ve sil(i) işlemleri tarafından çağrılabilen yayıl(u)
ve birarayaGetir(u) işlemlerinin maliyetini düşünüyoruz. Bütünlüğü sağlamak adına kodları aşağıda verilmiştir:
Bu işlemlerin her birinin çalışma zamanı, iki iç içe döngü tarafından kısıtlanmıştır. Hem iç ve hem dış döngüler, en fazla b + 1 defa
çalışır, bu nedenle, bu işlemlerin her biri O((b+1)2) = O(b2) top-
138|
lam zamanda çalışır. Ancak, aşağıdaki önerme, bu işlemlerin ekle(i, x)
ve sil(i) işlemlerine yapılan her b’nci çağrıda bir defa çalış-
tırıldığını gösteriyor.
Önerme 3.1. Boş bir AVListe oluşturulursa ve ekle(i, x) ve sil(i)
işlemleri sıralı olarak m ≥ 1 defa çağrılırsa, o zaman yayıl() ve
birarayaGetir()
işlemleri için yapılan tüm çağrılar, O(bm) toplam
zamanda çalışır.
Kanıt. Burada, yine bize güç vaat eden amortize analiz işlemini
kullanacağız. Bir u düğümüne ait blok, b eleman içermiyorsa, düğümün kırılgan olduğu söylenir (öyle ki u, ya son düğümdür veya
bloğunda b – 1, veya b + 1 eleman vardır). Bloğunda, b eleman
içeren herhangi bir düğümün engebeli olduğu söylenir. Burada, biz
sadece ekle(i, x) işlemini ve yayıl(u) işlemine yaptığı çağrı sayısı
ile olan ilişkisini dikkate alacağız. sil(i) ve birarayaGetir(u) işlemlerinin analizi benzerdir.
Bir AVListe’nin potansiyeli, içerdiği kırılgan düğümlerin sayısı
olarak tanımlanır. ekle(i, x) çalıştığında, 1. durum oluştuğunda,
sadece bir ur düğümünün boyutu değişmiştir. Bu nedenle, en fazla
bir ur düğümü engebeli olmaktan çıkar, kırılgan olmaya geçer. 2.
durum oluştuğunda, yeni bir düğüm oluşturulur ve bu düğüm kırılgandır, ancak başka hiçbir düğüm boyut değiştirmez. Bu nedenle,
kırılgan düğümlerin sayısı, 1 artar. Böylece, 1. veya 2. durumlarda,
AVListe’nin
potansiyeli en fazla 1 artar.
| 139
Son olarak, 3.durum oluştuğunda, bunun nedeni, u0,...,ub-1 düğümlerinin hepsinin kırılgan olmasıdır. Bunu takiben, yayıl() çağrılır,
ve bu b kırılgan düğüm, b + 1 engebeli düğüm ile yer değişir. Son
olarak, x elemanı, u0 bloğuna eklenir ve u0 kırılgan hale gelir. Toplam olarak, potansiyel b – 1 kadar düşer.
Özet olarak, potansiyelin başlangıç değeri, 0 olarak hesaplanır (listede hiçbir düğüm yoktur). 1. durum veya 2. durum her oluştuğunda, potansiyel en çok 1 artar. 3. durum oluştuğunda, potansiyel b –
1
azalır. (Kırılgan düğüm sayısı olan) potansiyel, hiçbir zaman
0'dan az değildir. Şu sonuca varabiliriz ki, 3. durum her oluştuğunda, 1. Durum veya 2. durum en az b – 1 defa oluşmuştur. Böylece,
yayıl(u)
işlemine yapılan her çağrı için, ekle(i, x) işlemine en azın-
dan, b çağrı yapılmıştır.
140|
Özet
Aşağıdaki teorem AVListe veri yapısının performansını özetliyor:
Teorem 3.3. AVListe, Liste arayüzünü uygular. yayıl(u) ve
birarayaGetir(u)
çağrılarının maliyeti önemsenmediği takdirde,
blok boyutu b olan AVListe aşağıdaki işlemleri destekler:
al(i)
ve belirle(i, x) işlem başına O(1 + min {i, n – i} / b )
zamanda çalışır,
ekle(i, x)
ve sil(i) işlem başına O(b + min { i, n – i } / b )
zamanda çalışır.
Başlangıçta, AVListe elemanları boş değer taşırken, ekle(i, x) ve
sil(i)
işlemleri sıralı olarak m defa çağrılırsa, yayıl(u) ve
birarayaGetir(u)
işlemleri için yapılan tüm çağrılar, O(bm) toplam
zamanda çalışır.
n
eleman depolayan AVListe’nin kullandığı alan, n + O(b + n / b)
olarak belirlidir.
AVListe’nin
uygulaması, Dizi Liste ve ÇBListe arasında seçim yap-
mayı gerektiriyor. Blok büyüklüğü, b, göz önünde tutularak bu iki
yapıdan biri, göreceli olarak seçilmelidir. En uç noktada, b=2 iken,
her AVListe düğümü, en çok üç değer depolayabilir. ÇBListe de,
hemen hemen aynıdır. Diğer bir uçta, b
n
iken, Dizi Liste’de ol-
| 141
duğu gibi tüm elemanlar, sadece bir dizide depolanabilir. Bu iki uç
arasında iseniz, bir liste elemanını eklemek veya kaldırmak için
gereken zaman ile belirli bir liste elemanını bulmak için gereken
zaman arasında bir seçim yapmanız gerekiyor.
142|
Tartışma ve Alıştırmalar
Tekli-bağlantılı ve çoklu-bağlantılı listelerin her ikisi de, 40 yıldan
bu yana programlarda kullanılmış olan ve kabul edilmiş tekniklerdir. Bunlar, örneğin, Knuth tarafından tartışılmıştır [46; Hızlı Dizi
Yığıtı: Optimize Dizi Yığıtı; Çifte Dizi İki Başlı Kuyruk: İki
Yığıt’tan İki Başlı Kuyruk Oluşturulması Bölümleri]. AVListe, veri
yapıları için iyi bilinen bir alıştırma gibi görünüyor. Hatta AVListe,
döngüsüz bağlantılı liste olarak adlandırılabilir [69].
Bir çifte-bağlantılı listede alan tasarrufu yapmanın bir başka yolu
XOR-listelerini kullanmaktır. XOR listesinde, her u düğümü,
u.önceki
ve u.sonraki işlemlerini bitsel x–veya işlemine tabi tutan,
u.sonrakiönceki
dummy
ve (ilk düğüme, veya liste boşsa dummy’e eşit olan)
dummy.sonraki
u.önceki
adında bir işaretçi ile gösterilir. Listenin kendisi,
olmak üzere, iki işaretçi depolar. Bu teknik, u ve
işaretçilerini kullanarak,
u.sonraki = u.önceki^u.sonrakiönceki
formülüyle, u.sonraki değerinin hesaplanabileceğini anlatır.
(Burada ^ işleci, iki argümanının bitsel x–veya hesabını yapmakta
kullanılmıştır). Bu teknik, kodu biraz zorlaştırır, ve – Java dahil –
çöp toplayan bazı dillerde, bu tekniği uygulamak mümkün değildir,
ancak, düğüm başına yalnızca bir işaretçi gerektiren, bir çifte-
| 143
bağlantılı liste uygulamasını sunmaktadır. XOR-listelerinin ayrıntılı
bir tartışması için bkz. Sinha’nın dergi makalesi [70].
Alıştırma 3.1. TBListe arayüzüne ait, yığ(x), yığıttan_kaldır(),
ekle(x)
ve sil() işlemlerinde ortaya çıkabilecek bütün özel durum-
ları önlemek için dummy düğümünün kullanılması neden mümkün
değildir?
Alıştırma 3.2. TBListe’nin, sondan ikinci elemanını döndüren,
sondanİkinci()
işlemini tasarlayın ve uygulayın. Bu işlemi uygular-
ken, liste eleman sayısı olan, n değişkenini kullanmayın.
Alıştırma 3.3. Liste işlemlerinden al(i), belirle(i, x), ekle(i, x) ve
sil(i)
işlemlerini TBListe arayüzüne uygulayın. İşlemlerin her biri,
O(1 + i) zamanda çalışmalıdır.
Alıştırma 3.4. TBListe’nin, tüm elemanlarını ters yönde sıralayan,
tersSırala()
işlemini tasarlayın ve uygulayın. Bu işlem, O(n) za-
manda çalışmalıdır; özyineleme, herhangi bir ikincil veri yapısı ve
yeni düğümlerin oluşturulması gerekli değildir.
Alıştırma 3.5. boyutKontrol() adında birer TBListe ve ÇBListe
işlemini tasarlayın ve uygulayın. Bu işlem, liste elemanları üzerinden adım adım giderek, listede kayıtlı bulunan n değeri ile eşleşip
eşleşmediğini, düğüm sayısını sayarak bulur. Döndürdüğü değer
yoktur, ancak, hesapladığı boyut, n değeri ile eşleşmiyorsa, bir istisna fırlatır.
144|
Alıştırma 3.6. önceyeEkle() işleminin kodunu, u düğümünü oluşturarak, w düğümünden hemen önce, ÇBListe’ye ekleyecek şekilde
yeniden yazın. Bu bölümden alıntı yapmayın. Kodunuz tam olarak
bu kitapta verilen kod ile eşleşmiyor olabilir. Bu, kodun doğru olmadığı anlamına gelmez. Çalışıp çalışmadığını test ederek görün.
Bundan sonraki birkaç alıştırma, ÇBListe üzerinde yapılabilecek
değişiklikleri içeriyor. Herhangi bir yeni düğüm veya geçici dizi
tahsis etmeden, bunları tamamlamanız gerekiyor. Sadece mevcut
düğümlerin, önceki ve sonraki değerlerini değiştirerek bu alıştırmaları yapabilirsiniz.
Alıştırma 3.7. Liste bir palindrom olduğunda true döndüren
palindromu()
adında bir ÇBListe işlemini uygulayın. Her
için, i konumundaki eleman, n – i – 1 konumunda-
ki elemana eşit olmalıdır. Kodunuz O(n) zamanda çalışmalıdır.
Alıştırma
3.8.
ÇBListe
elemanYerDeğiştir(r)
elemanlarının
yerlerini
değiştiren,
işlemini uygulayın. Bu işlemi uygularken, i
konumundaki liste elemanının yeri, (i + r) mod n konumunda olacak şekilde yer değişmelidir. İşlem O(1 + min{r, n – r}) zamanda
çalışmalıdır.
Alıştırma 3.9. ÇBListe’nin i konumundan itibaren liste içeriğini
kısaltan, içeriğiKısalt(i) işlemini uygulayın. Bu işlemi çalıştırdıktan
sonra, listenin boyutu i olacak şekilde belirlenmeli, ve sadece 0,…,i
– 1
endekslerinde bulunan elemanları içermelidir. i,…,n – 1 en-
| 145
dekslerinde bulunan elemanları başka bir ÇBListe halinde döndürmelidir. İşlem O(min {i, n – i}) zamanda çalışmalıdır.
Alıştırma 3.10. ÇBListe arayüzüne ait em(l2) işlemini uygulayın.
Bu işlem, ÇBListe türünde l2 argümanını alır, ve bu listeyi temizleyerek sırasıyla içeriğini, onu çağıran listeye ekler. Örneğin, l1 elemanları a, b, c, ve l2 elemanları d, e, f olursa, l1.em(l2) çağrıldıktan sonra l1 içeriği a, b, c, d, e, f olarak ve l2 içeriği boş şekilde
dönmelidir.
Alıştırma 3.11. ÇBListe arayüzüne ait tekliEndeksElemanları()
işlemini uygulayın. Bu işlem, listenin tek sayılı endekslerinde bulunan elemanları ortadan kaldırır ve bu elemanları bir başka
ÇBListe
halinde döndürür. Örneğin, l1 elemanları a, b, c, d, e, f
olursa, l1.tekliEndeksElemanları() çağrıldıktan sonra l1 elemanları
a, c, e olmalı ve elemanları b, d, f olan bir liste dönmelidir.
Alıştırma 3.12. ÇBListe arayüzüne ait ters() işlemini uygulayın.
Bu işlem, liste elemanlarını ters sırada yeniden yapılandırır.
Alıştırma 3.13. Bu alıştırma, Birleştirerek-Sıralama Bölümü’nde
tartışıldığı gibi, ÇBListe elemanlarını sıralayan bir birleştirmesıralama algoritmasının uygulamasını tanıtıyor. Elemanları karşılaştırmak için karşılaştır(x) işlemini kullanıyoruz, böylece Karşılaştırılabilir
ÇBListe’yi
arayüzünü uygulayan elemanları içeren herhangi
sıralamak mümkündür.
146|
1.
l2
ilkiniSeç(l2)
adında bir ÇBListe işlemini uygulayın. Bu işlem,
listesinin başında bulunan düğümü alır, ve alıcı listesine ekler.
Boş bir liste ile başlanmadığı takdirde, bu işlem, ekle(boyut(),
l2.sil(0)) çağrısının
2.
ÇBListe
eşdeğeri olan bir sonuç döndürür.
arayüzüne ait, birleştir(l1, l2) statik işlemini uygula-
yın. Bu işlem, l1 ve l2 sıralı listelerini birleştirir, ve sıralı yeni listeyi döndürür. Bu süreç sonunda l1 ve l2 listelerinin içeriği boş hale
gelir. Örneğin l1 elemanları a, c, d ve l2 elemanları b, e, f olursa,
bu işlem a, b, c, d, e, f içeren yeni bir liste döndürür.
3.
Listenin elemanlarını birleştirme-sıralama algoritmasını kulla-
narak sıralayan sırala() işlemini uygulayın. Özyinelemeli algoritma
ile şöyle gerçekleştirebilirsiniz:
a. Liste boyutu, 0 veya 1 eleman ise, hiçbir şey yapmayın.
Diğer durumlarda,
b. içeriğiKısalt(boyut() / 2) işlemini kullanarak listeyi yaklaşık olarak eşit uzunlukta olan iki listeye l1, l2 halinde bölün.
c. Özyinelemeli olarak l1 listesini sıralayın.
d.
Özyinelemeli olarak l2 listesini sıralayın, ve en sonunda;
e. l1, l2 listelerini tek sıralı liste halinde birleştirin.
Sonraki birkaç alıştırma daha zordur. Yığıt veri yapısında depolanan
minimum değere erişme, ekleme ve silme işlemleri sırasında Kuyruk’a neler olduğuna dair
net bir anlayış gereklidir.
Alıştırma 3.14. MinYığıt veri yapısına ait yığ(x), yığıttan_kaldır(),
ekle(x), sil(),
ve min() işlemlerini tasarlayın ve uygulayın. min()
| 147
işlemi, halihazırda veri yapısında bulunan en küçük değere sahip
elemanı döndürür. MinYığıt içinde depolanan elemanlar kıyaslanabilir özellikte olmalıdır. Bütün işlemler sabit zamanda çalışmalıdır.
Alıştırma 3.15. MinKuyruk veri yapısına ait ekle(x), sil(), boyut(),
ve min(x) işlemlerini tasarlayın ve uygulayın. min(x) işlemi, halihazırda veri yapısında bulunan en küçük değere sahip elemanı döndürür. MinKuyruk içinde depolanan elemanlar kıyaslanabilir özellikte olmalıdır. Bütün işlemler sabit amortize zamanda çalışmalıdır.
Alıştırma 3.16. MinİkiBaşlıKuyruk veri yapısına ait ekleİlk(x),
ekleSon(x), ilkiniSil(), sonuncuyuSil(), boyut(),
ve min() işlemle-
rini tasarlayın ve uygulayın. min() işlemi, halihazırda veri yapısında
bulunan
en
MinİkiBaşlıKuyruk
küçük
değere
sahip
elemanı
döndürür.
içinde depolanan elemanlar kıyaslanabilir özel-
likte olmalıdır. Bütün işlemler sabit amortize zamanda çalışmalıdır.
Sonraki alıştırmalar, alan-verimli AVListe’nin uygulanması ve analizi hakkında okuyucunun anlayışını test etmek için hazırlanmıştır.
Alıştırma 3.17. AVListe veri yapısı bir Yığıt gibi kullanılırsa, (böylelikle AVListe’ye tek değişiklik yığ(x) => ekle(boyut(), x), ve
yığıttan_kaldır() => sil(size() – 1)
olursa), bu işlemler b değerin-
den bağımsız olarak, sabit amortize zamanda çalışır.
148|
Alıştırma 3.18. İki Başlı Kuyruk işlemlerinin tümünü, b değerinden bağımsız olarak, işlem başına sabit amortize zamanda destekleyen bir AVListe versiyonunu tasarlayın ve uygulayın.
Alıştırma 3.19. Sadece bitsel–veya işlecini, ^ kullanarak, iki int
tamsayı değişken değerini, çüncü bir değişken kullanmadan nasıl
değiş-tokuş edeceğinizi açıklayın.
| 149
150|
Bölüm 4
Sekme Listeleri
Bu bölümde, çeşitli uygulamaları olan, biçimli bir veri yapısını
tartışacağız: sekme listeleri. Liste veri yapısını kullanarak sekme
listesini uyguladığınızda, al(i), belirle(i, x), ekle(i, x), ve sil(i)
işlemlerini, O(log n) zamanda çalıştırabilirsiniz. Ayrıca Sıralı Küme
uygulamasıyla, bütün işlemler O(log n) beklenen zamanda çalı-
şır.
Sekme listelerinin etkinliği, dayandığı rasgelelikten kaynaklanır.
Yeni bir elemanı sekme listesine eklerken, elemanın yüksekliğini
belirlemek için, rasgele yazı-tura atılır. Sekme listelerinin performansı, beklenen çalışma zamanları ve yol uzunlukları cinsinden
ifade edilir. Bu beklenti, sekme listesi tarafından kullanılan rasgele
yazı-tura fırlatışları üzerinden hesaplanır. Rasgele yazı-tura atma,
yarı-rasgele sayı (veya bit) üretecini kullanarak gerçekleştirilir.
| 151
Temel Yapı
Kavramsal olarak sekme listesi, L0,…,Lh tekli-bağlantılı listelerden
oluşan bir dizidir. Her Lr listesi Lr-1 listesinin içindeki elemanların
bir alt kümesini içerir. n eleman içeren, L0 giriş listesi ile başlanır.
Bunu takiben, L1 listesini L0 elemanlarından, L2 listesini L1 elemanlarından, ve buna benzer şekilde diğer listeleri oluştururuz. Lr listesinin elemanlarını oluştururken, Lr-1 listesinde bulunan her x elemanı için yazı-tura atılır. Yazı gelirse, x dahil edilir. Boş bir Lr listesi ile karşılaşıldığında süreç sonlanır. Örnek bir sekme listesi Şekil 4.1 'de gösterilmiştir.
Sekme listesinin içinde yer alan bir x elemanının yüksekliği, bu
elemanın bulunduğu Lr listesinin en büyük r değeri ile ölçülür. Buna göre, örneğin, sadece L0’da görünen elemanlar, 0 yüksekliğe
sahiptir. Birkaç dakikamızı bu konuda düşünmeye ayırırsak, x'in
yüksekliği aşağıdaki deney ile belirlenir: Tura gelene kadar ard
arda yazı-tura atın. Kaç defa yazı geldi? Cevap, şaşırtıcı olmayacağı üzere, bir düğümün beklenen yüksekliği 1'dir (Tura gelmeden
152|
önce iki kez yazı-tura atmayı bekliyoruz, ancak son atışı saymıyoruz). Bir sekme listesinin yüksekliği, en yüksek düğümünün yüksekliğidir.
Her listenin başında, bu liste için bir dummy düğüm gibi davranan
ve başlangıç olarak adlandırılan özel bir düğüm vardır. Sekme listelerinin anahtar özelliği, Lh listesinin başlangıcından L0 listesindeki
tüm düğümlere, arama yolu olarak adlandırılan kısa bir yol olmasıdır. Bir u düğümü için arama yolunun nasıl düzenleneceğini hatırlamak kolaydır (bkz. Şekil 4.2): Sekme listesinin sol üst köşesinden (Lh listesinin başlangıcı) başlayın, ve u düğümünü aşmadığınız
sürece her zaman sağa doğru gidin. Aşağıdaki listeye inip getirmeniz için, her seferinde aşağı yönde bir adım atmanız gerekir.
Daha kesin bir ifadeyle, L0 listesi içindeki u düğümüne bir arama
yolunu oluşturmak için, Lh listesinin w başlangıcından yola çıkarız.
Sonra, w.next incelenir. Eğer w.next içinde L0 içindeki u düğümünden önce görünen bir eleman varsa, o zaman w = w.next olarak belirlenir. Aksi takdirde, bir alt listeye geçilir, ve Lh-1 listesinin
w
yerinden aramaya devam ederiz. L0 içindeki u düğümünün bir
öncesine ulaşıncaya kadar, bu şekilde devam ediyoruz.
| 153
Sekme Listelerinin Analizi Bölümü’nde ispat edeceğimiz aşağıdaki
sonuç, arama yolunun oldukça kısa olduğunu göstermektedir:
Önerme 4.1. L0 içindeki herhangi bir u düğümü için arama yolunun beklenen uzunluğu en fazla, 2log n + O(1) = O(log n) olarak
hesaplanır.
Bir sekme listesini gerçekleştirmenin alan-verimli yolu, veri değeri,
x,
ve bir işaretçi dizisi olan sonraki’ne sahip u düğümlerini tanım-
lamaktır. u.sonraki[i], L1 listesi içinde, u düğümünden sonra gelene
işaret etmelidir. Böylece, bir düğümdeki x verisi, birden fazla listede yer alsa bile, x sadece bir referansla depolanır.
154|
Sonraki iki bölüm sekme listelerinin iki farklı uygulamasını tartışıyor. Bu uygulamaların her birinde, L0, ana yapıyı depolar (bir eleman listesi veya sıralı bir küme eleman). Bu yapılar arasındaki temel fark, bir arama yolu üzerinden nasıl yol alındığıdır; özellikle
Lr-1’e
inileceği mi, yoksa Lr içinde sağa doğru mu gidileceği konu-
sunda karar vermede ayrılık gösterirler.
| 155
Sıralı Küme Sekme Listesi: Verimli bir Sıralı Küme
Sıralı Küme Sekme Listesi, Sekme Listesi
Sıralı Küme
veri yapısını kullanarak
arayüzünü uygular. L0 listesi Sıralı Küme elemanlarını
sıralı bir şekilde depolamaya yarar. bul(x) işlemi y ≥ x olan en
küçük y değeri için, arama yolunu izler.
y
için arama yolunu izlemek kolaydır: Lr içinde bir u düğümüne
rastladığımızda, sağdaki u.next[r].x verisine dikkat ederiz. Eğer x
> u.next[r].x
ise, Lr içinde sağa doğru bir adım atarız; aksi takdir-
de, Lr-1 yönünde aşağı doğru hareket ederiz. Bu arama sırasında
atılan her adım (sağa veya aşağı doğru) sadece sabit zaman alır;
böylece, Önerme 4.1 ile, bul(x) işlemi O(log n) beklenen çalışma
zamanında çalışır.
156|
Bir eleman eklemeden önce yeni bir düğümün yüksekliği olan, k,
Sıralı Küme Sekme Listesi
tarafından hesaplanmalıdır. Bu amaçla
yazı-tura atmak için bir işlem bulunmalıdır. Bir rasgele tamsayı, z,
seçerek bunu yapabiliriz. Bunun için, ikili moddaki z sayısının sondan gelen 1 bitleri sayılır:
Sıralı Küme Sekme Listesi
içinde ekle(x) işlemini uygulamak için
önce x aranır, ve yükseklikSeç() işlemi kullanılarak k belirlenir.
Bunu takiben L0,...,Lk listeleri x için uç uça birbirine bağlanır. Bunu yapmanın en kolay yolu, arama yolunun Lr listesinden Lr-1 listesine indiği düğümlerin izlerini kaydeden bir Dizi Yığıt kullanmaktır.
Daha kesin bir ifadeyle, yığıt[r], arama yolunun Lr-1 listesine indiği
Lr
düğümüdür. x eklenirken değiştirilen düğümler, tam olarak,
yığıt[0]…yığıt[k]
tarafından kaydedilir.
| 157
x
elemanını silmek benzer şekilde yapılır, ancak burada arama yo-
lunu takip etmek için yığıt’a gerek duyulmaz. Arama yolu takip
edilirken, aynı anda silme yapılabilir. x elemanını bulmak için yapılan arama sırasında, bir u düğümünden aşağıya doğru yapılan her
harekette, u.next.x = x eşitliği kontrol edilir; sağlanması durumunda, u bir sonraki düğüme listenin dışına doğru uç uça bağlanır.
158|
| 159
Özet
Aşağıdaki teorem Sıralı Küme kullanılarak gerçekleştirilen Sekme
Listesi’nin
performansını özetlemektedir:
Teorem 4.1. Sıralı Küme Sekme Listesi, Sıralı Küme arayüzünü
uygular. Sıralı Küme Sekme Listesi, işlem başına O(log n) beklenen zamanda çalışan ekle(x), sil(x) ve bul(x) işlemlerini destekler.
160|
Liste Sekme Listesi: Verimli Rasgele
Erişim Listesi
Liste Sekme Listesi,
Liste
bir Sekme Listesi veri yapısını kullanarak
arayüzünü uygular. Liste Sekme Listesi’nde, L0 listesi, ele-
manları listede göründükleri sırayla depolar. Sıralı Küme Sekme
Listesi’nde
olduğu gibi, elemanlar O(log n) zamanda eklenir, çıka-
rılır ve erişilebilir.
Bunun mümkün olabilmesi için, i'nci elemana erişmek için gerekli
arama yolunu takip etmemiz için bir yol bulmamız gerekir. Bunu
yapmanın en kolay yolu herhangi bir Lr listesi için kenar uzunluğu
kavramını tanımlamaktır. L0 içindeki her kenarın uzunluğu 1 olarak
tanımlanır. r > 0 olacak şekilde Lr listesindeki, e kenarının uzunluğu Lr-1 içindeki e kenarının altında yer alan uzunlukların toplamı
olarak tanımlanmaktadır. Aynı anlama gelecek şekilde, e uzunluğu
e
altında yer alan L0 kenarlarının sayısıdır. Kenar uzunluklarının
gösterildiği bir sekme listesi örneği için bkz. Şekil 4.5. Sekme listelerinin kenarları dizilerde depolandığı için, uzunlukları aynı şekilde
depolanabilir.
| 161
Bu uzunluk tanımının kullanışlı bir özelliği, eğer şu anda L0 içinde j
pozisyonunda yer alan düğümde bulunuyorsak, ve l uzunluğunda
bir kenarı izliyorsak, L0 içinde j + l konumundaki bir düğüme ulaşabiliriz. Bu şekilde, bir arama yolunu takip ederken, L0 içindeyken
bulunduğumuz düğümün j pozisyonunu takip edebiliriz. Lr içindeki
bir u düğümünde isek, j + u.next[r] kenarının uzunluğu i’den küçükse, sağa doğru gideriz. Aksi takdirde, Lr-1 içinde aşağı doğru
gideriz.
162|
al(i)
ve belirle(i, x) işlemlerinin en zor kısmı, L0 içindeki i’nci dü-
ğümü bulmak olduğu için, bu işlemler O(log n) zamanda çalışır.
Liste Sekme Listesi
içindeki i konumuna bir eleman eklemek ol-
dukça kolaydır. Sıralı Küme Sekme Listesi’nin aksine, burada yeni
bir düğümün muhakkak ekleneceğinden eminiz. Ekleme, yeni düğümün konumunu ararken aynı zamanda gerçekleştirilebilir. Önce
yeni eklenen w düğümünün yüksekliği olan k seçilir, ve sonra i için
arama yolu izlenir. Ne zaman ki arama yolu, r ≤ k olmak üzere, Lr
’dan aşağı doğru giderse, w için Lr uç uça birleştirilir. Sadece kenar
| 163
uzunluklarının düzgün olarak güncellendiğinden emin olmak için
özen göstermemiz gerekiyor. Bkz. Şekil 4.6.
Unutmayın ki, Lr içindeki bir u düğümünden itibaren başlayan arama yolu, ne zaman aşağı doğru giderse, u.next [r] kenar uzunluğu
1 artırılır, çünkü i konumundaki kenarın altına yeni bir eleman ekliyoruz. w düğümü için listelerin u ve z olarak uç uça birleştirilmesi, Şekil 4.7’de gösterildiği gibi çalışır. Arama yolu takip edilirken
L0 içindeki u düğümünün j pozisyonu takip edilmektedir. Bu ne-
denle, u düğümünden w düğümüne kenar uzunluğunun i – j olduğunu biliyoruz. Bunun yanı sıra, aynı zamanda, w düğümünden z
düğümüne uzanan kenar uzunluğunu, u düğümünden z düğümüne
kenar uzunluğu olan l’ye bakarak çıkarsayabiliriz. Bu nedenle, listeler w için uç uça birleştirilir ve kenar uzunlukları sabit zaman
içinde güncellenir.
164|
Kod oldukça basit olduğu için, bu anlatılanlar size olduğundan daha karmaşık gelmiş olabilir:
Artık, Liste Sekme Listesi’nde sil(i) işleminin gerçekleştirimi açık
hale geldi. Düğüm için, i konumundaki arama yolu izlenir. Arama
yolu, bir u düğümünden aşağı r seviyesinde her adım attığında, u
| 165
aynı seviyede kalacak şekilde kenar uzunluğu azaltılır. Aynı zamanda, u.next[r] değerinin i’yi gösterip göstermediği kontrol edilir, ve gösteriyorsa listeler o seviyede uç uça birleştirilir. Bir örnek
Şekil 4.8'de gösterilmiştir.
166|
| 167
Özet
Aşağıdaki teorem Liste Sekme Listesi veri yapısının performansını
özetlemektedir:
Teorem 4.2. Liste Sekme Listesi, Liste arayüzünü uygular. Liste
Sekme Listesi,
işlem başına O(log n) beklenen zamanda çalışan
al(i), belirle(i, x), ekle(i, x)
ve sil(i) işlemlerini destekler.
168|
Sekme Listelerinin Analizi
Bu bölümde, Sekme Listesi içindeki arama yolunun beklenen yüksekliği, boyutu ve uzunluğunu analiz edeceğiz. Bu bölüm, temel
olasılık konusunda bir miktar bilgi birikiminizin var olmasını gerektirir. Yazı-tura atma ile ilgili aşağıdaki gözlem, çeşitli kanıtlamalar için bir temel oluşturmaktadır.
Önerme 4.2. T adil bir paranın fırlatıldıktan sonra ilk defa yazı
geldiği zamana kadar olan atma sayısı olsun. O zaman E[T] = 2
olarak hesaplanır.
Kanıt. İlk defa yazı geldiği zaman yazı-tura atmayı durduğumuzu
düşünelim.
Gösterge değişkeni tanımlayın:
Unutmayın ki, ancak ve ancak ilk i – 1 yazı-tura sonucu yazı geldiği takdirde, Ii=1 sağlanır, bu nedenle,
olarak hesaplanır. Gözlemlemelisiniz ki, T, toplam yazı-tura atma
sayısı
ile verilir. Bu nedenle,
| 169
Sonraki iki önerme, sekme listelerinin doğrusal boyutta olduğunu
bize anlatıyor:
Önerme 4.3. n eleman içeren bir sekme listesinin başlangıç düğümleri dışında kalan beklenen düğüm sayısı 2n olarak hesaplanır.
Kanıt. Belirli bir x elemanının, Lr listesi tarafından depolanma olasılığı 1 / 2r, bu nedenle, Lr içindeki düğümlerin beklenen sayısı
n / 2
r
olarak hesaplanır. Böylece, tüm listelerde bulunan düğümle-
rin beklenen toplam sayısı,
Önerme 4.4. n eleman içeren bir sekme listesinin beklenen yüksekliği, log n + 2 olarak hesaplanır.
170|
Kanıt. Her
için gösterge rasgele değişkenini aşa-
ğıdaki gibi tanımlayın:
Sekme listesi yüksekliği, h,
olarak verilir. Unutmayın ki, Ir değeri Lr uzunluğu olan |Lr|’dan
asla daha fazla olamaz, bu nedenle,
olarak hesaplanır. Aşağıdaki hesaplama kanıtı tamamlar:
| 171
Önerme 4.5. Tüm başlangıç düğümlerinin de içerildiği, n elemanı
depolayan
bir
2n + O(log n)
sekme
listesinin
beklenen
düğüm
sayısı,
olarak hesaplanır.
Kanıt. Önerme 4.3 ile belirtilmiştir ki, başlangıç düğümleri dışında
kalan düğümlerin beklenen sayısı 2n olarak hesaplanır. Başlangıç
düğümlerinin sayısı sekme listesinin yüksekliği olan, h, ile verilir.
Böylece Önerme 4.4 ile belirtilmiştir ki, başlangıç düğümlerinin
beklenen sayısı en fazla log n + 2 = O(log n) olarak hesaplanır.
Önerme 4.6. Bir sekme listesinin beklenen arama yolu uzunluğu en
fazla 2 log n + O(1) olarak hesaplanır.
Kanıt. Bunu görmek için en kolay yol, bir x düğümü için ters arama yolunu ele almaktır. Bu yol L0 içindeki x düğümünden önce
gelen düğümle başlar. Zamanla herhangi bir noktada, eğer yol bir
seviye yukarı gidebilirse, gider. Bir seviye yukarı çıkamıyorsa o
zaman sola doğru gider. Birkaç dakika için düşünülürse, bu ters
arama yolunun, ters olması dışında x için arama yolu ile aynı olması anlaşılır.
Belirli bir r seviyesinde, ters arama yolu tarafından ziyaret edilen
düğümlerin sayısı aşağıdaki deney ile ilgilidir: Yazı-tura atın. Yazı
gelirse, yukarı doğru gidin ve durun. Aksi takdirde, sola doğru hareket edin ve deneyi tekrarlayın. Yazı gelmeden önceki yazı-tura
atma sayısı, bir ters arama yolunun, belirli bir seviyede sola doğru
172|
attığı adımların sayısını temsil eder. Önerme 4.2, ilk defa yazı
gelmeden önceki beklenen yazı-tura atma sayısının 1 olduğunu
bildirmiştir. r seviyesinde ileri yöndeki arama yolunun sağa doğru
attığı adım sayısının Sr ile gösterildiğini düşünelim. Az önce tartışıldığı gibi, E[Sr] ≤ 1. Ayrıca, Lr içinde Lr uzunluğundan daha fazla
adım atamayacağımıza göre, Sr ≤ |Lr|, bu nedenle,
Böylece şimdi, Önerme 4.4.’ün kanıtında olduğu gibi, bitirebiliriz.
Sekme listesindeki bir u düğümü için arama yolunun uzunluğu S,
ve sekme listesinin yüksekliği h olsun.
Bu durumda,
| 173
Aşağıdaki teorem bu bölümdeki sonuçları özetlemektedir:
Teorem 4.3. n eleman içeren bir sekme listesinin beklenen boyutu
O(n) ve herhangi bir eleman için arama yolunun beklenen uzunlu-
ğu en fazla 2log n + O(1) olarak hesaplanır.
174|
Tartışma ve Alıştırmalar
Sekme listeleri Pugh [62] tarafından, uygulama ve uzantıları [61]
dahil olmak üzere tanıtılmıştır. O tarihten bu yana yoğun çalışmalar
yapılmıştır. Çeşitli araştırmacılar i’nci eleman için arama yolunun
beklenen uzunluğu ve değişkenleri üzerine çok detaylı analizler
yapmıştır [45, 44, 58]. Deterministik [53], taraflı [8, 26], ve kendini
belirleyen sekme listeleri [12] geliştirilmiştir. Sekme listeleri uygulamaları çeşitli diller ve çerçeveler için yazılmıştır ve açık kaynak
veritabanı sistemlerinde kullanılmaktadır [71, 63]. Sekme listelerinin bir benzeri HP-UX işletim sistemi çekirdeğinin süreç yönetim
yapılarında kullanılmaktadır [42]. Sekme listeleri aynı zamanda
Java API 1.6 [55] versiyonunun bir parçasıdır.
Alıştırma 4.1. Şekil 4.1'deki sekme listesi üzerinde 2.5 ve 5.5 elemanları için arama yollarını gösterin.
Alıştırma 4.2. Şekil 4.1'deki sekme listesi üzerinde 0.5 (1 yüksekliğe sahip) ve 3.5 (2 yüksekliğe sahip) değerlerinin toplamasını
gösterin.
Alıştırma 4.3. Şekil 4.1'deki sekme listesi üzerinde 1 ve 3 değerlerinin silinmesini gösterin.
Alıştırma 4.4. Şekil 4.5’deki Liste Sekme Listesi üzerinde sil(2)
işleminin çalıştırılmasını gösterin.
| 175
Alıştırma 4.5. Şekil 4.5’deki Liste Sekme Listesi üzerinde ekle(3,
x)
işleminin çalıştırılmasını gösterin. Varsayın ki, yeni oluşturulan
düğüm için yükseklikSeç() fonksiyonu yükseklik değeri olarak 4
seçsin.
Alıştırma 4.6. ekle(x) ve sil(x) işlemleri sırasında Liste Sekme
Listesi
içindeki değişen işaretçilerin beklenen sayısının sabit oldu-
ğunu gösterin.
Alıştırma 4.7. Diyelim ki, bir elemanı yazı-tura atışımızın sonucuna göre Li-1 listesinden Li listesine geçirmek yerine, bunu
p
1.
Bu değişiklik ile, bir arama yolunun beklenen uzunluğunun en
fazla
1
olan p olasılığı ile gerçekleştiriyoruz.
0
olduğunu gösterin.
2.
Önceki ifadeyi minimize eden p değeri nedir?
3.
Sekme listesinin beklenen yüksekliği nedir?
4.
Sekme listesinin beklenen düğüm sayısı nedir?
Alıştırma 4.8. Sıralı Küme Sekme Listesi bul(x) işlemi bazen gereksiz karşılaştırmalar gerçekleştirir; x aynı değerle kıyaslandığında
bunlar oluşabilir. Bir u düğümü için u.next [r] = u.next [r - 1]
olduğunda bunlar oluşur. Bu gereksiz karşılaştırmaların nasıl oluştuğunu gösterin, ve oluşmalarını engellemek için bul(x) gerçekleştiriminde değişiklikler yapın. Değiştirilmiş bul(x) işlemi tarafından
yapılan karşılaştırmaların beklenen sayısını analiz edin.
176|
Alıştırma 4.9. Sıralı Küme arayüzünü uygulayan, ama aynı zamanda derecesine göre elemanlara hızlı erişim sağlayan bir sekme
listesi versiyonunu tasarlayın ve uygulayın. Bu veri yapısı, i dereceli elemanı döndüren al(i) fonksiyonunu, O(log n) beklenen zamanda çalıştırmalıdır (Sıralı Küme’de yer alan bir x elemanının derecesi x değerinin altındaki eleman sayısıdır).
Alıştırma 4.10. Bir sekme listesinde parmak, arama yolunun indiği
arama yolu üzerindeki düğüm sırasını depolayan bir dizi olarak
tanımlanır (bu bölümdeki ekle(x) kodundaki yığıt değişkeni bir
parmaktır; Şekil 4.3'deki kırmızı ile boyalı düğümler parmak içeriğini göstermektedir). Bir parmağın en alttaki, L0 listesindeki bir
düğüme ait arama yoluna işaret ettiğini düşünebilirsiniz.
Parmak araması, u.x < x ve (u.next = null veya u.next.x > x) olan
bir u düğümüne ulaşana kadar, listeden yukarı doğru yürüyerek
parmağı kullanır, ve sonra u düğümünden başlayarak, x için normal
bir arama yaparak bul(x) işlemini uygular. L0 içinde depolanan x,
ve parmak ile işaret edilen değer arasındaki sayı değerleri r ise, bir
parmak araması için gerekli adımların beklenen sayısının O(1 +
log r)
olduğunu kanıtlamak mümkündür.
Sekme Listesi’nin
bul(x)
bir alt sınıfı olan ve içsel bir parmak kullanarak
işlemini uygulayan Parmak İle Sekme Listesi’ni gerçekleş-
tirin. Bu alt sınıf, daha sonra her bul(x) işlemini bir parmak araması
olarak gerçekleştiren bir parmak depolar. Her bul(x) işlemi sırasında başlangıç noktası olarak, önceki bul(x) işleminin sonucuna işa-
| 177
ret eden bir parmak kullanılacak şekilde parmak güncelleştirilmesi
yapılır.
Alıştırma 4.11. Liste Sekme Listesi’nin i pozisyonunda liste içeriğini kısaltan içeriğiKısalt(i) adında bir işlem uygulayın. Bu işlemi
çalıştırdıktan sonra, listenin boyutu i olacak şekilde belirlenmeli ve
sadece 0,…,i – 1 endekslerinde bulunan elemanları içermelidir.
i,…,n – 1
endekslerinde bulunan elemanları içeren bir başka Liste
Sekme Listesi
döndürmelidir. İşlem O(log n) zamanda çalışmalı-
dır.
Alıştırma 4.12. Liste Sekme Listesi arayüzüne ait em(l2) işlemini
uygulayın. Bu işlem Liste Sekme Listesi türünde bir l2 argümanı
olarak alır, bu liste elemanlarını temizleyerek, sırasıyla içeriğini
onu çağıran listeye ekler. Örneğin, l1 elemanları a, b, c ve l2 elemanları d, e, f olursa, l1.em(l2) çağrısı yapıldıktan sonra l1 içeriği
a, b, c, d, e, f ve l2 içeriği boş olarak döndürülmelidir. Bu işlemin
çalışma zamanı O(log n) olmalıdır.
Alıştırma 4.13. Alan Verimli Liste, AVListe fikirlerinden yola çıkarak, ve Sıralı Küme veri yapısını kullanarak, Alan Verimli Sıralı
Küme, AVSKüme’yi
tasarlayın ve uygulayın. Bunu gerçekleştirmek
için, veri elemanlarını sıralı bir şekilde AVListe’de, ve AVListe
bloklarını da Sıralı Küme’de depolayın. Orijinal Sıralı Küme uygulaması, n elemanı saklamak için, O(n) alan kullanıyorsa,
AVSKüme, n
O(n/b + b)
eleman için yeterli olan alanı ve buna ek olarak
miktarında bir alan kullanacaktır.
178|
Alıştırma 4.14. Temel yapı olarak, Sıralı Küme kullanarak (büyük) bir metin dosyasını okuyan ve metinde yer alan herhangi bir
alt dize için, etkileşimli arama yapmanızı sağlayan bir uygulama
tasarlayın ve uygulayın. Kullanıcı sorgusunu yazdıkça, eş metnin
parçası, eğer varsa, sonuçta görünmelidir.
İpucu 1: Her altdize bazı sonek’in önekidir. Bu nedenle metin dosyasının tüm sonek’lerini depolamak yeterlidir.
İpucu 2: Herhangi bir sonek, kısa ve etkili bir şekilde, ek’in metinde nerede başladığını gösteren bir tamsayı ile temsil edilebilir.
Gutenberg Projesinde [1] mevcut kitaplardan bazılarında yer alan
büyük metinler üzerinde uygulamanızı test edin. Eğer doğru uygulanırsa, tuş vuruşlarını yazarken hiçbir gecikme olmadan sonuçları
görebilmelisiniz.
Alıştırma 4.15 (Bu alıştırma Serbest Yükseklikli İkili Arama Ağacı
Bölümü’ndeki ikili arama ağaçları konusu okunduktan sonra yapılmalıdır). İkili arama ağaçları ile sekme listelerini aşağıdaki şekillerde karşılaştırın:
1.
Bir sekme listesinin bazı kenarları silindiğinde, ikili ağaç gibi
görünen ve ikili arama ağacına benzer bir yapı haline nasıl dönüştüğünü açıklayın.
| 179
2.
Sekme listeleri ve ikili arama ağaçlarının her ikisi de yaklaşık
aynı sayıda (düğüm başına 2) işaretçi kullanıyor. Oysa ki, sekme
listeleri bu işaretçilerden daha iyi yararlanmaktadır. Neden? Açıklayın.
180|
| 181
Bölüm 5
Karma Tabloları
Karma tabloları, geniş bir U = {0,…,2w – 1} kümesinden az sayıda
n
tamsayısını depolamak için etkili bir yöntemdir. Karma tablosu
terimi, geniş bir yelpazedeki çeşitli veri yapılarını içerir. Bu bölümde, karma tablolarının en yaygın bir uygulaması olan, zincirleme ile karma yöntemi üzerinde duracağız.
Çok sıklıkla, karma tabloları, tamsayı olmayan veri türlerini içerir.
Bu durumda, her veri elemanı, ayrı bir tamsayı karma kodu ile ilişkilendirilerek tabloda kullanılır. Bu gibi karma kodların nasıl oluşturulduğunu bölümün ikinci kısmında tartışacağız.
Kullanılan bazı yöntemler, belirli bir aralıktaki tamsayılar arasından rasgele seçim yapmamızı gerektirir. Verilen kod örneklerinde,
bu "rasgele" tamsayılar, hava seslerinden oluşturulan rasgele bitler
kullanılarak elde edilen, kodlanmış sabitler olacaktır.
182|
Zincirleme Karma Tablo: Zincirleme İle
Adresleme
Zincirleme Karma Tablo
veri yapısı, zincirleme ile karma yöntemi-
ni kullanarak, verileri, t listelerinden oluşan bir dizi halinde depolar. n tamsayısı, tüm listelerdeki toplam eleman sayısını tutar (bkz.
Şekil 5.1):
x
veri elemanının karma değeri hash(x) ile belirtilir, ve
{0,…,t.uzunluk – 1}
aralığından bir değerdir. i karma değerine
sahip tüm elemanlar listede t[i] konumunda depolanır.
Liste uzunluğunu çok büyültmemek için şu değişmez geçerlidir:
| 183
Böylece, bu listelerden birinde depolanan elemanların ortalama
sayısı n/t.uzunluk ≤ 1 olarak hesaplanır.
x
elemanını karma tabloya eklemek için, önce t uzunluğunu artırıp
artırmamak gerektiğini kontrol ederiz; gerekiyorsa artırırız. x karma kodu {0,…,t.uzunluk – 1} aralığında bulunan bir i tamsayısı
ise, x elemanını t[i] listesine ekleriz.
Tablonun büyültülmesi, gerekirse, t uzunluğunun iki katına çıkmasına, ve tüm elemanların yeni tabloya yeniden eklenmesine yol
açar. Bu strateji, Dizi Yığıt uygulamasında kullanılan strateji ile
birebir örtüşmektedir. Sonuç aynıdır: Amortize büyültme maliyeti,
ekleme işlemi için yapılan çağrılar üzerinden, sadece sabit zaman
alır. (bkz. Önerme 2.1).
Büyültmenin yanı sıra, Zincirleme Karma Tablo’ya yeni bir x değeri eklerken yapılan diğer bir çalışma, t[hash(x)] listesinin sonuna x
elemanını eklemektir. Bölüm 2 veya 3 'de anlatılan herhangi bir
Liste uygulaması
için bu, sadece sabit zaman alır.
184|
Karma tablodan x elemanını silmek için, önce t[hash(x)] listesi
üzerinden ilerlenerek, x elemanı bulunur ve silinir.
Bu işlem O(nhash(x)) zamanda çalışır, ni konumu, t[i] listesinde depolanmış listenin uzunluğunu tutar.
Karma tabloda x elemanı için arama yapmak benzer bir işlemdir.
t[hash(x)]
listesinde doğrusal bir arama gerçekleştirilir:
Bu işlem de yine, t[hash(x)] listesinin uzunluğu ile orantılı zamanda çalışır.
| 185
Karma tablosunun performansı, hash fonksiyonunun seçimi ile
kritik olarak belirlidir. İyi bir karma fonksiyonu, elemanları
t.uzunluk
liste arasında eşit olarak dağıtır, böylece t[hash(x)] liste-
sinin beklenen boyutu O(n/t.uzunluk) = O(1) olarak hesaplanır.
Diğer taraftan, kötü bir hash fonksiyonu tüm değerleri (x içinde
olmak üzere) aynı tablo konumuna karma yapacaktır, bu durumda,
t[hash(x)]
listesinin boyutu n olacaktır. Bir sonraki bölümde iyi bir
karma fonksiyonunu tanımlayacağız.
186|
Çarpımsal Karma Yöntemi
Karma değerlerini oluşturmak için modüler aritmetiğe ve tamsayı
bölünmesine dayanan (bkz. Dizi Kuyruğu: Dizi-Tabanlı Kuyruk
Bölümü) çarpımsal karma, etkili bir yöntemdir. Bölümün tamsayı
kısmını alan ve kalanı önemsemeyen div işlecini kullanır. Her tamsayı a ≥ 0 ve b ≥ 1 için, a div b = a/b olarak yazılabilir.
Çarpımsal karma yöntemi, d, boyut belirten bir tamsayı ise, 2d boyutlu bir karma tablo kullanır.
olan x tamsayısı
için, karma formülü,
olarak verilmiştir.
Burada z,
kümesinden rasgele seçilmiş bir tek tamsa-
yıdır. w bir tamsayının bit sayısı olmak üzere, tamsayılar üzerindeki işlemler, varsayılan olarak, 2w modülo ile yapıldığı için, bu karma fonksiyonu, çok etkin bir şekilde uygulanabilir (bkz. Şekil 5.2).
Ayrıca, tamsayının 2w – d ile bölünmesi ikili tabanda gösterimde en
sağdaki w – d bitten kurtulmayı gerektirir (w – d biti sağa doğru
kaydırınız). Böylece, yukarıdaki formülü uygulayan kod, formülün
kendisinden daha kolay hale gelir:
| 187
Aşağıdaki önerme, çarpımsal karmanın toslamalardan kaçındığını
gösteriyor.
Önerme 5.1.
olmak üzere, 0,…,2w – 1 içindeki iki ayrı değer
x ve y olsun,
Kanıtını ertelediğimiz Önerme 5.1 ile, sil(x) ve bul(x) performanslarını analiz etmek kolaydır:
Önerme 5.2. Herhangi x veri değeri için, t[hash(x)] listesinin beklenen uzunluğu en çok nx + 2 olarak hesaplanır. Karma tabloda x
elemanının yinelenme sayısı nx ile verilmiştir.
Kanıt. x’e eşit olmayan elemanların (çoklu)-kümesi S ile belirtilsin.
yS
için gösterge değişkenini tanımlayın.
Unutmayın ki, Önerme 5.1. ile,
t[hash(x)]
listesinin beklenen uzunluğu,
188|
ile verilir.
Şimdi, Önerme 5.1’i kanıtlamak istiyoruz, ancak sayı kuramına
ihtiyaç duymaktayız. Aşağıdaki kanıtta,
sayısını belirt-
mek için (br,…,b0)2 gösterimini kullanıyoruz. Burada her bi ikili
tabanda 0 veya 1 bitleridir. Bir başka deyişle, (br,…,b0)2 ikili tabanda gösterimi br,…,b0 ile verilen bir tamsayıdır. Bilinmeyen değeri belirten bit için
Önerme 5.3.
kullanıyoruz.
kümesindeki tek tamsayıların kümesi S
olsun; S içindeki herhangi iki eleman q ve i olsun. Bu durumda, z
S
iken
eşitliğini sağlayan sadece bir değer kesin
olarak vardır.
Kanıt. z ve i için eşit sayıda seçim yapılabileceği için,
eşitliğini sağlayan en fazla bir adet z
var olduğunu kanıtlamak yeterlidir.
S
değerinin
| 189
Bir çelişkiyi denemek için, z
z’ olmak
üzere iki ayrı z ve z’ değeri
olduğunu varsayalım.
Bu nedenle,
Bu eşitlik aynı şekilde k tamsayısı için yeniden yazılır:
İkili tabanda gösterilen sayılar açısından düşünüldüğünde,
Böylece (z – z’) q sayısının ikili gösteriminde sondan w bit 0 olarak hesaplanır.
Ayrıca
, ve
olduğu için,
doğrudur. q tek sayı
olduğundan, ikili tabanda gösteriminin son biti 0 olamaz:
olduğu için, z – z’ ikili tabanda gösterimi, w bitten
daha az sayıda 0 bite sahiptir:
190|
Bu nedenle, (z – z’)q çarpımının ikili tabanda gösterimi, w bitten
daha az sayıda 0 bite sahiptir:
Bu nedenle, (z – z’)q (5.1) eşitliğini sağlamaz; çelişki olarak hesaplanır.
Şu gözlemden yararlanırsak, Önerme 5.3 daha iyi anlaşılacaktır: S
içinden Z rasgele seçilirse, zt’nin S üzerindeki dağılımı normaldir.
Aşağıdaki kanıtta, ikili tabanda z gösterimini w – 1 rasgele bitin
ardından gelen 1 biti olarak düşünmek size yardımcı olacaktır.
Önerme 5.1’in Kanıtı. Öncelikle unutmayın ki, hash(x) = hash(y)
koşulu “zx mod 2w sonucunun en-yüksek dereceden d biti, ve zy
mod 2
w
sonucunun en-yüksek dereceden d biti aynıdır.” ifadesine
eşdeğerdir. Bu açıklamanın gerekli koşulu z(x – y) mod 2w sayısının ikili tabanda gösteriminin en yüksek dereceden d biti, ya hep 0,
ya hep 1 olmalıdır. zx mod 2w
veya, zx mod 2w
zy mod 2w iken,
zy mod 2w iken,
| 191
olur. Bu nedenle, z(x – y) mod 2w olasılığını (5.2) veya (5.3)’teki
bağıntılarla ilişkilendirmemiz gerekiyor.
Q,
herhangi bir r tamsayısı için
. koşulunu sağ-
layan benzersiz bir tek tamsayı olsun. Önerme 5.3 ile,
sayısının ikili tabanda gösterimi, w – 1 rasgele bitin ardından gelen
bir 1 biti içerir:
Bu nedenle,
sayısının ikili tabanda
gösterimi, w – r – 1 rasgele bitin ardından gelen bir 1 biti, ve ardından gelen tümü 0 olan bitleri içerir:
Kanıtı şimdi bitirebiliriz: Eğer r > w – d ise,
sayı-
sının en yüksek dereceden d biti, hem 0 ve hem 1’leri içerir, böylece
sayısının (5.2) veya (5.3) gibi görünme olasılığı
0’dır.
Eğer r = w – d ise (5.2) gibi olma olasılığı 0’dır, ancak (5.3)
gibi görünme olasılığı 1/2d-1 = 2/2d olarak hesaplanır (çünkü
b1,…,bd-1 = 1,…,1
doğrudur). Eğer r
w – d
ise, bw
– r – 1,…,
192|
bw – r – d = 0, …, 0,
veya bw – r – 1,…,bw – r – d = 1,…,1 doğrudur. Bu
durumlardan her birinin olasılığı, 1 / 2d, ve ayrışık oldukları için,
her iki durumun olasılığı 2 / 2d olarak hesaplanır.
| 193
Özet
Aşağıdaki teorem Zincirleme Karma Tablo veri yapısının performansını özetlemektedir:
Teorem 5.1. Zincirleme Karma Tablo, Sırasız Küme arayüzünü
uygular. yeniden_boyutlandır() işlemi için yapılan çağrıların maliyeti önemsenmediği takdirde, Zincirleme Karma Tablo, işlem başına O(1) beklenen zamanda çalışan ekle(x), sil(x) ve bul(x) işlemlerini destekler.
Başlangıçta, Zincirleme Karma Tablo elemanları boş değer taşırken, ekle(x) ve sil(x) işlemleri sıralı olarak m defa çağrılırsa, yeniden_boyutlandır()
zamanda çalışır.
işlemi için yapılan tüm çağrılar O(m) toplam
194|
Doğrusal Karma Tablo: Doğrusal Yerleştirme
Doğrusal Karma Tablo
veri yapısında, i’nci listede hash(x) = i
olan tüm x elemanlarını depolayan bir liste dizisi kullanılır. Alternatif olarak, açık adresleme ile elemanlar doğrudan, t, dizisi içindeki her konumda en fazla bir değer olacak şekilde depolanır. Bu
yaklaşım, Doğrusal Karma Tablo tarafından uygulanmıştır. Bazı
yerlerde, bu veri yapısı doğrusal yerleştirme ile açık adresleme olarak tanımlanmaktadır.
Doğrusal Karma Tablo
hash(x) = i
ardında yatan ana fikir, x elemanını
hash değeri ile, ideal olarak t[i] tablo konumunda de-
polamaktır. Zaten orada var olan bir eleman depolandığı için, bu
yapılamıyorsa, t[(i + 1) mod t.uzunluk] konumunda depolanması
beklenir. Bu da mümkün değilse, t[(i + 2) mod t.uzunluk] konumu denenir, ve böylece, x için bir yer bulana kadar devam ederiz.
t
içinde depolanan üç tür girdi vardır:
1. veri değerleri: Sırasız Küme’de depolanan gerçek değerler.
2. null değerler: Hiçbir veri kaydı yapılmamış dizi konumlarında
bulunan değerler.
3. del değerler: Daha önce veri kaydı yapılmış, ancak silinmiş
değerler.
| 195
Doğrusal Karma Tablo’nun
eleman sayısını tutan n yanında, q sa-
yacı 1.tür ve 3.tür elemanların sayısını belirtir. Bunun anlamı, n ve
del
değerlerini taşıyan elemanların toplam sayısı q olur. Bu işi ve-
rimli hale getirmek için, t için ayrılan üst limitin, q değişkeninde
tutulan değerden nispeten çok büyük olması gerekir. Böylece t
içinde ayrılmış pek çok boş değer yeri olmalıdır. Bu nedenle, Doğrusal Karma Tablo
üzerinde yapılan işlemler için t.uzunluk ≥ q
değişmezini sağlar.
Özetlemek gerekirse, veri elemanlarını depolamak için Doğrusal
Karma Tablo, t
dizisini kullanır; n ve q tamsayıları sırasıyla, veri
elemanlarının sayısını ve null-olmayan t değerlerini belirtir. Birçok
karma fonksiyonları sadece 2’nin kuvveti olan eleman sayısına
kadar veri depolayabildiği için, tanımladığımız bir d tamsayısı ile
t.uzunluk = 2
d
değişmezini sağlayabiliriz.
Doğrusal Karma Tablo
hash(x) = i
arayüzüne ait bul(x) işlemi basittir.
olan t[i] dizi konumuyla başlarız. Sırasıyla t[i],
t[(i + 1) mod t.uzunluk], t [(i + 2) mod t.uzunluk]
konumları
aranır, ve böylece, t[i’] = x, veya t[i’] = null koşullarından en az
birini sağlayan bir i’ konumunu bulana kadar arama devam eder.
Bir önceki durum sağlanmışsa, t[i’] elemanını döndürürüz. Sonraki
196|
durum sağlanmışsa, karma tabloda x elemanının bulunmadığı sonucuna varırız ve null değer döndürürüz.
ekle(x)
işlemini uygulamak oldukça kolaydır. Tabloda x elemanı-
nın henüz depolanıp depolanmadığını (bul(x) ile) kontrol ettikten
sonra,
null
veya
del
değerlerini
bulana
kadar
t[(i + 1) mod t.uzunluk], t[(i + 2) mod t.uzunluk]
t[i],
konumları
aramaya devam ederiz. x elemanını, tam olarak bulduğumuz konuma dahil ederiz; q ve n sayılarını uygun şekilde güncelleriz.
Şu andan itibaren, sil(x) işlemini uygulamak açık hale geldi.
t[i’] = x
veya t[i’] = null koşulunu sağlayan bir i’ endeksi bulana
kadar, t[i], t[(i + 1) mod t.uzunluk], t[(i + 2) mod t.uzunluk]
| 197
konumlarını aramaya devam ederiz. Bir önceki durum sağlanmışsa,
t[i0] = del
olarak belirler ve true döndürürüz. Sonraki durum sağ-
lanmışsa, karma tabloda x elemanının bulunmadığı sonucuna varırız (bu nedenle x silinemez), ve false döndürürüz.
bul(x), ekle(x)
ve sil(x) işlemlerinin doğruluğunu del değerlerinin
kullanımına bağlı olarak kolayca kanıtlayabiliriz. Bu işlemlerin
hiçbiri, boş olmayan hiçbir girişe null değerini atayamaz. Bu nedenle, t[i’] = null olan i’ endeksine ulaşmak, mutlak şekilde x değerinin tabloda bulunmadığı anlamına gelir; ve yine aynı anlamda,
t[i’]
bundan önce de her zaman null değere sahipti, ve yine aynı
şekilde, öncesinden çalıştırılan bir ekle(i’) işleminin, i’ konumundan ileri gitmesi için hiçbir sebep yoktur.
198|
null
olmayan girişlerin sayısı t.uzunluk/2 sayısından fazla hale
geldiği zaman ekle(x) tarafından yeniden_boyutlandır() işlemi
çağrılır. null olmayan girişlerin sayısı t.uzunluk/8 sayısından az
hale geldiği zaman sil(x) tarafından yeniden_boyutlandır() işlemi
çağrılır. Negatif olmayan en küçük d tamsayısı 2d ≥ 3n bulunur, t
dizisi 2d boyutuna sahip olacak şekilde yeniden tahsis edilir, ve
sonra eski dizide yer alan tüm elemanlar yeni boyutlu t dizisi içine
tekrar yerleştirilir. Bunu yaparken, q eşittir n olarak belirlenir, çünkü yeni dizide hiçbir eleman del değerine sahip değildir.
| 199
Doğrusal Yerleştirme Analizi
Unutmayın ki, t dizisinde bulunan ilk null girişe ulaşıldığı zaman
(veya bu endeksten öncesinde de olabilir), ekle(x), sil(x) ve bul(x)
işlemleri sonlanır. Doğrusal yerleştirme analizinde temel mantık, t
elemanlarının en az yarısı boş olduğu için, bir işlemin tamamlaması
çok sürmez, çünkü hızlı bir şekilde null girişe ulaşılacaktır. Ancak
bu mantık çok kuvvetli değildir, çünkü bize t boyutu hakkında, bir
işlemin t içinde aradığı konum sayısının beklenen değerinin en fazla 2 olması gibi (yanlış) bir ipucu vermektedir.
Bu bölümün geri kalanı için, karma değerlerin birbirinden bağımsız
olarak 0,…,t.uzunluk – 1 aralığında düzgün dağıtıldığını kabul
edeceğiz. Bu gerçekçi bir varsayım değildir, ancak doğrusal yerleştirmeyi analiz etmek için mümkün olan bir başlangıç noktası sağlar.
İlerleyen bölümlerde, “Listeleme Karma” adında diğer bir yöntemi
tanıtacağız. Bu yöntem, doğrusal yerleştirme için “yeterince uygun” bir karma fonksiyonunu oluşturur. t dizisindeki endekslerin
tümünün t.uzunluk modüler aritmetiğinin sonucuna göre belirlendiğini varsayıyoruz (t[i mod t.uzunluk] için bir kısaltma t[i] ile
verilmiştir).
i
konumundan başlayan k uzunluğundaki bir çalıştırmanın gerçek-
leşmesi için, t[i], t[i + 1], … , t[i + k – 1] girişlerinin tümü null
olmamalı, ve aynı zamanda t[i – 1] = t[i + k] = null olmalıdır. t
içinde null olmayan elemanların sayısına q dersek, ekle(x) işlemi,
200|
her zaman için q ≤ t.uzunluk /
den_boyutlandır()
2
eşitsizliğini sağlar. yeni-
işleminin en son çalıştırılmasından itibaren,
diziye q eleman, x1,…,xq eklenmiştir. Varsayıyoruz ki, tablo elemanlarının her biri hash(xj) ile belirtilen, normal dağılımlı ve diğerlerinden bağımsız olan bir karma değer taşımaktadır. Bu plan
ile, doğrusal yerleştirmeyi analiz etmek için gerekli ana önermeyi
kanıtlamaya geçebiliriz.
Önerme 5.4. i
{0,…,t.uzunluk – 1}
olsun. 0
c
1
sabiti ile k
uzunluğunda i konumundan başlayan bir işlem O(ck) zamanda çalışır.
Kanıt. Bir işlem, i konumundan başlayarak k uzunluğunda çalışırsa,
hash(xj)
koşulunu sağlayan tam olarak k adet
{i,…,i + k – 1}
eleman vardır. Bu durumun tam olarak olasılığı,
olur, çünkü, k elemanın her permütasyonu için, bu k eleman k konumundan birine karma edilmeli, ve kalan q – k eleman tablo üzerinde kalan diğer t.uzunluk – k konumları için ayrılmalıdır.
Faktöryel işlemler için yapılan aşağıdaki türetme sırasında r! ile
(r/e)
r
yer
değiştirilmiştir.
Stirling'in
Faktöryeller Bölümü) göre, bu küçük hile,
Yaklaşımı’na
(bkz.
hata payı getirir.
Bu, sadece çıkarımı kolaylaştırmak için yapılmıştır. Alıştırma 5.4
| 201
bütünüyle Stirling’in Yaklaşımı’nı kullanarak dikkatli bir hesaplama mantığı getiriyor.
t.uzunluk
değeri en küçükken, pk değeri en yüksektir. Veri yapısı,
t.uzunluk ≥ 2q
değişmezini sağladığı için,
(Son adımda, her x
kullanacağız).
nır.
0
için doğru olan (1 + 1/x)x ≤
e
eşitsizliğini
olmasıyla kanıt tamamla-
bul(x), ekle(x)
ve sil(x) işlemlerinin beklenen çalışma zamanları
için üst sınırları kanıtlamak, Önerme 5.4’ü kullanarak, şimdi kolay
202|
ve açık hale geldi. Doğrusal Karma Tablo’da hiç depolanmamış
bazı x değerleri için bul(x) işleminin çalıştırıldığını düşünelim. En
kolay olan bu durumda, i = hash(x) değeri 0, t.uzunluk – 1
içinde t içeriğinden bağımsız ve rasgeledir. k uzunluğundaki çalıştırmanın bir parçası i ise, bul(x) işlemi en çok O(1 + k) zamanda
çalışır. Böylece, beklenen çalışma zamanı,
ile üst-sınırlanır. Unutmayın ki, k uzunluğundaki her çalıştırma, iç
toplama k defa katkıda bulunur. Böylece, yapılan toplam katkıya k2
dersek, yukarıdaki toplamı tekrar şöyle yazabiliriz:
Bu türetmenin son adımı,
serisinin katlanarak aza-
lan bir dizi olması gerçeğinden yola çıkmıştır. Bu nedenle, bul(x)
| 203
işlemi, tabloda bulunmayan bir x değeri için O(1) beklenen zamanda çalışır.
yeniden_boyutlandır()
işleminin maliyeti önemsenmediği takdirde,
yukarıdaki analiz, Doğrusal Karma Tablo işlemlerinin tümünün
maliyetini analiz etmek için gerek duyduğumuz herşeyi bize veriyor.
Birincisi, yukarıda verilen bul(x) analizi, x elemanı tabloda bulunmadığı zaman, ekle(x) işlemine uygulanabilir. x elemanı tabloda
bulunuyorsa, bu maliyetin ekle(x) için yapılan analiz ile aynı sonucu ürettiğini unutmamalısınız. Son olarak, sil(x) işlemi de en üst
seviyede bul(x) ile sınırlıdır.
Özet olarak, yeniden_boyutlandır() için yapılan çağrıların maliyeti
önemsenmediği takdirde, Doğrusal Karma Tablo işlemlerinin tümü
O(1) beklenen zamanda çalışır. Dizi Yığıt veri yapısı için yapılan
amortize analizin aynısını kullanarak yeniden boyutlandırmanın
maliyeti hesaplanabilir.
204|
Özet
Aşağıdaki teorem Doğrusal Karma Tablo veri yapısının performansını özetlemektedir:
Teorem 5.2. Doğrusal Karma Tablo, Sırasız Küme arayüzünü uygular. yeniden_boyutlandır() için yapılan çağrıların maliyeti
önemsenmediği takdirde, Doğrusal Karma Tablo, işlem başına
O(1) beklenen zamanda çalışan ekle(x), sil(x) ve bul(x) işlemleri-
ni destekler.
Başlangıçta, Doğrusal Karma Tablo elemanları boş değer taşırken,
ekle(x)
ve sil(x) işlemleri sıralı olarak m defa çağrılırsa, yeni-
den_boyutlandır()
işlemi için yapılan çağrı O(m) zamanda çalışır.
| 205
Listeleme Karma Yöntemi
Doğrusal Karma Tablo
yapısını analiz ederken, çok güçlü bir var-
sayımda bulunduk: Her {x1, …, xn} elemanına karşılık gelen
hash(x1),…,hash(xn)
karma değerleri {0,…,t.length – 1} kümesi
üzerinde bağımsız ve düzgün dağıtılmıştır. Bunu elde etmenin bir
yolu, 2w boyutunda çok büyük bir tab dizisi depolamaktır. Bu dizinin her girişi, tüm diğer kayıtlardan bağımsız olan, rasgele bir w-bit
tamsayısı depolar. Böylece, tab[x.hashCode()] değerinden d-bit
tamsayıyı ayıklayarak hash(x) fonksiyonunu uygulayabiliriz.
Ne yazık ki, 2w boyutunda bir dizi depolamak, bellek kullanımı
açısından pahalıdır. Bunun yerine, Listeleme Karma yaklaşımı, wbit tamsayıyı, her biri r bite sahip w/r tamsayı tarafından oluşuyormuş gibi işler. Böylece, her biri sadece 2r uzunluğunda, w/r adet
diziye ihtiyaç duyulur. Bu dizilerdeki tüm kayıtlar bağımsız birer
w-bit
tamsayıdır. hash(x) karma değerini elde etmek için
x.hashCode()
değerini w/r adet r-bit tamsayıya böleriz ve bunları
bu dizilere endeksler gibi kullanırız. Daha sonra hash(x) karma
değerini elde etmek için tüm bu değerleri bitsel–veya–harici işleci
ile birleştiririz. Aşağıdaki kod, w = 32 ve r = 4 olduğu zaman,
bunun nasıl çalıştığını gösteriyor:
206|
Bu durumda, tab, dört sütunlu ve 232/4 = 256 satırlı, iki boyutlu bir
dizidir.
Herhangi bir x için hash(x) değerinin {0,...,2d – 1} kümesi üzerinde düzgün dağıtıldığını kolayca doğrulayabilirsiniz. Küçük bir
çalışma ile, herhangi iki karma değerinin birbirinden bağımsız olduğunu da doğrulayabilirsiniz. Bunun anlamı, listeleme karma yönteminin, Zincirleme Karma Tablo uygulaması için çarpımsal karma
yönteminin yerine kullanılabilmesidir.
Ancak, n farklı elemandan oluşan herhangi bir kümenin, n bağımsız karma değerini vereceği doğru değildir. Yine de, listeleme karma yöntemi kullanıldığında, Teorem 5.2 ile verilen sınırlar hala
geçerlidir. Buna ait referanslar bölümün sonunda verilmiştir.
| 207
Karma Kodları
Önceki bölümde tartışılan karma tabloları, w bitten oluşan tamsayı
anahtarlarını veri ile ilişkilendirmek için kullanılmıştı. Oysa ki,
birçok durumda, tamsayı olmayan anahtarlar ile karşılaşırız. Anahtarlarımız dize, nesne, dizi, veya diğer bileşik yapılar olabilir. Karma tablosunda kullanmak üzere, bu veri türlerinin w-bit karma kodları ile eşleştirilmesi gerekir. Karma kodu eşleştirmeleri aşağıdaki
özelliklere sahip olmalıdır:
1.
x ve y eşit
2.
x
ise, x.hashCode() ve y.hashCode() eşittir.
ve y eşit değil ise, x.hashCode() = y.hashCode() olasılığı
küçük olmalıdır (yaklaşık 1/2w).
Birinci özellik, eğer karma bir tabloda x elemanını depoluyorsak,
ve daha sonra x’e eşit olan bir y değerini arıyorsak, x’i gerektiği
gibi buluruz – koşulunu sağlar. İkinci özellik, nesneleri tamsayılara
dönüştürmemizden gelen kaybı en aza indirir. Eşit olmayan nesnelerin genellikle farklı karma kodları vardır, ve böylece karma tablomuzda farklı yerlerde depolanmış olmaları muhtemeldir, koşulunu sağlar.
208|
Temel Veri Türleri için Karma Kodları
char, byte, int
ve float gibi küçük temel veri türleri için karma
kodlarını bulmak genellikle kolaydır. Bu veri türlerinin her zaman
ikili gösterimi vardır ve bu ikili gösterim genellikle, w veya daha az
bitten oluşur (Örneğin, Java’da byte 8-bitlik bir türdür ve float 32bitlik türdür). Bu durumlarda, bu bitleri sadece {0,…,2w – 1} aralığında bir tamsayının sembolü olarak görüyoruz. İki değer farklı ise,
farklı karma kodları hesaplanır. Aynı iseler, aynı karma kodları
olur.
Birkaç temel veri türü, w bitten daha fazlasını içerir, veya bir c
tamsayı sabiti için genellikle cw bitten oluşur.(Örnek olarak, Java
long
ve double türleri için c = 2 verilmiştir). Bir sonraki bölümde
anlatıldığı gibi, bu veri türleri c bölümden oluşan bileşik nesneler
olarak işlenebilir.
| 209
Bileşik Nesneler için Karma Kodları
Bir bileşik nesne için, nesneyi oluşturan parçaların tek tek karma
kodlarını birleştirerek karma kodu oluşturmak istiyoruz. Bunu elde
etmek göründüğü kadar kolay değildir. Pek çok çözüm yolu bulunabilmesine rağmen (örneğin, bitsel–veya–harici işlemleri ile karma kodlarını birleştirerek), bu yollardan çoğu kolaylıkla engellenebilir (bkz. Alıştırmalar 5.7 – 5.9). Ancak, 2w bit duyarlığında aritmetik yapmaya istekli iseniz, mevcut basit ve sağlam işlemler yapabilirsiniz. Birkaç bölümden, P0, ..., Pr-1, oluşan bir nesne olduğunu varsayalım. Bu bölümlerin karma kodları, sırasıyla, x0,…,xr-1
olsun. Karşılıklı bağımsız rasgele w-bit z0, …, zr-1 tamsayılarını ve
rasgele 2w-bit tek z tamsayısını seçerek, nesnemiz için karma kodunu şöyle hesaplayabiliriz:
Unutmayın ki, bu hash kodunun karma formülünü kullanan (z ile
çarpan ve 2w ile bölen) bir son adımı vardır. Bu adım, 2w-bitlik ara
sonucu alır, ve bunu w-bitlik bir son sonuç haline getirmek için
Çarpımsal Karma Yöntemi Bölümü’nde verilen çarpımsal karma
fonksiyonunu kullanır.
210|
Bu yöntemin x0, x1, x2 bölümlerinden oluşan bileşik bir nesneye
uygulanmış hali yukarıda verilmiştir.
Aşağıdaki teorem göstermektedir ki, bu yöntem, uygulamasının
açık olmasının yanı sıra, kanıtlanabilirlik açısından da iyidir.
Teorem 5.3. x0,…,xr–1 ve y0,…,yr–1 tamsayıları, {0,…,2w – 1} içinde yer alan w bitlik birer dizi olsun, ve i
{0,…,r – 1}
en az bir i endeksi için varsayın ki, xi
O zaman,
yi.
aralığından
Kanıt. En sondaki çarpımsal karma adımını önemsemeyeceğiz, ve
bu adımın katkısına daha sonra bakacağız. Tanımlayın:
| 211
Diyelim ki, h’(x0,…,xr–1) = h’(y0,…,yr–1). Bunu şöyle yeniden yazabiliriz:
Burada,
olarak hesaplanır. Genelleştirme kaybı olmaksızın xi
yi
kabul
edersek, (5.4)
haline gelir, çünkü her bir zi ve (xi – yi) en fazla 2w – 1 olduğu için
çarpımları en fazla 22w – 2w+1 + 1 22w – 1 olur. Varsayım olarak,
xi – yi
0,
bu nedenle (5.5) çözümü en çok bir tanedir. zi ve t ba-
ğımsız olduğundan (z0,…,zr
xr–1) = h’(y0,…,yr–1)
– 1
karşılıklı bağımsızdır), h’(x0,…,
koşulunu sağlayan bir zi seçme olasılığımız en
fazla 1/2w olarak hesaplanır.
Karma fonksiyonunun son adımı çarpımsal karma işlemini uygulayarak, 2w bitlik h’(x0,…,xr–1) ara sonucunu, son sonuç olan w bitlik
h(x0,…,xr–1)
haline getirmektir. Teorem 5.3 ile, eğer h’(x0,…,xr–1)
h’(y0,…,yr–1)
ise, Pr{h(x0,…,xr–1) = h(y0,…, yr–1)}
olarak hesaplanır.
2/2
w
212|
Özetlemek gerekirse,
| 213
Diziler ve Dizeler için Karma Kodları
Daha önceki bölümde anlatılan yöntem, değişmez, sabit sayıda
bileşenler içeren nesneler için iyi çalışmaktadır. Ancak değişken
sayıda bileşen içeren nesnelerle kullanmak istiyorsak, her bileşen
için rasgele bir w-bit zi tamsayısı gerekir ki, yöntem bozulur. İhtiyacımız olduğu kadar zi oluşturmak için sözde rasgele bir dizi kullanabilirdik, ancak o zaman zi'lar birbirinden bağımsız olmazdı, ve
sözde rasgele sayıların bizim kullandığımız karma fonksiyonu ile
kötü etkileşimde olmadığını kanıtlamak zor hale gelirdi. Özellikle,
Teorem 5.3 kanıtındaki t ve zi değerleri artık bağımsız değildir.
Daha dikkatli bir yaklaşımla, karma kodlarını asal katsayılara sahip
polinomlara dayandırabiliriz; bunlar bir, p, asal sayısı için modülo
p
üzerinden değerlendirilen normal polinomlardır. Bu yöntem, asal
katsayılı polinomların hemen hemen her zamanki polinomlar gibi
davrandığını söyleyen aşağıdaki teoreme dayanır:
Teorem 5.4. p bir asal sayı, ve anlamlı bir polinomun, f(z) = x0z0
1
+ x1z +…+ xr – 1 z
r -1
, katsayıları xi
rumda, f(z) mod p = 0 denkleminin z
r–1
{0,…,p – 1}
olsun. Bu du-
{0,…,p – 1}
için en fazla
çözümü bulunur.
Teorem 5.4’ü kullanmak için, her xi
x0, …, xr–1
p – 1}
{0,…,p – 2}
olan bir
tamsayı dizisini, rasgele bir z tamsayısını z
{0,…,
kullanarak, aşağıdaki formülle karma ederiz.
214|
Formülün sonundaki ek terime, (p – 1)zr dikkat edin. Bu terim,
x0,…,xr
dizisinin son elemanı xr olarak (p – 1)’i düşünmemize yar-
dımcı olarak hesaplanır. Unutmayın ki, bu eleman, dizideki diğer
her elemandan (her biri {0,…,p – 2} kümesinde olan elemanlardan)
farklıdır. p – 1, bir dizi-sonu-belirteci olarak da düşünülebilir.
Aynı uzunluktaki iki dizi durumunu ele alan aşağıdaki teorem, bu
karma fonksiyonunun z’yi seçmek için ihtiyaç duyulan az miktarda
rasgelelik için iyi bir getiri sağladığını göstermektedir.
Teorem 5.5. p
yr–1
2
w
+ 1
asal sayı olsun. Her x0,…,xr–1 ve y0, …,
tamsayısı, {0,…, 2w – 1} içinde yer alan w bitlik birer dizi
olsun, ve i
{0, …, r – 1}
sayın ki, xi
yi
aralığından en az bir i endeksi için var-
. O zaman,
Kanıt. h(x0,…,xr–1) = h(y0,…,yr–1) denklemi yeniden şöyle yazılır:
x1
y1
olduğundan bu polinom anlamsız değildir. Bu nedenle, Teo-
rem 5.4 ile, z içinde en fazla r – 1 çözümü bulunur. Bu çözümlerden birinin z seçilmesi olasılığı, bu nedenle en fazla, (r – 1)/p olarak hesaplanır.
| 215
Unutmayın ki, bu karma fonksiyonu, iki dizi farklı uzunluklara
sahip olduğu zaman, ve dizilerden biri, diğerine önek olduğu zamanlar için de geçerlidir. Çünkü bu fonksiyon, etkin şekilde aşağıda belirtilen sonsuz diziye karma sağlar.
r > r’
olan, r ve r’ uzunluğunda iki dizi varsa, bu iki dizi i = r en-
deksinde farklılık gösterir. Bu durumda, (5.6)
haline gelir. Teorem 5.4 ile, bu denklemin z içinde en fazla r çözümü bulunur. Teorem 5.5 ile birleştirildiğinde, aşağıdaki daha
genel teoremi kanıtlamaya yeterlidir:
Teorem 5.6. p
yr’–1
w
2 +1
asal sayı olsun. Her x0, …, xr–1 ve y0, …,
tamsayısı {0,…,2w – 1} içinde yer alan w bitlik birer dizi ol-
sun. Bu durumda,
Aşağıdaki örnek kod, bu karma fonksiyonun bir x dizisi içeren nesneye nasıl uygulandığını gösteriyor:
216|
Yukarıdaki kod, uygulamada kolaylık sağlamak için, toslama olasılığını önemsememiştir. Özellikle, d = 31 ile x[i].hashCode() karma kodunu 31-bit değere indirmek için, Çarpımsal Karma Yöntemi
Bölümü’ndeki çarpımsal karma fonksiyonunu uygulamıştır. Bu
sayede, modülo p = 232 – 5 asal sayısı ile yapılan eklemeler ve
çarpmalar 63-bit işaretsiz aritmetiği kullanılarak gerçekleştirilebilir.
Böylece daha uzun olanın r uzunlukta olduğu iki farklı dizinin, aynı
karma koduna sahip olma olasılığı, Teorem 5.6’da belirtilen
r / (2
olur.
32
– 5)
olacak yerde, en fazla,
| 217
Tartışma ve Alıştırmalar
Karma tabloları ve karma kodları, bu bölümde sadece değindiğimiz
bir araştırmanın büyük ve aktif bir alanını temsil etmektedir. Karma
üzerine yaklaşık 2,000 girdi içeren çevrimiçi Bibliyografya’ya
[10]’dan erişebilirsiniz.
Karma tablosu uygulamaları farklı ve çok çeşitlidir. Zincirleme
Karma Tablo: Zincirleme İle Adresleme Bölümü'nde anlatılan yöntem zincirleme ile karma olarak bilinir. Her dizi girişi, bir zincir
(Liste) içindeki elemanları içerir. Zincirleme ile karma tarihi, Ocak
1953’te H. P. Luhn tarafından hazırlanan IBM iç bildirisine kadar
uzanmaktadır. Bu bildiri, bağlı listelere de ilk referanslardan biri
olarak görünmektedir.
Zincirleme ile karmaya bir alternatif de, tüm verilerin bir dizi içinde doğrudan depolandığı, açık adresleme şemaları tarafından kullanılan karmalardır. Bu şemalar, Doğrusal Karma Tablo: Doğrusal
Yerleştirme Bölümü’ndeki Doğrusal Karma Tablo yapısını içerir.
Bu fikir aynı zamanda bağımsız olarak 1950’lerde, IBM’deki bir
grup tarafından önerilmişti. Açık adresleme şemaları, toslama çözümü sorunu ile, yani iki değerin aynı dizi konumuna karma olması
durumuyla ilgilenmek zorundadır. Toslama çözümü için farklı stratejiler vardır; bunlar farklı performans garantisi sağlar, ve burada
sık sık anlatılmış olanlardan daha gelişmiş karma fonksiyonlarını
gerektirir.
218|
Karma tablosu uygulamalarının bir başka kategorisi, mükemmel
karma yöntemleri diye anılan kategoridir. Bu yöntemlerde bul(x)
işlemi, en kötü O(1) zamanda çalışır. Statik veri kümeleri için, veriler üzerinde mükemmel karma fonksiyonları bulunarak bunu gerçekleştirmek mümkündür. Bu fonksiyonlar, her veri parçasını benzersiz bir dizi konumuyla eşleştirir. Zamanla değişen veriler için,
mükemmel karma yöntemleri arasında, FKS iki-seviyeli karma tabloları [31, 24], ve guguk-kuşu karma yöntemi [57] sayılabilir.
Bu bölümde sunulan karma fonksiyonları, muhtemelen her veri
kümesi ile iyi çalışabilen bilinen en pratik yöntemlerdir. Diğer kanıtlanabilir yöntemler, Carter ve Wegman’ın evrensel karma kavramını tanıtan ve farklı senaryolar için çeşitli karma fonksiyonlarını
anlatan öncü çalışmalarına [14] kadar uzanmaktadır. Listeleme
Karma Yöntemi Bölümü'nde anlatılan listeleme karma, Carter ve
Wegman tarafından açıklanmıştır [14], ancak doğrusal karma tabloya (ve diğer birçok karma tablo şemalarına) uygulanmış haliyle
analizini Patraşcu ve Thorup’a [60] borçluyuz.
Çarpımsal karma fikri çok eskidir, ve karma geleneğinin bir parçası gibi görünmektedir [48, bkz. Bölüm 6]. Ancak, z çarpanını
rasgele bir tek sayı olarak seçme fikri, ve Çarpımsal Karma Yöntemi Bölümü’nde anlatılan analizi, Dietzfelbinger et al. [23] tarafından tartışılmıştır. Çarpımsal karmanın bu versiyonu, en basitlerinden biridir, ancak 2/2d olan toslama olasılığı, 2w
2
d
ile belirtilen
bir rasgele fonksiyondan beklediğinizden ikinin bir kuvveti kadar
| 219
çok daha büyüktür. Çarpma-toplama karma yöntemi, z ve b rasgele
olarak
içinden seçilen,
fonksiyonunu kullanır. Çarpma-toplama karmasının sadece 1/2d
toslama olasılığı vardır [21], ancak 2w-bite duyarlı aritmetik gerektirir.
Sabit uzunlukta olan w-bitlik tamsayı dizilerinden karma kodları
elde etmenin yöntemleri vardır. Özellikle hızlı bir yöntem, çift sayı
olan bir r, ve {0,…,2w} içinden rasgele seçilen a0, …, ar–1 değerleri
için,
fonksiyonunu [11] kullanmaktır. Bu 1/2w toslama olasılığı olan
2w-bitlik
hash kodunu verir. Çarpımsal karma (veya çarpma-
toplama) işlemini kullanarak, bunu, w-bitlik hash koduna indirebilirsiniz. Bu işlem hızlıdır, çünkü sadece r/2 adet 2w-bitlik çarpma
gerektirir; oysa ki Bileşik Nesneler için Karma Kodları Bölümü’nde anlatılan işlem, r çarpma gerektiriyordu (mod işlemleri,
eklemeler ve çarpmalar için, sırasıyla, w ve 2w-bit aritmetik kullanarak dolaylı olarak gerçekleştirilir).
220|
Diziler ve Dizeler için Karma Kodları Bölümü’nde anlatılan, asal
katsayılı polinomların, değişken uzunluktaki diziler ve dizelere
karma edilerek kullanılması yöntemi, Dietzfelbinger ve arkadaşları
[22] tarafından geliştirilmiştir. Pahalı bir makine komutuna dayanan mod işlecini kullanması nedeniyle, ne yazık ki, çok hızlı değildir. Bu işlemin bazı biçimleri, asal p olarak 2w – 1 seçer. Bu durumda mod işleci, ekleme (+) ve bitsel–ve (&) işlemi [47, Bölüm
3] ile yer değiştirebilir. Başka bir seçenek, sabit uzunluktaki dizeler
için mevcut hızlı işlemlerden birini, c
1
sabitiyle verilen c uzun-
luğundaki bloklara uygulamak, ve sonra asal katsayı yöntemini
r/c
karma kodlarından oluşan sonuç dizisine uygulamaktır.
Alıştırma 5.1. Belirli bir üniversite, her öğrencisine herhangi bir
kurs için ilk kez kayıt oldukları zaman birer öğrenci numarası veriyor. Yıllar önce 0 ile başlayan bu ardışık tamsayılar şimdi milyonları bulmuştur. Yüz adet birinci sınıf öğrencisine, öğrenci numaralarına dayalı karma kodlarını vermek istediğimizi düşünün. Bu durumda, öğrenci numarasının ilk iki basamağını mı, son iki basamağını mı kullanmak daha mantıklı olur? Cevabınızı doğrulayın.
Alıştırma 5.2. Çarpımsal Karma Yöntemi Bölümü'nde verilen
karma şemayı düşünün ve varsayalım ki, n=2d ve d ≤ w/2.
1. Seçilen herhangi bir z çarpanı için, hepsi aynı karma koduna
ait, n değerin mevcut olduğunu gösterin (İpucu: Herhangi bir
sayı teorisini gerektirmez).
| 221
2. z çarpanı verildiğinde, hepsi aynı karma koduna ait, n değeri
açıklayın (İpucu: Birtakım temel sayı teorisini gerektirir).
Alıştırma 5.3. x=2w–d–2 ve y=3x ise Pr{hash(x)} = Pr{hash(y)}
= 2/2
d
olduğunu göstererek, Önerme 5.1 ile verilen 2/2d sınırının
mümkün olan en iyi sınır olduğunu kanıtlayın (İpucu: İkili tabanda
zx
ve z3x gösterimlerine bakın, ve z3x = zx+2zx gerçeğini kulla-
nın).
Alıştırma 5.4. Faktöryeller Bölümü'nde verilen Stirling'in Yaklaşımı’nın tüm yorumunu kullanarak Önerme 5.4’ü tekrar kanıtlayın.
Alıştırma 5.5. Bir Doğrusal Karma Tablo’ya x elemanını eklemek
için, dizinin ilk null girdisine x elemanını depolayan kodun, aşağıdaki basitleştirilmiş versiyonunu düşünün.
O(n) zamanda çalışan ekle(x), sil(x) ve bul(x) işlemlerini örnek
vererek, bunun n2 zamanda neden çok yavaş çalışabileceğini açıklayın.
222|
Alıştırma 5.6. String sınıfına ait Java hashCode() yönteminin önceki versiyonları, uzun dizelerde bulunan tüm karakterleri kullanmaksızın çalışıyordu. Örneğin, on altı uzunluğundaki karakter dizesi için karma kodu, yalnızca sekiz çift endeksli karakterleri kullanarak hesaplanmıştır. Hepsi aynı karma koduna sahip büyük miktarda
dizeleri örnek göstererek, bunun neden çok kötü bir fikir olduğunu
açıklayın.
Alıştırma 5.7. Varsayalım ki, iki w-bit tamsayı olan x ve y’den
oluşan bir nesne var. Neden x
y
fonksiyonu nesneniz için iyi bir
karma kodu sağlamaz, gösterin. Karma kodu 0 olan nesnelerden
oluşan büyük bir küme örneğini verin.
Alıştırma 5.8. Varsayalım ki, iki w-bit tamsayı olan x ve y’den
oluşan bir nesne var. Neden x + y fonksiyonu nesneniz için iyi bir
karma kodu sağlamaz, gösterin. Karma kodu aynı olan nesnelerden
oluşan büyük bir küme örneğini verin.
Alıştırma 5.9. Varsayalım ki, iki w-bit tamsayı olan x ve y’den
oluşan bir nesne var. Nesneniz için karma kodu, h(x, y)
deterministik fonksiyonu ile tanımlansın. Bu fonksiyon, tek bir wbitlik tamsayı üretir. Aynı karma koduna sahip olan nesnelerin
oluşturduğu büyük bir kümenin var olduğunu kanıtlayın.
Alıştırma 5.10. Bazı pozitif tamsayı w için p=2w – 1 olsun. Neden
bir pozitif tamsayı x için,
| 223
olduğunu açıklayın.
(x mod (2w – 1) hesabını gerçekleştiren bir algoritmada,
x
w
2 –1
olana dek, ard arda,
olarak belirleyin).
Alıştırma 5.11. Sık kullanılan bazı karma tablo uygulamalarını
bulun (Java Collection Framework, HashMap veya bu kitapta yer
alan Karma Tablo veya Doğrusal Karma Tablo uygulamaları gibi)
ve bu veri yapısındaki tamsayıları depolayan bir program tasarlayın; öyle ki x tamsayıları için bul(x) işlemi, doğrusal zamanda çalışsın. Yani, n tamsayı içinden cn elemanın aynı tablo konumuna
karma edildiği bir küme bulun.
Uygulamanın ne kadar iyi olduğuna bağlı olarak, sadece uygulama
kodunu inceleyerek bunu yapabilirsiniz, veya belirli değerleri eklemenin ve bulmanın ne kadar zaman aldığını belirlemek için, deneme mahiyetinde, ekleme ve arama işlemlerini gerçekleştiren bazı
kodları yazmak zorunda kalabilirsiniz (Web sunucuları üzerinde
bu, denial-of-service [17] saldırılarını başlatmak için kullanılabilir,
ve kullanılmıştır).
224|
Bölüm 6
İkili Ağaçlar
Bu bölüm, bilgisayar bilimlerinin en temel yapılarından birini tanıtıyor: İkili Ağaç. Burada, köken olarak ağaç sözcüğünün kullanılması, kağıda çizdiğimizde, sık sık bir ormanda bulunan ağaca benzer şekilleri andırmasından ileri gelmektedir. İkili ağacı tanımlamanın birçok yolu vardır. Matematiksel olarak, ikili ağaç, bağlı,
yönsüz ve hiçbir döngüsü olmayan sonlu bir grafiktir ve köşelerinin
hepsi en fazla üç dereceye sahiptir.
Çoğu bilgisayar bilimi uygulamaları için ikili ağaçlar köklüdür: En
çok ikinci dereceden olan özel bir r düğümü, ağacın kökü olarak
adlandırılır. Her u r düğümü için, u’dan r’ye giden yol üzerindeki
ikinci düğüm, u’nun menşei olarak adlandırılır. u’ya bitişik diğer
düğümlerin her biri, u’nun çocuğudur. İlgileneceğimiz ikili ağaçların çoğu sıralıdır, bu yüzden u’nun sol ve sağ çocuklarını ayrı düşünmenizde fayda vardır.
Gösterimlerde, ikili ağaçlar genellikle kökten başlayarak aşağı
yönde çizilir, çizimin üst kısmında kök vardır. Sol ve sağ çocuklar,
sırasıyla gösterildiği gibi (Şekil 6.1), sol ve sağ dallara ayrılır. Örneğin, Şekil 6.2 dokuz düğümlü ikili ağacı gösteriyor.
| 225
Önemli bir yeri olan ikili ağaç kavramında birçok yeni terminolojiye gerek duyulmuştur. Geniş kabul gören bazı tanımları listelemek
gerekirse, derinlik, ata, çocuk, yükseklik, yaprak, altağaç sayılabilir. İkili ağaç içinde bir u düğümünün derinliği, u düğümü ile kök
arasındaki yolun uzunluğudur. Bir u düğümünde olduğunuzu düşünelim. w ile belirtilen bir düğüm, sizinle başka bir r arasında kalıyorsa, w sizin atanız olarak hesaplanır, ve siz w ile belirtilen düğümün çocuğu sayılırsınız.
Üzerinde durduğunuz düğümden bir altağaç oluşmuşsa, siz o
altağacın kökü sayılırsınız. Bu altağaç sizin tüm çocuklarınızı içerir. Size ait olan bir düğümün yüksekliği, çocuğunuza giden yolun
en uzun mesafesidir. Bir ağacın yüksekliği, siz kökte iken hesaplanan yüksekliktir. Hiçbir çocuğunuz yoksa, düğümünüz yapraktır.
226|
Bazı durumlarda, ikili ağacın uç düğümlerini dış düğüm olarak değerlendirmek gereklidir. Sol çocuğu olmayan düğümlerin soluna
bir dış düğüm, sağ çocuğu olmayan düğümlerin sağına bir dış düğüm yerleştirmek, (Şekil 6.2.b) ikili ağacın kolay doğrulanabilir
özelliklerini anlamamıza yardımcı olur. Örnek vermek gerekirse, n
≥ 1 koşulunu sağlayan n gerçek düğümlü bir ikili ağacın n + 1 dış
düğümü vardır.
| 227
İkili Ağaç: Temel İkili Ağaç
u
düğümünün ikili ağaç olduğunu ifade etmenin en temel kriteri, en
çok üç düğümle bağlantılı olmasıdır. Bu üç düğüm, komşu bağlantılar olarak tanımlanır:
Ağaçlık koşulunun devamlılığını sağlamak niyetiyle, bu üç komşudan biri mevcut değilse, değeri nil olarak atanır. Bununla beraber,
ağacın dış düğümleri ve kökün menşei de nil olacaktır.
İkili ağacın kendisi köküyle ifade edilmektedir. Kök r ise:
Bir u düğümünün, u’dan köke yol uzunluğu ile ölçülen derinliği,
hesaplanabilir bir niceliktir:
228|
Özyinelemeli Algoritmalar
Özyinelemeli algoritmaları kullanarak ikili ağaç hakkında kolay
hesaplanır gerçekleri ifade edebilirsiniz. Örneğin, kökü, u, olan ikili
ağacın düğüm sayısını (boyutunu) hesaplamak için, özyinelemeli
olarak, u düğümünde köklenmiş iki altağacın boyutları hesaplanır,
sonuç bu ikisinin toplamının bir fazlası olarak döndürülür:
u
düğümünün yüksekliğini hesaplamak için, u’nun iki altağacının
yüksekliği hesaplanır, en büyüğünün bir fazlası döndürülür:
| 229
İkili Ağaçta Sıralı-Düğüm Ziyaretleri
Bir önceki bölümde elde edilen algoritmaların her ikisi de, ikili
ağaçtaki tüm düğümleri ziyaret etmek için özyineleme tekniğini
kullanıyor. İkili ağacın düğümlerini ziyaret etme sırasını belirleyen,
yazılan kodun kendisidir:
Özyinelemenin ikili ağaca bu şekilde uyarlanması kodu basitleştirir, ancak sorun da yaratabilir. Özyinelemenin maksimum derinliği,
ikili ağaçta bir düğümün maksimum derinliği, yani ağacın derinliği
ile verilmiştir. Ağacın yüksekliği çok fazla olduğu takdirde, özyineleme kendisini fazla tekrar edeceği için Yığıt için ayrılan bellek
sömürülerek kullanımı olanak dışı olur ve çöküşe sebep olabilir.
Özyineleme olmadan da, ikili ağacın nereden geldiğine göre, nereye gideceğini kendisi belirleyen bir algoritma kullanabilirsiniz
(bkz. Şekil 6.3). u.parent bir u düğümüne ulaşırsa, daha sonra yapılacak bir sonraki adım sol altağacı, u.left, ziyaret etmek olacaktır.
Bu yönden, u düğümüne yapılacak bir ziyaret, bize sağ altağacın,
u.right,
yollarını açacaktır. Böylece, u düğümüne yapılacak bir
ziyaret ile u altağacı tamamıyla ziyaret edilmiş olacaktır. Altağaç
230|
ziyareti tamamlandıktan sonra, menşei düğüm ziyareti ile birlikte
süreç sona erer.
Aşağıdaki kod, sol, sağ ve menşei düğümlerin nil olmasına izin
verecek şekilde, bu fikri uyguluyor:
Özyinelemeli algoritmalar ile ilgili hesaplamalar özyinelemesiz kod
için de geçerlidir. Örneğin, ağaç boyutunu hesaplamak için, her
düğüm ziyaretinde sayaç 1 artırılarak çözüm bulunabilir:
| 231
İkili ağaçların bazı uygulamalarında, menşei düğüm kullanılmaz.
Bu durumda, özyinelemeli olmayan bir uygulama hala mümkündür,
ancak bulunduğumuz düğümden köke giden yolda Liste (veya
Yığıt)
veri yapılarından herhangi birinin kullanılması, uygun ve
gerekli olacaktır.
232|
Yukarıdaki fonksiyonlara ait gözlemler göstermiştir ki, ziyaret sırası, desene göre değişmektedir. Bunun anlamı, önce ziyaretin deseni
belirlenmelidir.
| 233
Enine aramada, düğümler düzey-düzey ziyaret edilmektedir. Kökten başlar, aşağı doğru ilerler, soldan sağa doğru her seviyede düğümler ziyaret edilir (bkz. Şekil 6.4). Buna Türkçe bir metnin sayfasını okumak da diyebiliriz. Bu desen, verilen bir q, Kuyruk veri
yapısı ile gerçekleştirilebilir.
Başlangıçta Kuyruk’ta kök, r, bulunmaktadır. Her adımda, bir sonraki u düğümünü, q kuyruğundan ayrıştırırız, u düğümünü işleme
koyarız, ve sol ve sağ düğümlerini (nil değillerse) q’a ekleriz.
234|
Serbest Yükseklikli İkili Arama Ağacı
Serbest Yükseklikli İkili Arama Ağacı , u.x
veri değerini sıralı kri-
terlere uygun olacak şekilde depolayan, özelleştirilmiş ikili arama
ağaç türlerinden biridir. İkili Arama Ağacı’nda depolanan veri elemanları, Serbest Yükseklikli İkili Arama Ağacı’nın özelliklerine
uyar, örneğin, büyüklük sırası soldan sağa doğru sıralanacaksa, bir
u
düğümü verildiğinde,
1. u.left
u.x
(yani, sol altağaç elimizdeki değerden küçüktür),
u.x
(yani, sağ altağaç elimizdeki değerden büyüktür)
ve
2. u.right
koşulları sağlanır. Şekil 6.5 Serbest Yükseklikli İkili Arama Ağacı’na bir
örnek gösteriyor.
| 235
Arama
İkili Arama Ağacı
veri yapısında bir değere ulaşmak oldukça ko-
laydır. Kökten başlanır; herhangi bir x değeri için üç durum söz
konusudur:
1. u.left araması için, x
2. u.right araması için, x
u.x koşulu
sağlanmalıdır.
u.x koşulu
sağlanmalıdır.
3. x = u.x ise, aranan düğüme ulaşılmıştır.
3.durum oluştuğunda arama başarılı, veya u=nil olduğu takdirde,
başarısız sonuç döndürür.
Serbest Yükseklikli İkili Arama Ağacı ’nda
gerçekleştirilebilecek
aramalara iki örnek Şekil 6.6’da gösterilmiştir.
236|
İkinci örnekte gösterildiği gibi aramanın başarısız olduğu durumlar
hakkında yargıda bulunalım: 1.durum oluştuğunda en son u düğümüne bakarsanız, u.x için büyüklük karşılaştırması yapmaya gerek
duymadan, x’den büyük olan en küçük değer yargısı verebilirsiniz.
Serbest Yükseklikli İkili Arama Ağacı
bize bunu garanti eder.
2.durum oluştuğunda, benzer şekilde, x’den küçük olan en büyük
değer yargısı verilir. Bu matematiksel yargıların yararlı özellikleri
Serbest Yükseklikli İkili Arama Ağacı’nın
cak arama sonucu, onlar belirgin hale gelir.
içine kodlanmıştır. An-
| 237
Bu bize, arama sonucunu bulmak için tasarlanan bul(x) işleminde
kullanılan karşılaştırmaların, bizi x hedefine götürmede ne kadar
kuvvetli bir araç olduğunu gösteriyor.
238|
Ekleme
Serbest Yükseklikli İkili Arama Ağacı ’na
yeni bir değer eklemek
için, ilk olarak x aranır. Bulunursa, eklemeye izin verilmez. Aksi
takdirde, x için yapılan aramanın en sonunda ulaşılan p düğümünde, x ve p.x karşılaştırması yapılır. Büyüklük sıralaması ne gerektiriyorsa sonuca göre, elimizdeki p düğümünün sol veya sağ yaprağına, doğru bir şekilde x eklenir.
Bir örnek, Şekil 6.7’de gösterilmiştir. Bu sürecin en çok zaman alan
parçası, yeni eklenen, u düğümünün yüksekliğine orantılı olarak
çalışan, ve x için yapılan ilk aramadır. En kötü durumda, bu Serbest Yükseklikli İkili Arama Ağacı’nın
yüksekliğine eşittir.
| 239
240|
Silme
Ağacın, u düğümünü (verisiyle birlikte) silme, İkili Arama Ağacı’nda
biraz daha zordur. Silinecek u düğümü bir yaprak ise, sadece
menşei’nden onu ayırmak yeterli olacaktır.
Bunun için daha iyi bir yöntem vardır: u’nun sadece bir çocuğu
varsa, ağaçtan u çıkarılarak, u’ya bağlı düğümler birbirine uç uça
eklenir. u menşei, kendi çocuğunu evlat edinmiştir (bkz. Şekil 6.8):
| 241
Silinecek düğümün ağaçta halihazırda iki çocuğu varsa, ikiden az
çocuğu olan bir w düğümü için arama yapılmalıdır. Uygunluk kriteri şöyle seçilmelidir: Her durumda, Serbest Yükseklikli İkili Arama
Ağacı
özellikleri korunmalıdır. Silinecek düğümün değerini seçmek
için büyüklük sıralamasına göre, u düğümünün sağ altağacında u.x
değerinden bir sonra gelen büyüğü aranır. Her düğüm için, sağ çocuk değeri sol çocuktan büyüktür. O zaman, sağ çocuğa ait
altağacın yapraklarından küçüğünü, u’nun değeri olarak atayabiliriz. Bu bize gerekli olan büyüklük sıralamasını sağlar. Böyle bir w
düğümü bulunduğunda, u.x değeri w’ye aktarılır. Dikkat edilmesi
gereken bir konu, u civarında w düğümlerini aramalıyız. w.x değeri
u.x
değerine yakın olmalıdır. Bunun için u.right altağacında
242|
u.x’den
büyük olan en küçük değeri buluruz. Bu düğümün çocuğu
olmadığı için silmek kolaydır (bkz. Şekil 6.9).
| 243
Özet
Serbest Yükseklikli İkili Arama Ağacı ’nda
ekle(x)
gerçekleştirilen bul(x),
ve sil(x) işlemleri, her ağacın kökünden bir yol izlemeyi
gerektiriyor.
Yol uzunluğu düğümlerin konumuna bağlıdır. Aşağıdaki teorem
Serbest Yükseklikli İkili Arama Ağacı
veri yapısının performansını
özetlemektedir:
Teorem 6.1. Serbest Yükseklikli İkili Arama Ağacı, Sıralı Küme
arayüzünü uygular. İşlem başına O(n) beklenen zamanda çalışan
ekle(x), sil(x)
ve bul(x) işlemlerini destekler.
Serbest Yükseklikli İkili Arama Ağacı
yapısı ile ilgili sorun, yük-
sekliğini, girdi verilerinin geliş sırasına bağlı olarak önceden belirleyememiş olmamızdır. Yani, sadece işlemler değil, ağaç yüksekliği de O(n) olabilir; işlem sayısı çok ise performans olumsuz etkile-
244|
nir. Verilerin geliş sırasına bağlı olarak, eğer bir ikili ağaç zinciri
oluşmuşsa (yani, son düğüm dışında her düğümün yalnız bir çocuğu varsa), Teorem 6.1 yeterli olmaz. Teorem 4.1 bir çözüm olabilir,
çünkü Sıralı Küme Sekme Listesi yapısının uygulaması Sıralı Küme arayüzünün
gerçekleştirimi ile O(log n) zamanda çalışır.
Tüm işlemleri O(log n) çalışma zamanında gerçekleştiren Serbest
Yükseklikli İkili Arama Ağacı’nı
kullanmaktan kaçınmanın birkaç
yolu vardır. Bölüm 7’de, O(log n) beklenen çalışma zamanlı işlemlerin rasgelelik kullanarak nasıl gerçekleştirildiğini gösteriyoruz.
Bölüm 8’de O(log n) amortize çalışma zamanlı işlemlerin kısmi
yeniden yapılandırma işlemlerini kullanarak nasıl gerçekleştirildiğini gösteriyoruz. Bölüm 9’da O(log n) en-kötü çalışma zamanlı
işlemlerin, en fazla 4-çocuğu olan düğümlere sahip, yani ikiliolmayan bir ağaç yapısını kullanarak nasıl gerçekleştirildiğini gösteriyoruz.
| 245
Tartışma ve Alıştırmalar
İkili ağaçlar binlerce yıldır ilişki modellemek için kullanılmıştır.
Bunun nedeni, ikili ağaçlar soy ağaçlarının doğal modeli olabilir mi
sorusuydu. Aile ağacı demek daha doğrudur. Kök bir insan, sol ve
sağ çocuklar ana-baba ve özyinelemeli olarak devamı sayılabilir.
Daha yakın yüzyıllarda, ikili ağaçlar, biyolojide tür kavramını modellemekte kullanıldı. Ağacın yaprakları kaybolmamış türleri temsil
ederken, iç düğümleri türleşmeyi temsil eder. Örnek olarak, tek bir
türün iki ayrı türe dönüşmesine neden olan olayların iki ayrı popülasyonu nasıl oluşturduğu problemi verilebilir.
İkili arama ağaçlarının 1950'lerde çeşitli gruplar tarafından bağımsız olarak keşfedildiği düşünülmektedir [48, Ekleme Bölümü]. İkili
arama ağaçlarının koşulları değiştirilerek uygulanan tasarımları
sonraki bölümlerde anlatılıyor.
İkili ağacı sıfırdan uygularken birkaç tasarım noktası için karar
vermek gereklidir. Bunlardan ilk soru, her düğüm menşei’ne işaretçi atanmış mıdır? Kökten başlayıp yaprağa giden yol izlerseniz,
menşei işaretçilerini depolamak, zaman ve bellek kaybıdır, buna
gerek yoktur. Ziyaret performansı açısından düşünürseniz, menşei
kayıtlarını savunabilirsiniz. Özyinelemeli olarak veya belirli bir
Yığıt
yoluyla bunu gerçekleştirmek mümkündür. Diğer bazı işlem-
ler için de (eş-yükseklikli ikili arama ağaçlarındaki ekleme veya
silme gibi) menşei kayıtları tavsiye edilir.
246|
Başka bir tasarım sorusu, her düğüm için ana-baba’yı nasıl temsil
etmek gerekir? Bu bölümdeki gerçekleştirim, ayrı değişkenler yardımıyla ana-baba’yı gösterdi. Başka bir seçenek, uzunluğu 3 olan
bir dizidir. Burada, p ana-baba’yı gösterir. u.p[0] sol çocuğu,
u.p[1]
sağ çocuğu, u.p[2] menşei gösterir. Bu gösterimle, bir dizi if
kontrol cümlesini, cebirsel ifadeler halinde sadeleştirilebilirsiniz.
Ağaç ziyareti sırasında, böyle bir sadeleştirmeye rastlarız. u.p[i]
yönünden gelen bir ziyaretin bir sonraki adımı, (u.p[i+1]
3)
mod
yönünden gelir. Sağ-sol simetrisi olduğunda, benzer örnekler
ortaya çıkar. u.p[i] için ağaçta kardeş görünüyorsa, bu muhakkak ki
(u.p[i+1] mod 2) düğümüdür (ikili ağaç olduğu için). u.p[i], sol (i
= 0)
ya da sağ (i = 1) çocuk olsa da, bu ifade doğrudur. Böylece,
bazı karmaşık kodların sağ ve sol versiyonlarını, solaÇevir(u),
sağaÇevir(u)
yöntemlerinde olduğu gibi, iki defa yeniden yazma-
mız gerekli olmaz.
Alıştırma 6.1. n ≥ 1 düğüme sahip ikili ağacın kenar sayısı n – 1
midir? Kanıtlayın.
Alıştırma 6.2. n ≥ 1 gerçek düğüme sahip ikili ağacın dış düğüm
sayısı n + 1 midir? Kanıtlayın.
Alıştırma 6.3. T ikili ağacının en az bir yaprağı varsa, (a) T'nin
kökü en az bir çocukludur. (b) T birden fazla yapraklıdır. Kanıtlayın.
| 247
Alıştırma 6.4. u düğümünden köklü bir altağacın boyutunu hesaplayan boyut2(u) adında özyinelemeli-olmayan işlemi uygulayın.
Alıştırma 6.5. İkili Arama Ağacı’ndaki bir u düğümünün yüksekliğini hesaplayan yükseklik2(u) adında özyinelemeli-olmayan işlemi
uygulayın.
Alıştırma 6.6. Eş-yükseklikli ikili ağacın boyutu dengelidir.(Tanım: her u düğümü için sol ve sağ altağaçların düğüm sayısı
(eleman) en fazla bir adet farklılık gösterirse, ağaca boyut-dengeli
denir). boyutDengeli() adında özyinelemeli bir işlemi uygulayın.
Ağaç, boyut dengeli ise, true döndürmelidir. İşlem, O(n) zamanda
çalışmalıdır. Düğümleri farklı konumlarda bulunan büyük ağaçlarda kodu test edin. O(n) sınırını sağlamayan ve daha çok zaman alan
bir kodu yazmak, nispeten kolay olacaktır.
İkili ağaçta öncül-sıra ziyareti, her u düğümünü çocuklarından önce ziyaret eder. İçsel-sıra ziyareti, her u düğümünün sol altağacını,
hemen ardından sağ altağacını ziyaret ettikten sonra, u düğümünü
ziyaret eder. Ardıl-sıra ziyareti, her u düğümünün altağaçlarını ziyaret ettikten sonra, u düğümünü ziyaret eder. Ağacın düğüm konumu öncül / içsel / ardıl sırada ise elemanlarının öncül / içsel /
ardıl ziyarete göre sıralanması uygun olacaktır. 0,….,n – 1 için bir
örnek Şekil 6.10’da verilmiştir.
Alıştırma 6.7. İkili Ağaç’ın bir alt sınıfını oluşturun. Bu alt sınıfın
veri alanları, öncül-sıra, ardıl-sıra, ve içsel-sıralı sayıları depola-
248|
makta kullanılmalıdır. öncülSıradaSayılar(), içselSıradaSayılar()
ve ardılSıradaSayılar() işlemlerini özyinelemeli olarak uygulayın.
Bu işlemler, ağaçta depolanan sayıları, belirtilen sırada yazdırmalıdır. Her bir işlem O(n) zamanda çalışmalıdır.
Alıştırma
6.8.
Özyinelemeli
sonrakiİçselSıra(u),
olmayan
sonrakiÖncülSıra(u),
ve sonrakiArdılSıra(u) fonksiyonlarını uygu-
layın. Bu işlemler, u’dan sonra gelen düğümü sırasıyla öncülsırada, içsel-sırada ve ardıl-sırada döndürmelidir. Amortize sabit
zamanda çalışmalıdır. Herhangi bir u düğümünden başladığınızda,
bu fonksiyonlardan birini tekrar tekrar çağırırsanız, u=null olana
kadar dönüş değerini u’ya atadığınız takdirde, tüm bu çağrıların
maliyeti O(n) olmalıdır.
| 249
Alıştırma 6.9. Düğümlerinde öncül-, ardıl- ve içsel-sırada depolanan sayıları olan ikili ağacın verildiğini varsayın. Aşağıda belirtilen
işlemlerin sabit zamanda çalışması için bu sayıları nasıl kullanabileceğinizi gösterin:
250|
1.
u
düğümü verildiğinde, u düğümünden başlayan altağacın bo-
yutunu belirleyin.
2.
u
düğümü verildiğinde, u düğümünün derinliğini belirleyin.
3.
u
ve w düğümleri verildiğinde, u düğümü, w’nin atası mıdır?
Belirleyin.
Alıştırma 6.10. Öncül-sıra ve içsel-sırada depolanan düğümlerin
verildiğini varsayın. Bu sıralamaya uygun en fazla bir adet ağacın
var olduğunu kanıtlayın, ve ağacın nasıl düzenleneceğini gösterin.
Alıştırma 6.11. n düğümü olan herhangi bir ikili ağacın en fazla
2(n – 1)
bit kullanarak temsil edilebileceğini gösterin (İpucu: Ziya-
ret ettiğiniz düğümleri kaydedin ve ağacı yeniden oluşturmak için
kaydettiklerinizi yeniden çalıştırın).
Alıştırma 6.12. Şekil 6.5’teki ikili arama ağacına 3,5 ve 4,5 değerlerini eklediğinizde neler olacağını gösterin.
Alıştırma 6.13. Şekil 6.5’teki ikili arama ağacından 3 ve 4 değerlerini sildiğinizde neler olacağını gösterin.
Alıştırma
6.14.
küçükEşitListesi(x)
İkili
Arama
Ağacı
veri
yapısına
ait
işlemini uygulayın. Bu işlem, x elemanından
küçük ya da eşit düğümlerin listesini döndürür. x elemanından küçük ya da eşit eleman sayısı n’ ile belirtildiğinde, ve h ağacın yüksekliğiyse, işlem O(n’ + h) zamanda çalışmalıdır.
| 251
Alıştırma 6.15. Başlangıçta boş olan İkili Arama Ağacı’na {1,…,n}
elemanları kaç değişik şekilde eklenebilir ki, ağacın yüksekliği n –
1
olsun?
Alıştırma 6.16. İkili Arama Ağacı üzerinde, önce ekle(x), hemen
ardından sil(x) gerçekleştirirseniz (x aynı değeri taşıyor), arama
ağacındaki düğümlerin konumları değişir mi? Orijinal ağaca, zorunlu olarak, geri döner miyiz?
Alıştırma 6.17. İkili Arama Ağacı’nda sil(x) işlemi, herhangi bir
düğümün yüksekliğini arttırabilir mi? Artırırsa, ne kadar artırır?
Alıştırma 6.18. İkili Arama Ağacı’nda ekle(x) işlemi, herhangi bir
düğümün yüksekliğini arttırabilir mi? Ağacın yüksekliğini artırabilir mi? Artırırsa, ne kadar artırır?
Alıştırma 6.19. İkili Arama Ağacı’nın bir versiyonunu tasarlayın ve
uygulayın. Her u düğümü, u.boyut (u düğümünden başlayan
altağacın boyutu), u.derinlik (u düğümünün derinliği), ve
u.yükseklik (u
ekle(x)
düğümünün yüksekliği) veri alanlarını saklamalıdır.
ve sil(x) işlemlerine yapılan çağrıların maliyeti sabit oran-
dan daha fazla artmamak kaydıyla, bu değişkenler veri yapısına
dahil edilmelidir.
252|
| 253
Bölüm 7
Rasgele İkili Arama Ağaçları
Bu bölümde, rasgelelik kullanarak, tüm işlemler için O(log n) beklenen çalışma zamanını gerçekleştiren Rasgele İkili Arama Ağacı
veri yapısını tanıtacağız.
Rasgele İkili Arama Ağaçları
Şekil 7.1’de verilen, her biri n = 15 düğümlü iki adet ikili arama
ağacını göz önünde bulundurun. Soldaki bir listedir, ve sağdaki
tamamen dengeli ikili arama ağacıdır. Soldaki ağaç, n – 1 = 14
yüksekliğe sahiptir, sağdaki ağacın yüksekliği ise 3’tür.
Bu iki ağacın nasıl oluşturulduğunu düşünelim. Boş bir yapı ile
başlandığında, ve aşağıdaki veri dizisini İkili Arama Ağacı’na sırasıyla ekleyerek soldaki ağaç elde edilmiştir.
Başka bir sırayla gerçekleştirilen hiçbir ekleme, bu ağacı oluşturamaz (n üzerinde tümevarım yöntemiyle kanıtlayabilirsiniz). Diğer
254|
taraftan, sağdaki ağaç, aşağıdaki veri dizisinin eklenmesiyle oluşturulabilir:
Aşağıdaki diğer diziler de bu ağacı oluşturmak için kullanılabilir:
ve
İşin gerçeği, sağdaki ağacı oluşturan 21.964.800 ekleme dizisi varken, sadece bir adet dizi soldaki ağacı oluşturur.
Yukarıdaki örnekten bazı bulguları çıkarabiliriz: 0…14 aralığındaki sayıların rasgele permütasyonunu seçtiğimizde, ve bu sayıları
ikili arama ağacına eklediğimizde, çok dengeli bir ağacı (Şekil
7.1’in sağ tarafı) elde etme olasılığımız, çok dengesiz bir ağacı
(Şekil 7.1’in sol tarafı) elde etme olasılığımızdan daha fazladır.
| 255
Bu kavramı rasgele ikili arama ağaçlarını inceleyerek şekillendirebiliriz: n boyutunda bir rasgele ikili arama ağacı şöyle elde edilir:
0,…,n – 1
arasında rasgele x0,…,xn-1 permütasyonu seçin ve ele-
manlarını teker teker İkili Arama Ağacı’na ekleyin. Rasgele
permütasyon şu anlamdadır: 0,…,n – 1 sayılarının mümkün olan
her bir n! permütasyonu (sıralaması) eşit derecede olasıdır, yani
herhangi bir permütasyonu elde etme olasılığı 1/n! olur.
Unutmayın ki, 0,…,n – 1 değerleri, Rasgele İkili Arama Ağacı’nın
özelliklerinden herhangi birini değiştirmeden, herhangi bir sıralı n
eleman dizisi ile yer değiştirebilir. x
{0,…,n – 1}
elemanı, n
boyutunda sıralı bir küme içinde, x’nci sıradaki elemana vekalet
ediyor.
Rasgele İkili Arama Ağaç’ları
ile ilgili başlıca sonucumuzu tanıt-
madan önce, konudan biraz uzaklaşarak, randomize yapılar incele-
256|
nirken sık sık gündeme gelen bir sayı türünü gündeme getireceğiz.
Negatif olmayan bir k tamsayısı için, Hk ile gösterilen k’nci
harmonik sayı,
olarak tanımlanır.
Harmonik sayı Hk için hiçbir basit, kapalı yapı yoktur, ama çok
yakından k’nın doğal logaritması ile ilgilidir. Özellikle,
yazılabilir. Fark edebileceğiniz gibi,
olması nede-
niyle bu böyledir. İntegrali bir eğri ve x-ekseni arasında kalan alan
olarak
yorumlayabileceğinizi
akılda
tutarak,
integrali tarafından alttan-sınırlı, ve
Hk
değerinin
tara-
| 257
fından üstten-sınırlı olduğunu kaydedebilirsiniz. (Grafiksel açıklama için, bkz. Şekil 7.2).
Önerme 7.1. n boyutunda Rasgele İkili Arama Ağacı’nda, aşağıdaki ifadeler doğrudur:
1. Herhangi bir x
{0,…,n – 1}
uzunluğu
2. Herhangi bir x
için, arama yolunun beklenen
olur.
(–1, n) \ {0,…,n – 1}
beklenen uzunluğu
için, arama yolunun
olur.
Önerme 7.1’i sonraki bölümde kanıtlayacağız. Şimdilik ilgilenmemiz gereken konu, Önerme 7.1’in iki bölümü ne anlatıyor? Birinci
bölüm, n boyutunda bir ağaçta bulunan bir eleman için arama yaparsanız, arama yolunun en fazla 2ln n + O(1) beklenen uzunlukta
olduğunu bize anlatır. İkinci bölüm ağaçta depolanmayan bir değer
için yapılan arama hakkında aynı sonucu anlatır. Önermenin bu iki
bölümünü karşılaştırdığımızda, ağaçta yer alan bir elemanı aramanın, ağaçta bulunmayan bir elemanı aramaktan sadece biraz daha
hızlı olduğunu söyleyebiliriz.
258|
Önerme 7.1’in Kanıtı
Önerme 7.1’i kanıtlayacak anahtar gözlem şudur: T’yi oluşturmak
için kullanılan rasgele permütasyonda, i, ancak ve ancak
elemanlarından önce geliyorsa, i
x
anahtarlı
bir düğüm, (–1, n) açık aralığındaki x’in arama yolu üzerinde bulunur.
Bunu görmek için Şekil 7.3’ten fark etmelisiniz ki,
elemanlarından biri eklenene kadar,
açık aralığındaki
her değer için arama yolları özdeştir (Unutmayın ki, iki değerin
farklı arama yolları olması için, ağaçta, onlarla karşılaştırma değerleri farklı olan bazı elemanların bulunması gerekir).
içinde rasgele permütasyonda görünür ilk eleman j olsun.
| 259
Dikkat edin, x’in her arama yolunda, j, yol üzerinde bulunmak,
yani görünmek zorundadır. Elemanların farklı olduğu durumda,
yani j
i
ise, j elemanını içeren uj düğümü, i elemanını içeren ui
düğümünden önce oluşturulmuştur, demek kesin olarak doğrudur,
çünkü i
j
(soldan sağa doğru yer alırlar). Bu nedenle, şu da kesin
olarak doğrudur ki, ağaca i elemanı eklendiğinde, uj.left kökenli
altağaca eklenir. Diğer taraftan, x için arama yolu bu altağacı hiçbir
zaman ziyaret etmeyecektir, çünkü uj düğümünü ziyaret ettikten
sonra uj.right altağacına doğru ziyarete devam edecektir.
Benzer şekilde, i
x
için, T’yi oluşturmak için kullanılan rasgele
permütasyonda i, ancak ve ancak
elemanla-
rından önce geliyorsa, i düğümü, x’in arama yolu içinde yer alır.
Fark etmelisiniz ki, {0,…,n} rasgele permütasyonu ile başladığınızda,
ve
altdizileri de sırasıy-
la kendi elemanlarının rasgele permütasyonlarıdır. O zaman,
ve
eşit
olasılıkla,
altkümelerinin her elemanı,
T’yi
oluşturmak
için
kullanılan
rasgele
permütasyondaki herhangi bir elemandan önce görünecektir. Bu
nedenle,
Bu gözlem ile, Önerme 7.1’in kanıtı, harmonik sayılar ile yapılan
bazı basit hesaplamaları gerektirmektedir:
260|
Önerme 7.1’in Kanıtı. i, x’in arama yolunda bulunuyorsa Ii gösterge rasgele değişkeninin değeri 1, aksi takdirde 0 olsun. O zaman
arama yolunun uzunluğunu,
olarak yazabiliriz.
Bu nedenle, x
{0,…,n – 1}
luğu (bkz. Şekil 7.4.a),
için arama yolunun beklenen uzun-
| 261
olarak hesaplanır.
x
(–1, n) \ {0, …, n – 1}
arama değerleri için ilgili hesaplama-
lar hemen hemen aynıdır (bkz. Şekil 7.4.b).
262|
Özet
Aşağıdaki teorem Rasgele İkili Arama Ağacı’nın performansını
özetlemektedir:
Teorem 7.1: Rasgele İkili Arama Ağacı, O(n logn) zamanda oluşturulabilir. Rasgele İkili Arama Ağacı’nda, bul(x) işlemi, O(log n)
beklenen zamanda çalışır.
Tekrar vurgulamalıyız ki, Teorem 7.1’deki beklenen zaman,
Rasgele İkili Arama Ağacı’nı
oluşturmak için kullanılan rasgele
permütasyona bağlıdır. Özellikle, rasgele x seçimlerine bağlı değildir; ve her x değeri için bu doğrudur.
| 263
Treap: Rasgele İkili Arama Ağaçları
Rasgele İkili Arama Ağaç’ları
ile ilgili sorun, tabii ki, dinamik ol-
mamalarıdır. Sıralı Küme arayüzünü uygulamak için gerekli ekle(x)
veya sil(x) işlemlerini desteklemezler. Bu bölümde, Sıralı
Küme
arayüzünü uygulamak için Önerme 7.1’i kullanan, Treap
adında bir veri yapısını tanımlıyoruz.
Treap
düğümü, İkili Arama Ağacı düğümüne benzer şekilde, bir x
veri değerine ve aynı zamanda p adı verilen, rasgele ve tekil olarak
atanan bir sayısal öncelik değerine sahiptir:
264|
İkili Arama Ağacı
olmasının yanı sıra, Treap düğümleri Yığın özel-
liklerini de sağlar:
(Yığın Özelliği) Kök hariç, her u düğümünde,
u.parent.p
u.p
Diğer bir deyişle, her düğüm iki çocuğundan daha az önceliğe sahiptir. Şekil 7.5’te bir örnek gösterilmiştir.
Her düğüm için key(x) ve priority(p) tanımlanmasıyla birlikte,
Yığın
ve İkili Arama Ağacı koşulları Treap şeklini tam olarak belir-
ler. Yığın özelliği, minimum öncelikli, r düğümünün kök olması
gerektiğini sağlar. İkili Arama Ağacı özelliği r.x’den küçük anahtara sahip tüm düğümlerin r.left kökenli altağaçta depolanmasını, ve
r.x’den
büyük anahtara sahip tüm düğümlerin r.right kökenli
altağaçta depolanmasını sağlar.
Treap’te
öncelik değerleri hakkında önemli olan bir nokta, onların
tekil ve rasgele atanmalarıdır. Bu nedenle, Treap düşüncesi için iki
eşdeğer yol vardır: Yukarıda tanımlandığı gibi Treap, Yığın ve İkili
Arama Ağacı
özelliklerini sağlar. Alternatif olarak, Treap düğümle-
rini artan öncelik sırasıyla eklenen bir İkili Arama Ağacı olarak
düşünebilirsiniz. Örneğin, Şekil 7.5’te Treap,
(x, p)
sıralı ikili değerlerinin İkili Arama Ağacı’na eklenmesiyle
oluşturulabilir.
| 265
Öncelikler rasgele seçilmiş olduğu için bu, anahtarların rasgele
permütasyonunu almakla eşdeğerdir – bu durumda permütasyon,
olur, ve İkili Arama Ağacı’na bu elemanlar eklenir. Böylece oluşturulan Treap şekli, Rasgele İkili Arama Ağacı ile aynıdır. Özellikle,
her x anahtarını, permütasyon sırası ile yer değiştirirsek, Önerme
7.1 geçerlidir. Önerme 7.1 Treap bakımından yeniden düzenlenerek
şu hale gelir:
Önerme 7.2. n anahtardan oluşan S eleman dizisini depolayan bir
Treap
için, aşağıdaki açıklamalar geçerlidir:
1. Her x
S
için, x için arama yolunun beklenen uzunluğu,
olur.
2. Her x
S
için, x için arama yolunun beklenen uzunluğu,
olur.
r(x) burada, S
{x}
içinde x’in sırasını göstermektedir.
Yine vurgulamalıyız ki, Önerme 7.2’deki beklenen uzunluk, her
düğüm için rasgele öncelik seçimleri üzerinden alınmıştır. Anahtarların rasgeleliği hakkında herhangi bir varsayım gerekli değildir.
Önerme 7.2, Treaps veri yapısının bul(x) işlemini verimli olarak
uygulayabileceğini anlatıyor. Ancak, Treap veri yapısının gerçek
266|
yararı, ekle(x) ve sil(x) işlemlerini destekleyebilmesidir. Bunu
yapmak için, Yığın özelliğini korumak için birkaç döndürüş gerçekleştirmeye ihtiyaç vardır (bkz. Şekil 7.6). İkili Arama Ağacı’nda
döndürüş, İkili Arama Ağacı özelliğini koruyarak, w düğümünün
menşei olan u üzerinde yapılan yerel bir değişikliktir. Döndürüşle,
w
düğümünün menşei olan u alınır, ve u menşei olarak w düğümü
belirlenir. İki çeşit döndürüş vardır: w düğümünün sol veya sağ
çocuk olmasına bağlı olarak sırasıyla, sola döndürüş ve sağa döndürüş.
Döndürüşü gerçekleştiren kod, bu iki olasılığı işlemek zorundadır
ve (u kök olduğunda) sınır değerlere dikkat edilmelidir, böylece
ortaya çıkan gerçek kodun uzunluğu Şekil 7.6’da gösterildiğinden
daha uzundur.
| 267
268|
Treap
veri yapısı açısından, bir döndürüşün en önemli özelliği, w
derinliğinin 1 azalması ve u derinliğinin 1 artmasıdır.
Döndürüşleri kullanarak, ekle(x) işlemini aşağıdaki gibi gerçekleştirebilirsiniz: Yeni bir u düğümü oluştururuz, u.x = x olarak belirleriz, ve u.p için rasgele değer atarız. Bundan sonra, İkili Arama
Ağacı
için olağan ekle(x) algoritmasını kullanarak, x elemanını
ekleriz. u şimdi Treap veri yapısının yaprağı olmuştur. Bu noktada
Treap, İkili Arama Ağacı’nın
Yığın
özelliğini yerine getirmektedir, ancak
özelliğini sağlaması hakkında kesin bir şey söyleyemeyiz.
Özellikle, u.parent.p > p durumu söz konusu olabilir. Bu durumda
ise, w=u.parent iken, w’nin menşei u olacak şekilde bir döndürüş
gerçekleştirilir. u, Yığın özelliğine aykırı olmaya devam ederse, her
tekrarlamada u derinliği 1 azaltılarak, u kök olana kadar veya
u.parent.p
ekle(x)
u.p
olana kadar döndürüş tekrarlanır.
işleminin bir örneği, Şekil 7.7’de gösterilmiştir.
| 269
ekle(x)
işleminin çalışma zamanı, x için yapılan arama yolunun
izlenmesi için gereken süre, ve yeni eklenen u düğümünün, Treap
içinde, olması gerektiği doğru yere kadar taşınması için gerçekleştirilen döndürüş sayısına bağlıdır. Önerme 7.2 ile, arama yolunun
beklenen uzunluğu en fazla 2ln n + O(1) olarak belirlenmiştir.
Ayrıca, her bir döndürüşün, u derinliğini azalttığı biliniyor. u kök
olduğunda döndürüş sona ermelidir, bu nedenle beklenen döndürüş
sayısı, gerçekleştirilen arama yolunun beklenen uzunluğundan fazla
olmamalıdır. Bu nedenle, Treap tarafından gerçekleştirilen ekle(x)
işleminin beklenen çalışma zamanı O(log n) olarak kaydedilir
(Alıştırma 7.5 bir ekleme sırasında gerçekleştirilen beklenen döndürüş sayısının O(1) olduğunu göstermenizi istiyor).
270|
Treap
içinde sil(x) işlemi ekle(x) işleminin zıttıdır. x içeren u dü-
ğümünü ararız, sonra u bir yaprak haline gelinceye kadar, u düğümünü aşağı yönde hareket ettirecek döndürüşleri gerçekleştiririz.
Treap
yapısından u çıkarılarak, u’ya bağlı düğümleri birbirine uç
uça ekleriz. Fark edebilirsiniz ki, u düğümünü aşağı yönde hareket
ettirmek için u düğümünü, sırasıyla, u.left veya u.right ile yer değiştiren, sola veya sağa döndürüşü yerine getirebilirsiniz. Aşağıdakilerden hangisi önce geçerliyse, seçim onun tarafından yapılır:
1.
u.left
ve u.right, her ikisi de null ise, o zaman u bir yapraktır
ve hiçbir döndürüş uygulamayın.
2.
u.left
(veya u.right) null ise, u düğümünden sağa doğru (veya
sırasıyla, sola doğru) döndürüş uygulayın.
3.
u.left.p
u.right.p
(veya u.left.p
u.right.p)
ise, sağa doğru
(veya sırasıyla, sola doğru) döndürüş uygulayın.
Bu üç kural, Treap yapısının bağlantılarını koparmadan, u düğümü
silindiğinde de, Yığın özelliğinin korunmasını sağlar.
sil(x)
işleminin bir örneği, Şekil 7.8’de gösterilmiştir.
sil(x)
işleminin çalışma zamanını analiz etmek için gerekli olan
beceri, bu işlemi ekle(x) işleminin zıttı olarak fark edebilmektir.
Özellikle, aynı öncelikteki u.p kullanarak x değerini yeniden eklemek isteseydik, ekle(x) işlemi aynı sayıda tam döndürüş yapardı,
ve Treap özelliklerini, sil(x) işleminin gerçekleşmesinden önceki
duruma getirerek yeniden korurdu.
| 271
(Aşağıdan-yukarıya doğru okunduğunda, Treap içine 9 değerinin
eklenmesi, Şekil 7.8’de gösterilmiştir). n boyutundaki Treap için
sil(x)
işleminin beklenen çalışma zamanı, n – 1 boyutundaki Treap
için ekle(x) işleminin beklenen çalışma zamanı ile orantılıdır. Sonuç olarak, sil(x) işlemi O(log n) beklenen zamanda çalışır.
272|
Özet
Aşağıdaki teorem Treap veri yapısının performansını özetlemektedir:
Teorem 7.1: Treap, Sıralı Küme arayüzünü uygular. Treap, işlem
başına O(log n) beklenen zamanda çalışan ekle(x), sil(x) ve
bul(x)
işlemlerini destekler.
Treap
veri yapısını Sıralı Küme Sekme Listesi ile karşılaştırmak
dikkate değerdir. Her ikisi de O(log n) zamanda çalışan işlemleri
destekliyor. Her iki veri yapısı da, ekle(x) ve sil(x) işlemleri sırasında yapılan arama sonrasında, sabit sayıda işaretçi değişikliklerini
gerçekleştirir (bkz. Alıştırma 7.5). Bu nedenle, her iki yapı için,
performans üzerine etki eden en kritik değer, arama yolunun beklenen uzunluğudur. Sıralı Küme Sekme Listesi’nde arama yolunun
beklenen uzunluğu,
ile verilmişti. Treap için bu sayı,
olarak verilir.
| 273
Bu durumda, Treap arama yolları Sekme Liste’lerine göre daha
kısadır ve bununla beraber, farkedilir derecede daha yüksek hızlı
işlemleri Treap veri yapısı üzerinde uygulayabilirsiniz.
Bölüm 4’te verilen Alıştırma 4.7, Sekme Listesi’nde arama yolunun beklenen uzunluğunu, hileli para fırlatarak nasıl,
sayısına azaltabileceğimizi gösteriyor. Bu iyileştirme ile bile olsa,
Sıralı Küme Sekme Listesi’nin
Treap
beklenen arama uzunluğu yolu
ile karşılaştırıldığında daha uzundur.
274|
| 275
276|
Tartışma ve Alıştırmalar
Rasgele ikili arama ağaçlar yaygın olarak kullanılmaktadır. Önerme
7.1’in kanıtı ve ilgili sonuçları Devroye [19] tarafından verilmiştir.
Literatürde daha kuvvetli sonuçlar da bulunmaktadır, başlıcası
Reed [64] tarafından, Rasgele İkili Arama Ağacı’nın beklenen yüksekliğinin
olduğunu göstermiştir. Burada,
aralığındaki tekil çözümü 4,31107, ve
denkleminin
ve-
rilmiştir. Ayrıca, yüksekliğin değişkenliği sabittir.
Treap
adı Seidel ve Aragon [67] tarafından bilime kazandırılırken,
bazı varyasyonları da tartışılmıştır. Ancak, temel yapısı Vuillemin
[76] tarafından çok daha önceden Kartezyen Ağaçlar adıyla çalışılmıştır.
Treap
p
veri yapısı için olası bir alan-optimizasyonu, her düğümdeki
öncelik alanının açıkça saklanmasından vazgeçmektir. Bunun
yerine, bir, u düğümünün önceliği, u adresinin bellekteki karma
değeri olarak hesaplanır (32-bit Java’da, u.hashCode() fonksiyonuyla karma yapılabilir). Pek çok karma fonksiyonu bu uygulama
için muhtemelen iyi çalışsa da, Önerme 7.1’in kanıtını oluşturan
önemli parçaların geçerliliğini yitirmemesi için karma fonksiyonu
randomize edilmelidir, ve asgari bağımsızlık özelliğine sahip olma-
| 277
lıdır:
Birbirinden
h(x1),…,h(xk)
ayrı,
herhangi
x1,…,xk
değerleri
için
karma değerlerinin her biri yüksek olasılıkla birbi-
rinden farklı olmalıdır, ve her i
{1,…,k}
için,
eşitsizliğini sağlayan bir c sabiti vardır. Bu tür karma fonksiyonları
arasında, uygulaması kolay ve oldukça hızlı olan bir tanesi listeleme karmadır (bkz. Listeleme Karma Yöntemi Bölümü).
Her düğüm noktasında öncelikleri depolamaya gerek duymayan bir
başka Treap varyasyonu, Martinez ve Roura [51] tarafından bilime
kazandırılan randomize ikili arama ağacıdır. Bu varyasyonda, her u
düğümünde, u kökenli altağacın boyutu u.boyut ile tanımlıdır. ekle(x)
ve sil(x) algoritmalarının ikisi de rasgeledir. u kökenli alt
ağaca, x elemanının eklenmesi aşağıdakileri yapar:
1. 1/(boyut(u)+1) olasılığıyla, x değeri her zamanki gibi yaprak
olarak eklenir, ve x bu ağacın köküne getirilene kadar döndürüş
gerçekleşir.
2. Aksi takdirde, 1 – 1/(boyut(u)+1) olasılığıyla, x değeri özyinelemeli olarak u.left veya u.right kökenli ağaçlardan uygun
olanına eklenir.
Birinci durum, Treap içindeki ekle(x) işlemine karşılık geliyor.
Burada, x’in düğümü rasgele bir öncelik değeri alır ve bu değer, u
278|
altağacındaki boyut(u) önceliklerinin hepsinden daha küçüktür. Bu
durum tam olarak aynı olasılıkla oluşur.
Randomize
Treap’teki
u
İkili
Arama
Ağacı’ndan
bir x değerini silmek,
silme sürecine benzerdir. x içeren u düğümü bulunur, ve
bir yaprak haline gelene kadar u derinliğini artıran ard arda dön-
dürüşler gerçekleşir. Bu noktada, u ağaçtan çıkarılabilir. Her adımda gerçekleştirilen döndürüşün sola mı, veya sağa mı olması seçimi
randomize edilmiştir.
1. u.left.boyut/(u.boyut – 1) olasılığıyla, u kökenli altağacın
kökü u.left olacak şekilde sağa döndürüş gerçekleştiririz.
2. u.right.boyut/(u.boyut
–
1)
olasılığıyla,
u
kökenli
altağacın kökü u.right olacak şekilde sola döndürüş gerçekleştiririz.
Bu olasılıkların Treap içindeki silme algoritmasının gerçekleştireceği sola veya sağa döndürüşler ile aynı olduğunu kolayca doğrulayabilirsiniz.
Treap
veri yapısı ile karşılaştırıldığında, eleman ekleme ve silme
yaparken, Randomize İkili Arama Ağaç’ların birçok rasgele seçimler yapması dezavantajdır ve altağaçların boyutları korunmak zorundadır. Randomize İkili Arama Ağaç’ların Treap veri yapısına
kıyasla bir avantajı, altağaç boyutunun bir başka yararlı amaca
hizmet edebilmesidir; O(log n) beklenen zamanda sırasına göre
eleman erişimi (bkz. Alıştırma 7.10) sağlar. Treap düğümlerinde
| 279
depolanan rasgele önceliklerin ise, Treap yapısını dengeli halde
tutmak dışında bir kullanım amacı yoktur.
Alıştırma 7.1. Şekil 7.5’te verilen Treap içine (önceliği 7 olan) 4,5
değerinin, ve daha sonra (önceliği 20 olan) 7,5 değerinin eklenmesini gösterin.
Alıştırma 7.2. Şekil 7.5’te verilen Treap içinden 5 ve 7 değerlerinin silinmesini gösterin.
Alıştırma 7.3. Şekil 7.1’in sağ tarafında bulunan ağacın 21.964.800
dizi tarafından oluşturulabileceğini kanıtlayın (İpucu: h yüksekliğine sahip ikili ağacı oluşturacak dizilerin sayısını bir özyinelemeli
formülle ifade edin. h = 3 için formülün değerini hesaplayın).
Alıştırma 7.4. n farklı değerin sırasını rasgele değiştirilmiş şekilde
saklayan a dizisini girdi olarak alan, sırasınıDeğiştir(a) işlemini
tasarlayın ve uygulayın. İşlem, O(n) zamanda çalışmalıdır, ve a
dizisinin her n! permütasyonunun eşit olasılıkla mümkün olabileceğini kanıtlamalısınız.
Alıştırma 7.5. Önerme 7.2’nin her iki bölümünü de kullanarak
ekle(x)
ve sil(x) işlemiyle gerçekleştirilen döndürüşlerin beklenen
sayısının O(1) olduğunu kanıtlayın.
Alıştırma 7.6. Bu bölümde verilen Treap uygulamasını, öncelikleri
açıkça depolamayacak şekilde değiştirin. Bunun yerine, her düğüm,
280|
hashCode()
ile karma fonksiyonunu kullanarak öncelik gibi gös-
termelidir.
Alıştırma 7.7. İkili Arama Ağacı içindeki her u düğümünde, u kökenli altağacın yüksekliği u.yükseklik, ve u kökenli altağacın büyüklüğü, u.boyut değişkenlerinin depolandığını düşünün.
1. u düğümünde, sola ve sağa döndürüş gerçekleştiğinde, döndürüşten etkilenen tüm düğümler için bu iki değişkenin, sabit sürede nasıl güncellenebileceğini gösterin.
2. Her u düğümü için, u derinliğini de depolamaya çalıştığınız
takdirde, aynı sonucun neden geçerli olmadığını açıklayın.
Alıştırma 7.8. n elemandan oluşan sıralı a dizisinin elemanlarını
ekleyerek, Treap oluşturan bir algoritmayı tasarlayın ve uygulayın.
Bu işlem, en kötü O(n) zamanında çalışmalıdır ve a elemanlarını
ekle(x)
Treap
işlemiyle teker teker çağırarak eklediğiniz takdirde, aynı
yapısını elde ediyor olmanız gerekir.
Alıştırma 7.9. Bu alıştırma, Treap içinde aradığınız düğüme yakın
bir işaretçi verildiğinde, nasıl verimli arama yapabileceğinizin detaylarını veriyor.
1. Her düğümün, kendi altağacında bulunan en küçük ve en büyük
değerlerin bilgisini tuttuğu bir Treap uygulamasını tasarlayın ve
uygulayın.
| 281
2. Bu ekstra bilgiyi kullanarak, parmakBul(x, u) işlemini uygulayın. Bu işlem u düğümünü gösteren bir işaretçinin yardımıyla
bul(x)
işlemini çalıştırır (işaretçinin x değerini içeren düğüm-
den fazla uzak mesafede olmaması tercih edilir). Bu işlem u
düğümünden başlar ve w.min
x
w.max
koşulunu sağla-
yan bir w düğümüne ulaşıncaya kadar yukarı yürür. Bu noktadan itibaren, x için w düğümünden başlayarak standart bir arama yapar (Treap içinde bulunan elemanların sayısı r ile ifade
edildiğinde, r değeri x ve u.x arasında iken, parmakBul(x, u)
işleminin O(1 + log r) zamanda çalıştığını gösterebilirsiniz).
3. bul(x) işlemine yapılan her çağrının, bul(x) işleminin en son
çağrısında döndürülen düğümden başlayarak aramayı gerçekleştirmesi için, Treap uygulamasında değişiklikler yapın.
Alıştırma 7.10. Treap içinde i’nci sıradaki anahtarı döndüren al(i)
işlemini gerçekleştiren Treap versiyonunu tasarlayın ve uygulayın
(İpucu: Her u düğümü, u kökenli altağacın boyutu bilgisini saklar).
Alıştırma 7.11. Liste arayüzünün bir Treap şeklinde gerçekleştirildiği, TreapList adındaki veri yapısını uygulayın. Treap içindeki her
düğüm bir Liste elemanını depolar. Treap için yapılan içselsıralamada ziyaret edilen elemanlar aynı sırada, Liste’de göründüğü
sırada görünür. Tüm Liste işlemleri, al(i), belirle(i, x), ekle(i, x) ve
sil(i), O(n)
beklenen zamanda çalışmalıdır.
Alıştırma 7.12. böl(x) işlemini destekleyen bir Treap versiyonunu
tasarlayın ve uygulayın. Bu işlem, Treap içinde depolanmış, x’den
282|
daha büyük olan tüm değerleri siler ve tüm silinen değerleri içeren
ikinci bir Treap döndürür.
Örnek: t2 = t.böl(x) kodu, t içinden x’den daha büyük tüm değerleri ayırır, ve yeni Treap t2 olarak döndürür. böl(x) işlemi, O(log
n)
beklenen zamanda çalışmalıdır.
Uyarı: Bu değişikliğin doğru olması, ve boyut() işleminin sabit
zamanda çalışması için Alıştırma 7.10’da belirtilen değişiklikleri
uygulamanız gerekmektedir.
Alıştırma 7.13. böl(x) işleminin tersi olarak düşünebileceğiniz,
em(t2)
işlemini destekleyen bir Treap versiyonunu tasarlayın ve
uygulayın. Bu işlem, Treap, t2 içindeki tüm değerleri siler, ve alıcıya ekler. Bu işlem, t2 içindeki en küçük değerin, alıcı içindeki en
büyük değerden daha büyük olduğunu önceden varsayar. em(t2)
işlemi O(log n) beklenen zamanda çalışmalıdır.
Alıştırma 7.14. Bu bölümde anlatıldığı üzere, Martinez'in
Randomize İkili Arama Ağaç’larını
uygulayın. Treap uygulaması-
nın performansı ile sizin yazdığınız uygulamanın performansını
karşılaştırın.
| 283
284|
Bölüm 8
Günah Keçisi Ağaçları
Bu bölümde, İkili Arama Ağacı veri yapısı olan, Günah Keçisi Ağacı’nı
inceleyeceğiz. Bu yapı, bir şeyler yanlış gittiğinde, insanların
birilerini suçlamak (günah keçisi) eğiliminde olması gibi bir ortak
akla dayanır. Suçlama sıkıca saptandıktan sonra, sorunu çözmek
için günah keçisini terk edebilirsiniz.
Günah Keçisi Ağacı,
kısmi yeniden yapılandırma işlemleriyle ken-
dini dengeli tutar. Kısmi yeniden yapılandırma işlemi sırasında,
bütün bir altağaç sökülerek parçalarına ayrıştırılır, ve mükemmel
dengeli bir altağaç için yeni baştan kurulur. u-düğümünde köklü bir
altağacı mükemmel dengeli bir ağaç halinde yeniden yapılandırmanın birçok yolu vardır. En basit bir tanesi, u’nun altağacını ziyaret
ederek, bütün düğümlerini bir a dizisinde toplamak, ve sonra a dizisini kullanarak, özyinelemeli olarak dengeli bir altağacı oluşturmaktır. m = a.uzunluk/2 olmasına izin verirsek, a[m] yeni
altağacın kökü haline gelir, a[0],…,a[m–1] sol altağaçta öz yinelemeli olarak depolanır, a[m+1],…,a[a.uzunluk–1] sağ altağaçta
özyinelemeli olarak depolanır.
| 285
yeniden_oluştur(u)
için yapılan bir çağrı O(boyut(u)) zamanda
çalışır. Elde edilen altağaç minimum yüksekliğe sahiptir; boyut(u)
düğüm sayısına sahip olan, daha az yükseklikte hiçbir ağaç yoktur.
286|
Günah Keçisi Ağacı: Kısmi Yeniden
Oluşturmalı İkili Arama Ağacı
Günah Keçisi Ağacı, n
düğüm sayısına ek olarak, n’e üst-sınırı sağ-
layan q sayacını tutan bir İkili Arama Ağacı’dır.
Her zaman için, n ve q, aşağıdaki eşitsizliği sağlar:
| 287
Buna ek olarak, Günah Keçisi Ağacı logaritmik yüksekliğe sahiptir;
günah keçisi ağacının yüksekliği hiçbir zaman aşağıdaki değeri
geçmez:
Hatta bu sınırlamayla bile, Günah Keçisi Ağacı şaşırtıcı biçimde
dengesiz görünebilir. Şekil 8.1’deki ağaçta, q = n = 10, ve yükseklik
olarak belirlidir.
İkili Arama Ağacı’nın
standart arama algoritmasını kullanarak, Gü-
nah Keçisi Ağacı’nda bul(x)
işlemini gerçekleştirebiliriz (bkz. Ser-
best Yükseklikli İkili Arama Ağacı Bölümü). Bu işlemin çalışma
zamanı, ağacın yüksekliği ile orantılı olduğu için (8.1) nedeniyle,
O(log n) zaman alır.
ekle(x)
işlemini gerçekleştirmek için, önce n ve q değişkenlerini 1
artırırız, daha sonra İkili Arama Ağacı’na x değerini eklemek için
her zamanki algoritmayı kullanırız; önce x için arama yaparız, ve
u.x = x
olan yeni bir u yaprağını ağaca ekleriz. Bu noktada şanslı
olabiliriz, ve u derinliği log3/2 q sayısını aşmayabilir. Eğer öyleyse,
Günah Keçisi Ağacı’nı
artık yalnız bırakırız ve hiçbir şey yapma-
yız.
Ne yazık ki, bazen derinlik(u)
log3/2 q
olabilir. Bu durumda,
yüksekliğin azaltılması gereklidir. Bu iş çok fazla zahmet gerektirmez, derinliği log3/2 q sayısını aşan sadece bir adet u düğümü var-
288|
dır. u’yu düzeltmek için, u’dan başlayıp köke doğru günah keçisi
w’yi
arayarak yukarı yürürüz. Günah keçisi w, çok dengesiz bir
düğümdür. Şu özelliğe sahiptir:
Burada, w.child, kökten u düğümüne giden yolda, w düğümünün
çocuğudur. Günah keçisinin var olduğunu çok kısaca kanıtlayacağız. Şimdilik, buna kesin gözüyle bakabiliriz. Bir kez, günah keçisi
w’yi
bulduğumuz zaman, w köklü altağacı tamamen yok ederiz ve
mükemmel dengeli bir ikili arama ağacı halinde yeniden yapılandırırız. (8.2) gösteriyor ki, u eklenmeden önce bile, w altağacı tam
İkili Ağaç
değildi. Bu nedenle, w yeniden yapılandırıldığında, yük-
seklik en az 1 azalır, böylece Günah Keçisi Ağacı’nın yüksekliği
yeniden en fazla log3/2 q olur.
| 289
Günah Keçisi w’yi bulmanın ve w kökenli altağacı yeniden oluşturmanın maliyeti önemsenmediği takdirde, ekle(x) işleminin çalışma zamanı, O(log q) = O(log n) karmaşıklığında yapılan ilk
arama tarafından büyük oranda etkilenir. Günah Keçisi’ni bulmanın
ve yeniden yapılandırmanın maliyetini, amortize analiz kullanarak
sonraki bölümde inceleyeceğiz.
Günah Keçisi Ağacı’nda sil(x)
uygulaması çok basittir. Önce x de-
ğerini ararız, sonra İkili Arama Ağacı’nın standart silme algoritmasını kullanarak sileriz (Unutmayın ki, bu işlem, ağacın yüksekliğini
hiçbir zaman artıramaz). Sonra, n değişkenini 1 azaltır, q değişkenini aynen bırakırız. En sonunda, q
2n
eşitsizliğini kontrol ede-
riz, ve eğer öyleyse, ağacın tümünü, mükemmel dengeli İkili Arama
Ağacı
halinde yeniden yapılandırırız, ve q=n olarak belirleriz.
Yine, yeniden yapılandırma maliyeti önemsenmediği takdirde,
sil(x)
işleminin çalışma zamanı ağacın yüksekliği ile orantılıdır, ve
bu nedenle O(log n) zamanda çalışır.
290|
| 291
Doğruluk Analizi ve Çalışma Zamanı
Bu bölümde Günah Keçisi Ağacı işlemlerinin doğruluğunu ve
amortize çalışma zamanlarını analiz edeceğiz. İlk olarak, doğruluğunu kanıtlamak için, ekle(x) işlemi, (8.1) koşulunu sağlamayan
bir düğüm ile sonuçlanırsa, her zaman bir günah keçisi bulabileceğimizi göstereceğiz.
Önerme 8.1. Günah Keçisi Ağacı’nda derinliği h > log3/2 q olan
bir düğüm u ile verilsin. u’dan köke giden yol üzerinde aşağıdaki
koşulu sağlayan bir w düğümü bulunur:
Kanıt. Bu bağlamda çelişki uğruna, u’dan köke giden yol üzerindeki bütün w düğümleri için,
olduğunu varsayalım.
Kökten u’ya giden yol r = u0,…, uh = u ile ifade edilsin. O zaman,
, ve daha genel olarak,
292|
Ancak boyut(u) ≥ 1 olduğu için bu bir çelişki verir, dolayısıyla,
Ardından, çalışma zamanının henüz açıklanmamış bileşenlerini
analiz edeceğiz. İki bölümü vardır: Günah keçisi düğümlerini ararken boyut(u) için yapılan çağrıların maliyeti ve günah keçisi, w’yi
bulduğumuzda yeniden_oluştur(w) için yapılan çağrıların maliyeti,
boyut(u)
ve yeniden_oluştur(w) için yapılan çağrıların maliyeti ile
aşağıdaki şekilde ilişkili olabilir:
Önerme 8.2. Günah Keçisi Ağacı’nda ekle(x) için yapılan çağrı
sırasında, günah keçisi w’yi bulmanın, ve w kökenli altağacı yeniden yapılandırmanın maliyeti O(boyut(w)) olur.
Kanıt. w günah keçisi düğümünü bulduktan sonra, onu yeniden
yapılandırmanın maliyeti O(boyut(w)) olur. Günah keçisi düğümünü ararken günah keçisi olan uk = w bulunana kadar, u0,...,uk
düğüm dizisi üzerinde boyut(u) çağrısı yaparız. Ancak, bu dizide
günah keçisi olan ilk düğümün uk olması nedeniyle, her i
{0,…,k–2}
için,
| 293
geçerli olduğunu biliyoruz. Bu nedenle, boyut(u) için yapılan tüm
çağrıların maliyeti,
olarak hesaplanır.
Kanıtın son satırında, toplamın aslında geometrik azalan bir dizi
olması gerçeğinden faydalandık.
Önerme 8.3. Boş bir Günah Keçisi Ağacı ile başlandığında, m defa
çağrılan ekle(i, x) ve sil(i) işlemleri sırasında yapılan yeniden_oluştur(u)
çağrıları, en fazla O(m log m) toplam zamanda
çalışır.
Kanıt. Bunu kanıtlamak için kredi şemasını kullanacağız. Her düğümün bir miktar kredi depoladığını düşünelim. Her kredi, yeniden
yapılandırma için harcanan birim zamanı, c sabitiyle öder. Bu şema
O(m log m) toplam kredi gerektirir ve yeniden yapılandırma için
yapılan her çağrı, u düğümünde saklanan kredilerle ödenir.
294|
Ekleme veya silme sırasında, eklenen veya silinen düğüme giden
yol üzerindeki her düğüme 1 kredi veririz. Bu şekilde, işlem başına
en fazla log3/2 q ≤ log3/2 m kredi veririz. Silme sırasında, ayrıca ek
bir kredi saklarız. Böylece toplam olarak, O(m log m) kredi bildiririz. Geriye kalan, bu kredilerin yeniden_oluştur(u) için yapılan
tüm çağrıları ödemeye yeterli olduğunu göstermektir.
Ekleme sırasında yeniden_oluştur(u) çağrılırsa, bunun nedeni
u’nun
günah keçisi olmasıdır. Genelleme kaybına girmeden varsa-
yalım ki,
Aşağıdaki bağıntı gerçeğinden,
çıkarabiliriz ki,
ve bu nedenle,
| 295
Şimdi, u içeren bir altağaç, en son olarak yeniden yapılandırıldığında (veya u eklendiği zaman, u içeren bir altağaç, hiçbir zaman
yeniden yapılandırılmamışsa),
doğrudur. Bu nedenle, o zamandan itibaren u.left ve u.right
altağaçlarını etkileyen ekle(x) veya sil(x) işlem sayısı, en az,
olur ve böylece, u düğümünde depolanan, ve yeniden_oluştur(u)
çağrısı için gerekli O(boyut(u)) zamanı ödemek için, en az bu kadar yeterli kredimiz vardır.
Silme sırasında, q
2n
olduğu zaman yeniden_oluştur(u) çağrısı
yaparız. Bu durumda, ayrıca depolanmış bulunan q – n
n
kredi-
ye sahibiz ve bu kredileri, kökü yeniden yapılandırmak için gerekli
O(n) zamanı ödemek için kullanırız.
Bu kanıtı tamamlar.
296|
Özet
Teorem 8.1. Aşağıdaki teorem Günah Keçisi Ağacı veri yapısının
performansını özetlemektedir:
Günah Keçisi Ağacı, Sıralı Küme
den_oluştur(u)
arayüzünü uygular. yeni-
işlemi için yapılan çağrıların maliyeti önemsenme-
diği takdirde, Günah Keçisi Ağacı işlem başına O(log n) zamanda
çalışan ekle(x), sil(x) ve bul(x) işlemlerini destekler.
Başlangıçta, Günah Keçisi Ağacı düğümleri boş değer taşırken, m
defa çağrılan ekle(i, x) ve sil(i) işlemleri sırasında yapılan yeniden_oluştur(u)
çalışır.
çağrıları, en fazla O(m log m) toplam zamanda
| 297
Tartışma ve Alıştırmalar
Günah Keçisi Ağacı,
Galperin ve Rivest [33] tarafından tanımlan-
mış ve analiz edilmiştir. Ancak, aynı yapı, Genel Dengeli Ağaçlar
adıyla Andersson [5, 7] tarafından daha önce keşfedilmiştir. Bu
yapı, yüksekliği küçük olduğu sürece herhangi bir şekil alabilir.
Günah Keçisi Ağacı
uygulaması ile yapılacak denemeler, genellikle
onların, bu kitaptaki diğer Sıralı Küme uygulamalarından çok daha
yavaş olduğunu ortaya koyacaktır. Bu biraz şaşırtıcı olabilir, çünkü
yükseklik sınırı,
bir Sekme Listesi’ndeki arama yolunun beklenen uzunluğundan
daha iyidir ve Treap’inkinden de çok fazla değildir. Alt ağaçların
boyutlarını her düğümde açıkça depolayarak veya zaten hesaplanmış bulunan altağaç boyutlarını yeniden kullanarak (Alıştırma 8.5
ve 8.6) uygulamayı optimize edebilirsiniz. Bu iyileştirmelerle bile
de olsa, her zaman için, Günah Keçisi Ağacı’nda çalıştırılan bir dizi
ekle(x)
ve sil(x) işlemi, diğer Sıralı Küme uygulamalarından daha
uzun zaman alır.
Bu performans açığı, kitapta tartışılan diğer Sıralı Küme uygulamalarının aksine, bir Günah Keçisi Ağacı’nın kendisini yeniden yapılandırırken aslında çok zaman harcamasına bağlıdır. Alıştırma 8.3,
298|
n
işlem dizisi için Günah Keçisi Ağacı’nın yeniden_oluştur(u) için
yapılan çağrılar sırasında n log n derecesinde zaman harcadığını
kanıtlamanızı istiyor. Bu gerçek, kitabımızda anlatılan diğer Sıralı
Küme uygulamalarının aksine, n işlem dizisi sırasında O(n) yapısal
değişiklik yapılmasını gerektirir. Bu, ne yazık ki, Günah Keçisi
Ağacı’nın
yeniden yapılandırmayı tamamen yeniden_oluştur(u)
için yaptığı çağrılarla gerçekleştirmesinin getirdiği kaçınılmaz bir
sonuçtur. [20].
Performansı iyi olmamasına rağmen, Günah Keçisi Ağacı bazı uygulamalar için doğru seçim olacaktır. Döndürüş sonrasında sabit
zamanda güncellenemeyen, ancak yeniden_oluştur(u) işlemi sırasında güncellenebilen düğümler ile ilişkili, ek veriler olduğu zaman
tercih edilebilir. Bu gibi durumlarda, Günah Keçisi Ağacı ve kısmi
yeniden yapılandırmaya dayalı ilgili yapılar işe yarayabilir. Böyle
bir uygulama örneği Alıştırma 8.11’de gösterilmiştir.
Alıştırma 8.1. Şekil 8.1’de verilen Günah Keçisi Ağacı’na 1,5 ve
1,6 değerlerinin eklenmesini gösterin.
Alıştırma 8.2. Boş bir Günah Keçisi Ağacı’na 1, 5, 2, 4, 3 dizisini
eklediğinizde ne olduğunu gösterin. Önerme 8.3’ün kanıtında kredilerin nereye harcandığını ve bu verileri eklerken kredilerin nasıl
kullanıldığını açıklayın.
Alıştırma 8.3. Boş bir Günah Keçisi Ağacı ile başlandığında, ve
x = 1, 2, 3, ...,n
için ekle(x) işlemini çağırdığınızda, yeni-
| 299
den_oluştur(u)
için yapılan çağrılar sırasında, bazı sabit c
0
için
çalışma zamanının en az cn log n olduğunu gösterin.
Alıştırma 8.4. Günah Keçisi Ağacı, arama yolunun, bu bölümde
anlatıldığı gibi, log3/2 q uzunluğunu aşmayacağını garanti eder.
1. 1 < b < 2 aralığında verilen bir b parametresi için arama
yolu uzunluğu en fazla logb q olan, değiştirilmiş bir Günah
Keçisi Ağacı
versiyonunu tasarlayın, analiz edin ve uygula-
yın.
2. Analiziniz ve/veya deneyleriniz, n ve b cinsinden birer
fonksiyon olarak, bul(x), ekle(x) ve sil(x) işlemlerinin
amortize maliyetleri hakkında ne söylemektedir?
Alıştırma 8.5. Günah Keçisi Ağacı’nın ekle(x) yöntemini değiştirin. Yeni versiyon, zaten hesaplanmış olan altağaçların boyutlarını
tekrar hesaplamak için zaman harcamamalıdır. Bu mümkündür,
çünkü, boyut(w) değerini hesaplamak istediğiniz zaman, boyut(w.left)
veya boyut(w.right)’dan birini zaten hesaplamış olma-
nız gerekir. Değiştirdiğiniz uygulama ile bu bölümde verilen uygulamanın performansını karşılaştırın.
Alıştırma 8.6. Günah Keçisi Ağacı veri yapısının ikinci bir versiyonunu uygulayın. Her bir düğüm, o düğümde kökenli altağacın
boyutunu açıkça depolamalıdır. Bu uygulamanın performansını,
orijinal Günah Keçisi Ağacı uygulaması ile, ve bunun yanı sıra,
Alıştırma 8.5’te değiştirdiğiniz uygulama ile karşılaştırın.
300|
Alıştırma 8.7. Bu bölümün başında tartışılan yeniden_oluştur(u)
yöntemini yeniden uygulayın. Bu uygulamada, yeniden yapılandırılacak altağacın düğümlerini saklayan bir dizinin kullanımı gerekli
değildir. Bunun yerine, düğümleri önce bir bağlantılı liste halinde
birleştirmek için özyineleme kullanın, ve sonra bu bağlantılı listeyi
mükemmel dengeli ikili ağaca dönüştürün (İki adımın da çok iyi
özyinelemeli uygulamaları vardır).
Alıştırma 8.8. Ağırlıklı Dengeli Ağacı analiz edin ve uygulayın.
Kök dışında, her u düğümü, boyut(u) (2/3) boyut(u.parent) ile
verilen denge değişmezini korur. ekle(x) ve sil(x) işlemleri standart
İkili Arama Ağacı
işlemleri ile aynıdır. Ancak, herhangi bir u dü-
ğümünde denge değişmezi ihlal edildiğinde, u.parent kökenli
altağaç yeniden yapılandırılır. Analiziniz, Ağırlıklı Dengeli Ağaç
işlemlerinin O(log n) amortize zamanda çalıştığını göstermelidir.
Alıştırma 8.9. Geri Sayım Ağacı’nı analiz edin ve uygulayın. Her u
düğümü u.t zamanlayıcısını tutar. ekle(x) ve sil(x) işlemleri standart İkili Arama Ağacı işlemleri ile aynıdır. Ancak, bu işlemlerden
biri u’nun altağacını etkilediği zaman, u.t 1 azaltılır. u.t = 0 iken, u
kökenli altağacın tümü mükemmel dengeli ikili ağacı halinde yeniden yapılandırılır. u düğümü, yeniden yapılandırma işlemine dahil
edildiyse (u veya u’nun atalarından biri yeniden yapılandırıldıysa),
u.t
değeri boyut(u) / 3 olarak ayarlanır.
| 301
Analiziniz, Geri Sayım Ağacı işlemlerinin O(log n) amortize zamanda çalıştığını göstermelidir. (İpucu: Öncelikle, her u düğümünün denge değişmezinin bazı versiyonunu sağladığını gösterin.)
Alıştırma 8.10. Dinamit Ağacı’nı analiz edin ve uygulayın. Her u
düğümü u.boyut değişkeninde u kökenli altağacın boyutunu tutar.
ekle(x)
ve sil(x) işlemleri standart İkili Arama Ağacı işlemleri ile
aynıdır. Ancak, bu işlemlerden biri u’nun altağacını etkilediği zaman, 1 / u.boyut olasılıkla u patlar. u patladığında, altağacının
tümü mükemmel dengeli ikili ağacı halinde yeniden yapılandırılır.
Analiziniz, Dinamit Ağacı işlemlerinin O(log n) beklenen zamanda
çalıştığını göstermelidir.
Alıştırma 8.11. Bir dizi (liste) elemanı saklayan Sekans veri yapısını tasarlayın ve uygulayın. Aşağıdaki işlemleri destekler:
ardındanEkle(e):
Dizide e elemanından sonra yeni bir eleman
ekler. Yeni eklenen elemanı döndürür. (e, null ise, yeni eleman
dizinin başlangıcına eklenir.)
sil(e):
önceGelen(e1, e2):
Diziden e elemanını siler.
Dizide e1 elemanı, e2’den önce geliyorsa,
true döndürür.
İlk iki işlem O(log n) amortize zamanda çalışmalıdır. Üçüncü işlem
sabit zamanda çalışmalıdır.
302|
Sekans
Günah
veri yapısının elemanlarını, dizide oluştukları sırada, bir
Keçisi
önceGelen(e1, e2)
Ağacı’nda
saklayarak
uygulayabilirsiniz.
işlemini sabit zamanda gerçekleştirmek için,
her e elemanı kökten başlayıp e’ye giden yolu şifreleyen bir tamsayıyla etiketlenir. Bu şekilde, önceGelen(e1, e2), e1 ve e2 etiketlerini karşılaştırarak sonuç döndürür.
| 303
304|
Bölüm 9
Kırmızı-Siyah Ağaçlar
Bu bölümde, İkili Arama Ağacı’nın logaritmik yükseklikli bir versiyonu olan Kırmızı-Siyah Ağacı tanıtıyoruz. Kırmızı-Siyah Ağacı,
en yaygın kullanılan veri yapılarından biridir. Java Koleksiyonları
Çerçevesi ve C++ Standart Şablon Kütüphanesi’nin çeşitli uygulamaları da dahil olmak üzere, pek çok kütüphane uygulamasında
birincil arama yapısı olarak görünür. Linux işletim sistemi çekirdeği içinde de kullanılmaktadır. Kırmızı-Siyah Ağaç’larının popüler
olmasının çeşitli nedenleri vardır:
1. n değer depolayan bir Kırmızı-Siyah Ağacı, en fazla
n
2log
yüksekliğe sahiptir.
2. ekle(x) ve sil(x) işlemleri, Kırmızı-Siyah Ağacı üzerinde
O(log n) en kötü zamanda çalışır.
3. ekle(x) ve sil(x) işlemleri sırasında amortize sabit sayıda
döndürüş gerçekleştirilir.
Bu özelliklerin ilk ikisi, Kırmızı-Siyah Ağacı’nı zaten Sekme Listeleri, Treap
ve Günah Keçisi Ağacı’nın bir adım önüne koymaktadır.
Sekme Listeleri
ve Treap, rasgeleliğe dayanır ve O(log n) sadece
beklenen çalışma zamanıdır. Günah Keçisi Ağacı’nın yükseklik
| 305
sınırı garantilidir, ancak ekle(x) ve sil(x) işlemleri, sadece O(log n)
amortize zamanda çalışır. Üçüncü özellik, x elemanını eklemek
veya silmek için gerekli zamanın, x’i bulmak için gerekli zaman
tarafından gölgede bırakıldığını bize anlatıyor.
Ancak Kırmızı-Siyah Ağaç’ların iyi özelliklerinin bir bedeli vardır:
uygulama karmaşıklığı. Yüksekliğin 2log n ile sınırlanması kolay
değildir. Birkaç durumun dikkatli analizini gerektirir. Uygulama,
her durumda tam olarak doğru şeyi yapmalıdır. Yanlış bir döndürüş
veya renk değişikliği, anlaşılması ve izlenmesi çok zor bir hata üretir.
Kırmızı-Siyah Ağaç’ların
uygulamasına doğrudan atlamadan önce,
nasıl keşfedildiklerine ve neden verimli bakıldıklarına dair kavrayış
ve anlayış sağlayacak bir veri yapısı hakkında bilgi vereceğiz: 2-4
Ağaçları.
306|
2-4 Ağaçları
2-4 Ağacı
aşağıdaki özelliklere sahip köklü bir ağaçtır:
Özellik 9.1 (yükseklik). Bütün yapraklar aynı derinliğe sahiptir.
Özellik 9.2 (derece). Her iç düğümün çocuk sayısı 2, 3 veya 4’tür.
Şekil 9.1, 2-4 Ağacı’na bir örnek göstermektedir. 2-4 Ağacı’nın
özellikleri, yüksekliğin, yaprak sayısı ile logaritmik olarak bağıntılı
olduğunu anlatır:
Önerme 9.1. n yapraklı 2-4 Ağacı en fazla log n yüksekliğe sahiptir.
Kanıt. İç düğüm üzerindeki en az 2 çocuk alt sınırı, h yükseklikli
bir 2-4 Ağacı’nın en az 2h yaprağa sahip olması anlamına gelir. Bir
başka deyişle,
Her iki tarafın logaritmasını alarak h ≤ log n elde ederiz.
| 307
Yaprak eklenmesi
2-4 Ağacı’na
yaprak eklemek kolaydır (bkz. Şekil 9.2). Sondan bir
önceki seviyede bulunan w düğümünün çocuğu olarak u yaprağını
eklemek isterseniz, u’yu direkt olarak w’nin çocuğu yaparız. Yükseklik özelliği kesinlikle korunur, ancak derece özelliği bozulabilir;
çünkü u eklenmeden önce w’nin 4 çocuğu varsa, şimdi 5 çocuğu
olacaktır. Bu durumda, w, sırasıyla iki ve üç çocuğa sahip olan w
ve w’ düğümleri olarak iki düğüm halinde ikiye bölünür. Ancak
şimdi w’ düğümünün babası yoktur, bu yüzden özyinelemeli olarak
w’nin
babasının çocuğu olarak w’ yapılır. Böylece yine, w’nin ba-
bası çok fazla çocuğa sahip olabilir, bu durumda bölünmelidir. Dört
çocuktan daha az olan bir düğüme ulaşana kadar bu süreç devam
eder veya kök r, iki düğüm halinde, r ve r’, olarak bölünür. Sonraki
durumda, çocukları r ve r’ olan yeni bir kök oluştururuz. Her yaprağın derinliği böylece artar ve yükseklik özelliği korunur.
2-4 Ağacı’nın
yüksekliği log n’den daha fazla olmayacağı için,
yaprak ekleme süreci en fazla log n adım alır.
308|
| 309
Yaprak silinmesi
2-4 Ağacı’ndan
u’nun
yaprak silmek biraz daha zordur (bkz. Şekil 9.3).
babası olan w’den silmek için, u’yu sadece sileriz. u silin-
meden önce, w sadece iki çocuğa sahipse, o zaman w bir çocukla
kalır, ve derece özelliği bozulur.
Bunu düzeltmek için, w’nin kardeşi olan w’ düğümüne bakılır. w’
düğümü ağaçta mutlaka bulunmalıdır, çünkü silme işleminden önce, w’ babası en az iki çocuğa sahipti. w’ üç veya dört çocuğa sahip
ise, bu çocuklardan birini w’ düğümünden alırız ve w’ye veririz.
Şimdi w’nin iki çocuğu vardır, ve w' düğümünün iki veya üç çocuğu vardır; işlem tamamlanır.
Öte yandan, eğer w’ yalnızca iki çocuk sahibiyse, w ve w’ düğümlerini üç çocuklu tek bir w düğüm halinde birleştiririz. Ardından,
özyinelemeli olarak, w’ babasından w’ düğümünü sileriz. Bu süreç
kendisinin veya kardeşinin ikiden fazla çocuğu olması durumunu
sağlayan bir u düğümüne, veya köke ulaşıldığında sona erer. Sonraki durumda, kök sadece bir çocuk ile kalmışsa, kökü sileriz, ve
çocuğunu yeni kök yaparız. Yine, her yaprağın yüksekliği azalır, ve
böylece yükseklik özelliği korunur.
310|
Yine, ağacın yüksekliği en fazla log n olacağı için, yaprak silme
işlemi en fazla log n adımdan sonra tamamlanır.
| 311
Kırmızı-Siyah Ağacı: 2-4 Ağacının
Benzeri
Kırmızı-Siyah Ağaç,
her, u düğümü kırmızı veya siyah renk alan
İkili Arama Ağacı’dır.
Kırmızı renk 0 ile, ve siyah renk 1 ile temsil
edilir.
Kırmızı-siyah ağaç üzerinde gerçekleştirilen herhangi bir işlem
öncesi ve sonrasında, aşağıdaki iki özellik sağlanmalıdır. Her özellik, 0 ve 1 sayısal değerlerini alan, kırmızı ve siyah renk cinsinden
tanımlanır.
Özellik 9.3 (siyah-yükseklik). Kökten yaprağa giden her yol üzerindeki siyah düğüm sayısı aynıdır. (Kökten yaprağa giden her yol
üzerindeki renk toplamı aynıdır.)
Özellik 9.4 (komşu-olmayan-kırmızı-kenar). İki kırmızı düğüm
bitişik olamaz. (Kök dışında, herhangi,
u.colour + u.parent.colour ≥ 1
u,
düğümü için,
olur.)
Unutmayın ki, bu iki özellikten hiçbirini bozmadan, Kırmızı-Siyah
Ağacı’nın, r,
kökünü renklendirebiliriz, kökün siyah renkte olduğu-
312|
nu ve ağacı güncelleyen algoritmaların bunu koruduğunu varsayacağız. Kırmızı-Siyah Ağacı’nı kolaylaştıran bir başka fikir de, (nil
ile gösterilen) dış düğümleri siyah düğüm olarak değerlendirmektir.
Bu şekilde, Kırmızı-Siyah Ağacı’nın her gerçek, u düğümü, renkleri
iyi tanımlanmış olan tam olarak iki çocuğa sahip olur. Şekil 9.4
Kırmızı-Siyah Ağacı’na bir
örnek gösteriyor.
| 313
Kırmızı-Siyah Ağacı ve 2-4 Ağacı
İlk bakışta, Kırmızı-Siyah Ağacı’n siyah-yükseklik ve komşuolmayan-kırmızı-kenar özelliklerini sağlayacak şekilde verimli olarak güncellenebilir olması şaşırtıcı görünebilir. Oysa ki, kırmızısiyah ağaçlar birer ikili ağaç olan 2-4 ağaçlarının verimli bir
simulasyonu olarak tasarlanmıştı.
Şekil 9.5’e bakarak, n düğümlü herhangi bir kırmızı-siyah ağacı,
T’yi
ele alın, ve aşağıdaki dönüşümü gerçekleştirin: Her u kırmızı
düğümünü silin, ve u’nun iki çocuğunu u’nun (siyah) babasına direkt olarak bağlayın. Bu dönüşüm sonrasında sadece siyah düğümlere sahip olan bir T' ağacıyla başbaşa kalırız.
T'
ağacının her iç düğümü, iki, üç veya dört çocuğa sahiptir: İki
siyah çocuk ile başlayan siyah bir düğüm, bu dönüşümden sonra
da, iki siyah çocuk sahibi olacaktır. Bir kırmızı ve bir siyah çocuk
314|
ile başlayan siyah bir düğüm, bu dönüşüm sonrasında, üç çocuk
sahibi olacaktır. İki kırmızı çocuk ile başlayan siyah bir düğüm, bu
dönüşümden sonra dört çocuk sahibi olacaktır. Ayrıca, siyahyükseklik özelliği, kökten-yaprağa giden her yolun T' içinde aynı
uzunlukta olmasını garanti eder. Diğer bir deyişle, T', 2-4 ağacıdır!
2-4 ağacı olan T', n + 1 yaprağa sahiptir. Bu nedenle, bu ağacın
yüksekliği en fazla log(n + 1) olur. Şu anda, 2-4 ağaçta, kökten
yaprağa giden her yol, kırmızı-siyah ağaçta, kökten bir dış düğüme
giden bir yola karşılık gelir. Bu yolun ilk ve son düğümü siyahtır,
ve her iki iç düğümden en çok biri kırmızıdır, böylece bu yolun en
fazla log(n + 1) siyah düğümü ve en fazla log(n + 1) – 1 kırmızı
düğümü bulunmaktadır. Bu nedenle, T içinde, kökten T’nin bir iç
düğümüne giden yol en fazla,
uzunluğa sahipir (herhangi bir n ≥ 1 için). Bu, Kırmızı-Siyah
Ağaç’ların
en önemli özelliğini kanıtlar:
Önerme 9.2. n düğümlü kırmızı-siyah ağacın yüksekliği en fazla
2log n
olur.
| 315
2-4 Ağaç
ve Kırmızı-Siyah Ağaç’lar arasındaki ilişkiyi anladığımız
için, eleman ekleme ve silme sırasında, kırmızı-siyah ağacın bakımını verimli şekilde sağlamak konusunda zorluk yaşanmayacaktır.
İkili Arama Ağacı’na
eleman eklemenin, yeni bir yaprak ekleyerek
yapılabildiğini daha önce görmüştük. Bu nedenle, Kırmızı-Siyah
Ağaç
üzerinde ekle(x) işlemini uygulamak için, 2-4 Ağacı’nın beş
çocuklu bir düğümünü ayırarak bölmeliyiz.
316|
2-4 Ağacı’nın
beş çocuklu bir düğümü, iki kırmızı çocuğu olan
siyah bir düğüm tarafından temsil edilir, bu iki kırmızı çocuktan
birinin çocuğu da kırmızıdır. Bu halde, siyah düğümü kırmızı ile
renklendirerek, ve iki çocuğu da siyah ile renklendirerek bu düğümü “ikiye böleriz”. Şekil 9.6 örnek bir uygulamayı gösteriyor.
| 317
Benzer şekilde, sil(x) uygulaması, iki düğümü birleştiren ve kardeşten bir çocuk borçlanan bir işlemi gerektirir. İki düğümü birleştirmek, onları ortadan bölmenin (Şekil 9.6’da gösterilmiştir) zıt işlemidir, ve iki (siyah) kardeşin kırmızı ile renklendirilmesini, ve
(kırmızı) babasının siyah ile renklendirilmesini içerir. Bir kardeşten
borçlanma en zor işlemdir ve döndürüşler ile yeniden renklendirmeyi gerektirir.
Tabii ki, tüm bunlar boyunca siyah-yükseklik ve komşu-olmayankırmızı- kenar özelliğini korumamız gerekiyor. Bunun yapılabilir
olması artık şaşırtıcı olmasa da, özellikle Kırmızı-Siyah Ağacı’nı bir
2-4 Ağacı’na
benzetirseniz, dikkate alınması gereken çok sayıda
durum vardır. Bir noktada, 2-4 Ağacı’nı yalnızca göz ardı etmeniz,
ve Kırmızı-Siyah Ağacı’nın özelliklerini sağlamaya çalışmanız daha
kolay olacaktır.
318|
Kırmızı-Siyah Ağacında Sola-Dayanım
Kırmızı-Siyah Ağacı’nın
le(x)
tek bir tanımı yoktur. Daha doğrusu, ek-
ve sil(x) işlemleri sırasında siyah-yükseklik ve komşu-
olmayan-kırmızı-kenar özelliklerini koruyan ve yöneten birtakım
yapılar vardır. Farklı yapılar bunu farklı şekillerde yaparlar. Burada, Kırmızı-Siyah Ağaç adı altında bir veri yapısını uyguluyoruz.
Bu yapı, ek bir özelliği de sağlayan, kırmızı-siyah ağacın belirli bir
varyasyonunu uygulamaktadır:
Özellik 9.5 (sola-dayanım). Herhangi bir, u düğümünde, u.left
siyah ise, u.right siyahtır.
Fark edebilirsiniz ki, Şekil 9.4’de gösterilen Kırmızı-Siyah Ağaç
sola-dayanım özelliğini sağlamıyor; bu özellik en sağdaki yol üzerindeki kırmızı düğümün babası tarafından bozulmuştur.
Sola-dayanım özelliğini sağlamamızın nedeni, ekle(x) ve sil(x)
işlemleri sırasında, ağacı güncellerken oluşabilecek durum sayısını
azaltmaktır. 2-4 Ağacı açısından bu, her 2-4 Ağacı’nın tekil ve
benzersiz gösterilmesi anlamına gelir: Bir düğüm, iki derecesindeyse, iki siyah çocuklu bir siyah düğüm haline gelir. Bir düğüm, üç
derecesindeyse, sol çocuğu kırmızı ve sağ çocuğu siyah olan siyah
bir düğüm haline gelir. Bir düğüm, dört derecesindeyse, iki kırmızı
çocuklu siyah bir düğüm haline gelir.
| 319
ekle(x)
ve sil(x) uygulamasını ayrıntılı olarak anlatmadan önce, bu
yöntemler tarafından kullanılan ve Şekil 9.7’de gösterilen bazı basit
altprogramları sunacağız. İlk iki altprogram renkleri değiştirmek
için kullanılırken, siyah-yükseklik özelliğini korur. pushBlack(u)
işlemi, iki kırmızı çocuğu olan siyah bir u düğümünü girdi olarak
alır, ve kendisini kırmızı ile, çocuklarını siyah ile renklendirir.
pullBlack(u)
işlemi, bu işlemi tersine çevirir:
solaÇevir(u)
yöntemi, u ve u.right düğümlerinin renklerini değişti-
rir, ve sonra u düğümünde sola döndürüş gerçekleştirir. Bu işlem,
320|
bu iki düğümün renklerini değiştirmesinin yanı sıra, baba-çocuk
ilişkisini de tersine çevirir:
solaÇevir(u)
işleminin yararı, sola-dayanım özelliğini bozan u dü-
ğümündeki (u.left siyah ve u.right kırmızı olduğu için) soladayanımı, tekrar geri kazandırmasıdır. Bu özel durumda, bu işlemin
hem siyah-yükseklik ve hem de komşu-olmayan-kırmızı-kenar
özelliğini koruyacağından emin olabiliriz. sağaÇevir(u) işlemi,
solaÇevir(u)
ğişmiştir.
işlemi ile simetriktir, sağ ve sol roller sadece yer de-
| 321
Ekleme
Kırmızı-Siyah
u.x = x,
Ağaç
üzerinde ekle(x) yöntemini uygularken,
ve u.colour = red olacak şekilde yeni bir u yaprağı ekle-
mek için, standart İkili-Arama Ağacı eklemesi yaparız. Unutmayın
ki bu, hiçbir düğümün siyah yüksekliğini değiştirmez, böylece siyah-yükseklik özelliği bozulmaz. Ancak, sola-dayanım özelliği (u,
babasının sağ çocuğu ise) ve komşu-olmayan-kırmızı-kenar özelliği
bozulabilir (u’nun babası kırmızı ise). Bu özellikleri geri kazanmak
için, ekleTamiri(u) yöntemini çalıştırırız.
Şekil 9.8’de gösterilen, ekleTamiri(u) yöntemi, girdi olarak rengi
kırmızı olan ve komşu-olmayan-kırmızı-kenar özelliğini ve/veya
sola-dayanım özelliğini bozabilecek u düğümünü alır. Bu işlem ile
ilgili tartışmayı takip edebilmeniz için, Şekil 9.8’e başvurmanız
veya bir parça kağıt üzerinde canlandırmalar yapmanız gerekmektedir. Nitekim, okuyucu devam etmeden önce, bu şekilleri incelemek isteyecektir.
322|
u
ağacın kökü ise, her iki özelliği de sağlaması için rengini siyah
olarak belirleyebiliriz. Aynı zamanda, u’nun kardeşi kırmızı ise,
u’nun
babası siyah olmalıdır, bu nedenle sola-dayanım ve komşu-
olmayan-kırmızı-kenar özelliklerinin her ikisi de zaten sağlanır.
Aksi takdirde, ilk olarak u’nun babası, w’nin, sola-dayanım özelliğini bozup bozmadığını belirleriz ve eğer öyleyse, solaÇevir(u)
işlemi çalıştırılır ve u = w olarak belirlenir. Bu bizi iyi tanımlanmış
bir duruma götürür: u, babası olan w’nin sol çocuğudur, böylece
şimdi, w sola-dayanım özelliğini sağlar. Geriye, komşu-olmayan-
| 323
kırmızı-kenar özelliğini sağlamak kalıyor. Sadece, w’nin kırmızı
olduğu durum hakkında endişelenmeliyiz, çünkü u komşuolmayan-kırmızı-kenar özelliğini aksi takdirde zaten sağlamaktadır.
Henüz işimizi bitirmediğimiz için, u kırmızı ve w kırmızı olarak
kalmıştır. Komşu-olmayan-kırmızı-kenar özelliği, u’nun büyükannesi g’nin var olduğunu ve onun siyah olduğunu öngörmektedir.
g’nin
sağ çocuğu kırmızı ise, o zaman sola-dayanım özelliği g’nin
her iki çocuğunun da kırmızı olduğunu garanti eder, ve
pushBlack(g)
için yapılan bir çağrı, g’yi kırmızı ve w’yi siyah ya-
par. Böylece komşu-olmayan-kırmızı-kenar özelliği, u düğümünde
yeniden kazanılır, ancak g düğümünde bu özellik bozulabileceği
için, sürecin tamamı u = g için yeniden başlatılır.
g’nin
sağ çocuğu siyah ise, sağaÇevir(g) için yapılan bir çağrı w
düğümünü g’nin (siyah) babası yapar, w’nin iki kırmızı çocuğu
oluşur: u ve g. Böylece u’nun komşu-olmayan-kırmızı-kenar özelliğini sağlaması ve g’nin sola-dayanım özelliğini sağlaması garanti
altına alınır. Bu durumda, hiçbir şey yapmayız.
324|
ekleTamiri(u)
yöntemi işlem başına sabit zamanda çalışır, ve her
bir yineleme ya işlemi sonlandırır, veya u pozisyonunu köke doğru
yakına taşır. Bu nedenle, ekleTamiri(u) işlemi O(log n) döngüden
sonra O(log n) zamanda çalışmasını sona erdirir.
| 325
Silme
Kırmızı-Siyah Ağaç
üzerinde sil(x) uygulaması en karmaşık işlem-
dir, ve bilinen tüm kırmızı-siyah ağaç varyasyonları için bu böyledir. İkili Arama Ağacı’ndaki sil(x) işleminde olduğu gibi, sadece u
çocuklu, bir w düğümünü buluruz ve, w.parent = u belirlemesiyle
w’yi
ağaçtan ayırırız.
Buradaki problem, w siyah ise, siyah-yükseklik koşulu, w.parent
düğümünde
u.colour
bozulmuştur.
Bu
sorunu
geçici
olarak,
+= w.colour belirlemesiyle, önleyebiliriz. Tabii ki, bu iki
diğer problemi beraberinde getirir:
1.
u
ve w siyah ile başlamışsa, u.colour + w.colour = 2 (iki-kat-
siyah), geçersiz renk olarak belirlenir.
2.
w
kırmızı ise, siyah u düğümü tarafından yer değiştirilir, ki bu
da u.parent düğümünde sola-dayanım özelliğini bozar.
Her iki problem de silTamiri(u) işlemine yapılan bir çağrı ile çözülebilir.
silTamiri(u)
yöntemi girdi olarak rengi (1) siyah ve (2) iki-kat-
siyah olan bir u düğümü alır. u iki-kat-siyah ise, silTamiri(u), ikikat-siyah düğüm ağaç seviyelerinde yukarı çıkarılarak yok edilene
kadar bir dizi döndürüş ve yeniden renklendirme gerçekleştirir. Bu
işlem sırasında, u düğümü, süreç sonunda, değiştirilen altağacın
326|
köküne ait oluncaya kadar değişir. Bu altağacın kökü renk değiştirmiş olabilir. Özellikle, kırmızıdan siyaha geçmiş olabilir, böylece
silTamiri(u)
işlemi, u’nun babasının sola-dayanım özelliğini bozup
bozmadığını kontrol ederek bitirir, ve eğer bozuyorsa, düzeltir.
silTamiri(u)
yöntemi Şekil 9.9’da gösterilmiştir. Şekil 9.9’a baş-
vurmaksızın, aşağıdaki metni takip etmeniz imkansız olmasa da,
çok zor olacaktır.
| 327
silTamiri(u)
yöntemindeki döngü, aşağıdaki durumlardan birine
bağlı kalarak, iki-kat-siyah düğümleri işlemektedir:
Durum 0: u köktür. İşlemesi en kolay durum budur. u siyah olarak
yeniden renklendirilir (Kırmızı-siyah ağaç özelliklerinin hiçbiri
bozulmaz).
Durum 1: u’nun kardeşi olan v kırmızı renktedir. Bu durumda,
u’nun kardeşi,
babası olan w’nin sol çocuğudur (sola-dayanım özel-
liği nedeniyle). w düğümünde sağa çevirme yaparız ve döngüye
devam ederiz. Unutmayın ki, bu eylem sonucunda w’in babası soladayanım özelliğini bozar, ve u’nun derinliği artmıştır. Ancak, bir
sonraki döngünün w kırmızı iken Durum 3 için işletileceği anlamına da gelir. Aşağıdaki 3.durumu incelediğinizde, bir sonraki döngüde sürecin sona ereceğini görebilirsiniz.
328|
Durum 2: u’nun kardeşi olan v siyahtır. u, babası olan w’nin sol
çocuğudur. Bu durumda pullBlack(w) için bir çağrı yaparak u siyah, v kırmızı, w siyah veya iki-kat-siyah renk alır. Bu noktada, w
sola-dayanım özelliğini bozacağı için, solaÇevir(w) için yapılan bir
çağrıyla bunu düzeltiriz.
Bu andan itibaren, w kırmızı, v başladığımız altağacın köküdür.
w’nin
komşu-olmayan-kırmızı-kenar özelliğini bozup bozmadığını
kontrol etmeliyiz. Bunu yapmak için, w’nin sağ çocuğu olan q’yi
incelememiz gerekir. Eğer q siyah ise, w komşu-olmayan-kırmızıkenar özelliğini sağlar, ve bir sonraki döngüye u = v belirlemesiyle
devam ederiz.
Aksi takdirde, (q kırmızı iken), w, ve q düğümlerinde, sırasıyla,
sola-dayanım ve komşu-olmayan-kırmızı-kenar özellikleri bozulmuştur. Sola-dayanım özelliğini, solaÇevir(w) için bir çağrı yaparak düzeltiriz, ancak, komşu-olmayan-kırmızı-kenar özelliği halen
bozulmuştur. Bu noktada, q, v’nin sol çocuğudur, w, q’nin sol çocuğudur, q ve w her ikisi de kırmızıdır, v siyah veya iki-katsiyahtır. sağaÇevir(q) için yapılan bir çağrı ile q düğümü, hem v,
hem w düğümlerinin babası olur. Bunu izleyen bir pushBlack(q)
çağrısı, hem v, hem w düğümlerini siyah hale getirir, ve, q’nun
rengini w’nin, orijinal rengi olarak belirler.
| 329
Bu andan itibaren, iki-kat-siyah düğüm ortadan kaldırılmış, ve
komşu-olmayan-kırmızı-kenar ve siyah-yükseklik özellikleri geri
kazandırılmıştır. Sadece olası bir sorun vardır: v’nin sağ çocuğu
kırmızı olabilir, ve sola-dayanım özelliği bozulur. Bu durumu kontrol eder, ve gerekiyorsa, solaÇevir(v) için yapılan bir çağrı ile özelliği geri kazandırırız.
330|
Durum 3: u’nun kardeşi siyahtır. u, babası olan w’nin sağ çocuğudur. Bu durum, 2.Durum ile simetrik olduğu için benzer şekilde
işlenir. Tek fark, sola-dayanım özelliğinin asimetrik olması nedeniyle farklı işlem gerektirmesidir.
| 331
Önceki gibi, pullBlack(w) için yapılan bir çağrı ile başlarız ve bunun sonucunda, v kırmızı, u siyah olur. sağaÇevir(w) için yapılan
bir çağrı sonucunda, v, altağacın kökü haline gelir. Bu noktada, w
kırmızıdır, w’nin sol çocuğu olan q’nun rengine göre kod iki dala
ayrışır.
q
kırmızı ise, kod 2.Durum’da olduğunun aynısı gibi ve hatta daha
basit şekilde işler; v düğümünde sola-dayanım özelliğinin bozulması tehlikesi yoktur.
332|
q
siyah ise, durum daha karmaşıktır. Bu durumda, v’nin sol çocu-
ğunun rengini kontrol ederiz. Kırmızı ise, v iki kırmızı çocuk sahibidir ve iki-kat-siyah olan v düğümü, pushBlack(v) çağrısı ile aşağı
itilir. Bu noktada, v, w’nin orijinal rengine bürünür, işlem tamamlanır.
v’nin
sol çocuğu siyah ise, v sola-dayanım özelliğini bozar.
solaÇevir(v)
için yapılan bir çağrı ile bu özellik geri kazandırılır.
Bir sonraki silTamiri(u) döngüsünü, u = v için çalıştırmak üzere, v
düğümünü döndürürüz.
| 333
silTamiri(u)
işleminin her döngüsü sabit zamanda çalışır. Durum 2
ve 3, ya sonlanır, ya da u’yu ağaçta köke daha yakın yere taşır. Durum 0, (u kök olduğu için) her zaman sonlanır. Durum 1, Durum 3
haline gelerek hemen sonlanır. Ağacın yüksekliği en az 2log n olduğu için, silTamiri(u) işleminin en çok O (log n) döngü çalıştırdığı sonucuna varabilirsiniz, böylece silTamiri(u), O(log n) zamanda
çalışır.
334|
Özet
Aşağıdaki teorem Kırmızı-Siyah Ağaç veri yapısının performansını
özetlemektedir:
Teorem 9.1. Kırmızı-Siyah Ağaç, Sıralı Küme arayüzünü uygular.
Kırmızı-Siyah Ağaç, işlem başına O(log n) en-kötü zamanda çalışan, ekle(x), sil(x) ve bul(x) işlemlerini destekler.
Aşağıda ekstra bir teorem daha verilmektedir:
Teorem 9.2. Başlangıçta, Kırmızı-Siyah Ağaç elemanları boş değer taşırken, ekle(x) ve sil(x) için yapılan m çağrı sırasında,
ekleTamiri(u) ve silTamiri(u)
çağrıları O(m) toplam zamanda ça-
lışır.
Sadece Teorem 9.2’ın kanıtını açıklayacağız. ekleTamiri(u) ve
silTamiri(u)
algoritmalarını, 2-4 Ağacı’na yaprak ekleyen veya
silen algoritmalar ile karşılaştırarak, bu özelliğin 2-4 Ağacı’ndan
devralındığına kendimizi inandırabiliriz. Özellikle, 2-4 Ağacı’nı
ayırmak, birleştirmek ve ödünç almak işlemlerinin O(m) toplam
zamanda çalıştığını gösterebilirsek, o zaman bu Teorem 9.2 anlamına gelir.
| 335
2-4 Ağacı
için bu teoremin kanıtı, amortize analizin potansiyel
metotunu kullanır. 2-4 Ağacı’nın iç düğümü olan u’nun potansiyeli,
ve 2-4 Ağacı’nın potansiyeli, düğümlerin potansiyellerinin toplamı
olarak tanımlansın. Bölünme oluştuğunda, dört çocuklu bir düğüm,
iki ve üç çocuklu, ikişer düğüm haline gelir. Bunun anlamı, toplam
potansiyel 3 – 1 – 2 = 2 kadar azalır. Birleştirme oluştuğunda, iki
çocuğu olan iki düğüm, üç çocuklu bir düğüm ile yer değiştirir.
Bunun anlamı, toplam potansiyel 2 – 0 = 2 kadar azalır. Bu nedenle, her bölünme veya birleştirme sonrasında potansiyel 2 azalır.
Ardından, fark edebilirsiniz ki, düğümleri bölmeyi ve birleştirmeyi
görmezden gelirseniz, sabit sayıdaki düğümlerin çocuk sayısı, bir
yaprağın eklenmesi veya çıkarılması ile değişmektedir. Bir düğümü
eklerken, bir düğümün çocuk sayısı 1 artar, bu da potansiyeli en
fazla 3 artırır. Bir yaprağın silinmesi sırasında, bir düğümün çocuk
sayısı 1 azalır, bu da potansiyeli en fazla 1 artırır, ve iki düğüm
toplam borçlanma işlemine dahil edilebilir, bunun sonucunda toplam potansiyelleri en fazla 1 artar.
Özetlemek gerekirse, her birleştirme ve bölme potansiyeli en az 2
azaltır. Birleştirme ve bölme önemsenmediği takdirde, her ekleme
336|
veya silme, potansiyelin en fazla 3 artmasına neden olur, ve potansiyel her zaman pozitiftir. Bu nedenle, başlangıçta boş bir ağaç üzerinde yapılan m ekleme veya silmenin neden olduğu bölme ve birleştirmelerin sayısı, en fazla 3m / 2 olur. Teorem 9.2, bu analizin
ve 2-4 Ağacı ile Kırmızı-Siyah Ağacı arasındaki benzeşmenin bir
sonucudur.
| 337
Tartışma ve Alıştırmalar
Kırmızı-Siyah Ağacı
ilk olarak Guibas ve Sedgewick [38] tarafın-
dan tanıtıldı. Uygulaması karmaşık olmasına rağmen, en sık kullanılan kütüphane ve uygulamalar arasındadır. Algoritma ve veri yapıları üzerine çoğu ders kitabında, Kırmızı-Siyah Ağaç’ların bazı
varyasyonları tartışılmaktadır.
Andersson [6] dengeli ağaçların sola-dayanımlı bir versiyonunu
açıklıyor. Bu yapı kırmızı-siyah ağaçlara benzer, ancak bir ek kısıtlama olarak, herhangi bir düğümünde en fazla bir adet kırmızı çocuğa yer vardır. Bu demektir ki, bu ağaçlar 2-4 Ağacı gibi değil, 23 Ağacı
gibi davranırlar. Bunlar, bu bölümde tanıtılan Kırmızı-
Siyah Ağaç
yapısından önemli ölçüde daha kolaydır.
Sedgewick [66] Kırmızı-Siyah Ağacı’nın sola-dayanımlı iki versiyonunu açıklıyor. Bunlar, 2-4 Ağacı’nda yukarıdan-aşağıya bölme
ve birleştirme simülasyonu ile birlikte özyineleme kullanır. Bu iki
tekniğin birleşimi özellikle kısa ve zarif kod yapar.
İlgili ve daha eski bir veri yapısı AVL ağacı [3]’dır. AVL
Ağaç’larının
yüksekliği-dengelidir: Her u düğümünde, u.left köken-
li ağacın yüksekliği ile u.right kökenli altağacın yüksekliği en fazla
1
farklıdır. h yükseklikli bir ağacın minimum yaprak sayısı F(h) ile
verildiyse, o zaman F(h), aşağıdaki Fibonacci Yinelemesi’ne uyar:
338|
Başlangıç durumları F(0) = 1 ve F(1) = 1 ile verilmiştir. Bunun
anlamı, altın oran
olarak
eşittir (Daha kesin doğrulukla,
iken F(h) yaklaşık
)
Önerme 9.1’in kanıtında olduğu gibi,
Bu nedenle, AVL Ağaç’ları, Kırmızı-Siyah Ağaç’lardan daha az
yüksekliğe sahiptir. ekle(x) ve sil(x) işlemleri sırasında, yükseklik
dengelemeyi şöyle sağlayabilirsiniz: Köke kadar yukarı yürürken
rastladığınız her u düğümü için, u’nun sol ve sağ altağaçları arasındaki yükseklik farkı 2’den büyük ise, yeniden dengeleyin.
Bkz.Şekil 9.10.
| 339
Kırmızı-Siyah Ağaç’ların
Andersson ve Sedgewick varyasyonları
ile AVL Ağacı, bu bölümde tanımladığımız Kırmızı-Siyah Ağaç yapısını uygulamaktan daha kolaydır. Ne yazık ki, bunların hiçbiri,
yeniden dengelemenin güncelleme başına O (1) zamanda çalışacağını garanti edemez. Özellikle, bu yapılar için Teorem 9.2’nin hiçbir benzeri yoktur.
340|
Alıştırma 9.1. Şekil 9.11’de gösterilen Kırmızı-Siyah Ağacı’na
karşılık gelen 2-4 Ağacı’nı gösterin.
Alıştırma 9.2. Şekil 9.11’de gösterilen Kırmızı-Siyah Ağacı üzerine
13, sonra 3,5 ve sonra 3,3 değerlerini eklemeyi gösterin.
Alıştırma 9.3. Şekil 9.11’de gösterilen Kırmızı-Siyah Ağacı’nın
üzerinden 11, sonra 9 ve sonra 5 değerlerini silmeyi gösterin.
Alıştırma 9.4. Oldukça büyük n değerleri için, 2log n – O(1) yüksekliğinde, n düğümlü Kırmızı-Siyah Ağaç’ların bulunduğunu gösterin.
Alıştırma 9.5. pushBlack(u) ve pullBlack(u) işlemlerini düşünün.
Bu işlemler Kırmızı-Siyah Ağacı’nın simule ettiği temel bir 2-4
ağacı üzerinde neler yapar?
| 341
Alıştırma 9.6. Oldukça büyük n değerleri için, 2log n – O(1) yüksekliğinde, n düğümlü Kırmızı-Siyah Ağaç’lara bizi götürecek olan
bir dizi ekle(x) ve sil(x) işlemlerinin var olduğunu gösterin.
Alıştırma 9.7. Kırmızı-Siyah Ağaç uygulamasında sil(x) yöntemi
neden u.parent = w.parent atamasını gerçekleştirir? Zaten bunun
splice(w)
çağrısı tarafından yapılması gerekmiyor muydu?
Alıştırma 9.8. 2-4 Ağacı olan T’nin, nl yaprağı ve ni iç düğümü
olduğunu düşünün.
1. nl cinsinden bir fonksiyon olarak, ni minimum değeri nedir?
2. nl cinsinden bir fonksiyon olarak, ni maksimum değeri nedir?
3. T kırmızı-siyah ağacını temsil eden bir T’ ağacı kaç tane kırmızı
düğüme sahiptir?
Alıştırma 9.9. Varsayın ki, n düğümlü ve en çok 2log n – 2 yüksekliğe sahip bir İkili Arama Ağacı verilmiştir. Siyah-yükseklik ve
komşu-olmayan-kırmızı-kenar özelliklerini sağlayacak şekilde,
ağacın düğümlerini kırmızı ve siyah olarak her zaman renklendirmek mümkün müdür? Eğer öyleyse, sola-dayanım özelliğini karşılayacak şekilde de yapılabilir mi?
Alıştırma 9.10. Varsayın ki, T1 ve T2 aynı, h, siyah yüksekliğine
sahip iki Kırmızı-Siyah Ağacı olsun, ve T1 üzerinde depolanan en
büyük anahtar değer, T2 üzerinde depolanan en küçük anahtar de-
342|
ğerden daha küçük olsun. T1 ve T2’yi tek bir kırmızı-siyah ağaç
halinde O(h) zamanda nasıl birleştireceğinizi gösterin.
Alıştırma 9.11. Alıştırma 9.10 için hazırladığınız çözümü, farklı
siyah yüksekliğe, h1
h2,
sahip iki Kırmızı-Siyah Ağaç için tekrar
düşünün. Çalışma zamanı O(max(h1, h2)) olmalıdır.
Alıştırma 9.12. ekle(x) işlemi sırasında bir AVL Ağacı en fazla bir
kere yeniden dengeleme işlemi (en fazla iki döndürüş içeren,
bkz.Şekil 9.10) gerçekleştirmelidir. AVL Ağacı’na bir örnek verin
ve bu ağaç üzerinde çalışan sil(x) yöntemi, yeniden dengeleme işlemini log n kere çalıştırsın.
Alıştırma 9.13. AVL Ağaç’larını yukarıda tanımlandığı gibi gerçekleştiren bir AVLAğacı sınıfını uygulayın. Performansını KırmızıSiyah Ağacı’nın
bul(x)
performansı ile karşılaştırın. Hangi uygulama
işlemini daha hızlı çalıştırır?
Alıştırma 9.14. Sekme Listesi Sıralı Küme, Günah Keçisi Ağacı,
Treap,
ve Kırmızı-Siyah Ağacı’nın Sıralı Küme uygulamaları için
bul(x), ekle(x), sil(x)
işlemlerinin performansını göreceli olarak
karşılaştıran bir dizi deney tasarlayın ve gerçekleştirin. Verilerin
rasgele olduğu, halihazırda sıralı olduğu, rasgele sırada silindiği,
sıralı sırada silindiği, vb. birden fazla test senaryosunu dahil ettiğinizden emin olun.
| 343
344|
Bölüm 10
Yığınlar
Bu bölümde, son derece yararlı bir veri yapısı olan Öncelik Kuyruğu’nun
iki uygulamasını tanıtacağız. Bu yapıların her ikisi de, İkili
Ağaç’ın
"düzensiz küme" anlamına gelen, yığın adında özel bir
türüdür. İkili Arama Ağacı, yığına kıyasla son derece düzenli bir
kümedir.
Yığın
uygulamasının birincisi, mükemmel ikili ağacı simule eden
bir dizi kullanır. Bu çok hızlı uygulama, yığın-sıralama adıyla bilinen en hızlı sıralama algoritmalarından birinin temelidir (bkz. Yığın-Sıralama Bölümü). İkinci uygulama, daha esnek ikili ağaçlara
dayanmaktadır. İkinci bir öncelik kuyruğu olan h’in elemanlarını
Öncelik Kuyruğu’nun
içselleştirmesini sağlayan meld(h) işlemini
destekler.
İkili Yığın: Bir Örtülü İkili Ağaç
Öncelik Kuyruğu’nun
birinci uygulaması, dört yüz yıldan daha eski
bir tekniğe dayanır. Eytzinger metotu, ağaç düğümlerini enine-ilk
sırada düzenleyerek mükemmel İkili Ağacı bir dizi olarak göster-
| 345
memize olanak tanır (bkz. İkili Ağaçta Sıralı-Düğüm Ziyaretleri
Bölümü). Bu şekilde, kök, 0. konumda depolanır, kökün sol çocuğu
1.
konumda depolanır, kökün sağ çocuğu 2. konumda, ve kökün
sol çocuğunun sol çocuğu 3. konumda depolanır (bkz.Şekil 10.1).
Yeterince büyük bir ağaca Eytzinger metotunu uygularsanız, bazı
kalıplar ortaya çıkar. i’nci endeksteki düğümün sol alt çocuğu,
left(i) = 2i + 1
konumunda yer alır, ve i’nci endeksteki düğümün
sağ alt çocuğu, right(i) = 2i + 2 konumunda yer alır. i endeksindeki düğümün babası, parent(i) = (i – 1 )/2 konumunda yer alır.
346|
İkili Yığın
cı’nın
elemanları, yığın-sıralı olan mükemmel bir İkili Ağa-
dolaylı gösteriminde bu tekniği kullanır. Herhangi bir i en-
deksinde depolanan değer babası olan parent(i) endeksinde depolanan değerden daha küçük değildir. Buna istisna, başlangıç noktası
olan i = 0, kök değeridir. Buradan, Öncelik Kuyruğu'ndaki en küçük değerin, 0 konumunda (kökte) depolandığını çıkarabiliriz.
n
elemanlı İkili Yığın’ın elemanlarını a dizisinde depolayabiliriz:
ekle(x)
işleminin uygulaması oldukça basittir. Tüm dizi tabanlı
yapılarda olduğu gibi, önce a’nın dolu olup olmadığını kontrol ederiz (a.length = n koşuluyla), ve eğer öyleyse, a büyültülür. Sonra,
x, a[n]
konumuna yerleştirilir, ve n, 1 artırılır. Bu noktada, geriye
yapmamız gereken, yığın özelliğini korumayı sağlamaktır. x, babasından küçük olmayana kadar babası ile yer değiştirerek bunu yapabiliriz (bkz. Şekil 10.2).
Yığından en küçük değeri silen, sil() işleminin uygulaması biraz
daha zordur. Küçük değerin nerede olduğunu biliyoruz (kökte),
ancak onu sildikten sonra yer değiştirmeliyiz, ve yığın özelliğini
korumayı sağlamalıyız.
| 347
Bunu yapmanın en kolay yolu, kökü a[n – 1] değeri ile yer değiştirmek, o değeri silmek, ve n’i 1 azaltmaktır. Ne yazık ki, kökteki
yeni eleman şimdi muhtemelen, en küçük eleman değildir, bu nedenle aşağı yönde ilerlemeliyiz. Bu elemanı iki çocuğu ile karşılaştırarak bunu yaparız. Karşılaştırma sonucunda, eleman her üç elemanın en küçüğü ise, o zaman işlem tamamlanır. Aksi takdirde, iki
çocuğunun en küçüğü ile bu elemanı yer değiştiririz ve devam ederiz.
Diğer dizi-bazlı yapılarda olduğu gibi, yeniden_oluştur(u) çağrıları için harcanan çalışma zamanını önemsemeyeceğiz, çünkü bunlar
Önerme 2.1’deki amortize argümanı kullanarak hesaplanabilir. ekle(x)
ve sil(x) işlemlerinin çalışma zamanı (dolaylı olarak) İkili
Ağacı’nın
yüksekliğine bağlıdır. Neyse ki, bu bir mükemmel ikili
ağaçtır, son seviye haricinde her seviyede olası maksimum düğüm
sayısı depolanır.
348|
Bu nedenle, ağacın yüksekliği h ise, en az 2h düğümü vardır. Başka
bir deyişle,
| 349
350|
Bu denklemin her iki tarafının logaritması alındığı takdirde,
Bu nedenle, ekle(x) ve sil(x) işleminin her ikisi de O(log n) zamanda çalışır.
| 351
352|
Özet
Teorem 10.1. Aşağıdaki teorem İkili Yığın performansını özetlemektedir:
İkili
Yığın,
Öncelik
den_oluştur(u)
Kuyruğu
arayüzünü
uygular.
yeni-
işlemi için yapılan çağrıların maliyeti önemsenme-
diği takdirde, İkili Yığın işlem başına O(log n) zamanda çalışan
ekle(x), sil(x)
ve bul(x) işlemlerini destekler.
Başlangıçta, İkili Yığın elemanları boş değer taşırken, m defa çağrılan ekle(x)
den_oluştur(u)
ve sil(x) işlemleri sırasında yapılan yeniçağrıları O(m) toplam zamanda çalışır.
| 353
Karışık Yığın: Rasgele Karışık Yığın
Bu bölümde, Öncelik Kuyruğu uygulamasının altında yatan temel
yapı olarak yığın-sıralı bir İkili Ağacı’nın kullanıldığı Karışık Yığın’ı
tanıtacağız. Ancak, İkili Yığın’ın altında yatan ağaç yapısı ta-
mamen eleman sayısı ile tanımlandığı halde, Karışık Yığın’ın şekli
üzerinde, ne olursa olsun, hiçbir kısıtlama yoktur.
Karışık Yığın
üzerinde ekle(x) ve sil() işlemleri, merge(h1, h2)
işlemi cinsinden uygulanır. Bu işlem h1, h2 yığın düğümlerini alır,
onları birleştirir, yığının kökü olan düğümü döndürür. Yığın kökü
h1
kökenli altağacın tüm elemanlarını ve h2 kökenli altağacın tüm
elemanlarını içerir.
merge(h1, h2)
işleminin iyi yanı, özyinelemeli olarak tanımlana-
bilmesidir (bkz. Şekil 10.4). h1 veya h2’den biri nil ise, boş küme
ile birleştiririz, bu nedenle, h2 veya h1’den birini, sırasıyla, döndürürüz. Aksi takdirde, varsayalım ki, h1.x
eğer, h1.x
h2.x
h2.x
olsun. Çünkü
ise, h1 ve h2’nin rollerini değiştirebiliriz. O za-
man biliyoruz ki, birleştirilmiş yığının kökü h1.x içerecektir ve
h2’yi
özyinelemeli olarak h1.left veya h1.right ile birleştirebiliriz.
h2’yi
birleştirmek için h1.left mi, h1.right mı sorusunun cevabına
karar vermek için rasgelelik kullanılır ve yazı tura atılır.
354|
Bir sonraki bölümde, merge(h1, h2) işleminin O(log n) beklenen
zamanında çalıştığını göstereceğiz. h1 ve h2 içindeki toplam eleman sayısını n ile gösteriyoruz.
merge(h1, h2)
işleminden faydalandığımız takdirde, ekle(x) işle-
mini uygulamak kolaydır. x değerini içeren yeni bir u düğümünü
oluştururuz, ve u’yu yığının kökü ile birleştiririz:
Bu işlem O(log n) = O(log(n+1)) beklenen zamanda çalışır.
| 355
sil()
işleminin uygulaması benzer şekilde kolaydır. Silmek istedi-
ğimiz düğüm köktür, bu nedenle kökün iki çocuğunu birleştiririz ve
sonucu kök yaparız.
Yine bu, O(log n) beklenen zamanda çalışır.
356|
Buna ek olarak, Karışık Yığın, O(log n) beklenen zamanda çalışan
başka birçok işlemi de uygulayabilir. Bunlar arasında:
sil(u) : u düğümünü (ve u.x anahtarını da) yığından siler.
em(h) : Karışık Yığın, h, içindeki tüm elemanları bu yığına ekler, bu süreçte h yığınını boşaltır.
merge(h1, h2)
işlemi için sabit sayıda çağrı yaparak, bu işlemlerin
her biri O(log n) beklenen toplam zamanda gerçekleştirilebilir.
| 357
merge(h1, h2) Analizi
merge(h1, h2)
analizi, İkili Ağaç üzerinde rasgele yürüyüş analizi-
ne dayanmaktadır. İkili Ağaç rasgele yürüyüşü ağacın kökünden
başlar. Rasgele yürüyüşün her adımında yazı tura atılır ve sonucuna
bakarak, bulunduğumuz düğümün sol veya sağ çocuğuna doğru
ilerleriz. Ağacın sonuna geldiğimizde (bulunduğumuz düğüm nil
olduğunda) yürüyüş sona erer.
Aşağıdaki önerme önemlidir, çünkü İkili Ağacı’nın şekline tümden
bağlı değildir.
Önerme 10.1. n düğümlü bir İkili Ağacı’nda rasgele yürüyüşün
beklenen uzunluğu en fazla log(n + 1) olur.
Kanıt. n üzerinden tümevarım yöntemiyle kanıtlanacak. Taban
durumunda, n = 0 iken, yürüyüş 0 = log n + 1 uzunluktadır. Sonucun negatif olmayan tüm tamsayılar n’ < n için doğru olduğunu
varsayalım.
n1,
kökün sol altağacının büyüklüğünü göstersin, böylece
n2 = n – n1 – 1
kökün sağ altağacın boyutudur. Kökten başlaya-
rak, yürüyüş bir adım atar, sonra n1 veya n2 boyutlarında olan
altağaç üzerinden devam eder. Tümevarım hipotezimiz ile yürüyüşün beklenen uzunluğu,
358|
olur,
Çünkü n1 ve n2, her ikisi n’den küçüktür. Log içbükey bir fonksiyon olduğu için, n1 = n2 = (n – 1) / 2 olduğunda, E[W] maksimize olur. Bu nedenle, rasgele yürüyüşün aldığı adımların beklenen
sayısı,
olur.
Konu dışında kalsa da, bilgi teorisi konusunda az bilgi sahibi olan
okuyucular için Önerme 10.1’in kanıtı entropi cinsinden de yapılabilir.
Önerme 10.1 için Bilgi Teorik Kanıt. i 'nci dış düğümün derinliği
di ile gösterilsin. n düğümlü ikili ağacın n + 1 dış düğüme sahip
olduğunu hatırlayın. i’nci dış düğüme ulaşan rasgele yürüyüşün
olasılığı tam olarak,
lenen uzunluğu,
olduğu için, rasgele yürüyüşün bek-
| 359
ile verilir. Bu denklemin sağ tarafı n+1 eleman üzerinde bir olasılık
dağılımının entropisi olarak kolaylıkla tanınabilir. n + 1 eleman
için entropik değer, log(n+1) değerini aşmaz, bu kanıtı tamamlar.
Rasgele yürüyüşler ile ilgili bu sonuçla birlikte, merge(h1, h2)
işleminin O(log n) zamanda çalıştığını şimdi kolayca kanıtlayabiliriz.
Önerme 10.2. n1 ve n2 düğüm içeren iki yığının kökleri, sırasıyla,
h1
ve h2 ise, o zaman merge(h1, h2), n = n1 + n2 iken, O(log n)
beklenen zamanda çalışır.
Kanıt. h1, kökenli veya h2 kökenli yığınlar için merge algoritmasının her adımı, rasgele yürüyüşün bir adımını alır. Bu iki rasgele
yürüyüşten herhangi biri ağacın sonuna geldiğinde (h1 = null, veya
h2 = null)
algoritma sona erer. Bu nedenle, merge algoritması tara-
fından gerçekleştirilen adımların beklenen sayısı en fazla,
olur.
360|
Özet
Aşağıdaki teorem Karışık Yığın’ın performansını özetlemektedir:
Teorem 10.2. Karışık Yığın, Öncelik Kuyruğu arayüzünü uygular.
Karışık Yığın
işlem başına O(log n) beklenen zamanda çalışan ek-
le(x), sil() işlemlerini
destekler.
| 361
Tartışma ve Alıştırmalar
Mükemmel ikili ağacın bir dizi veya liste halinde dolaylı gösterimi
ilk olarak Eytzinger [27] tarafından önerilmiştir. Kendisi, asil ailelerin soy ağaçlarını içeren kitaplarda bu gösterimi kullanmıştır. Bu
bölümde anlatılan İkili Yığın veri yapısı, ilk olarak Williams [78]
tarafından tanıtıldı.
Bu bölümde tanıtılan Rasgele Karışık Yığın veri yapısı ilk olarak
Gambin ve Malinowski [34] tarafından önerilmiştir. Diğer Karışık
Yığın
uygulamaları vardır: Sol-odaklı yığınlar [16, 48, Bileşik Nes-
neler için Karma Kodları Bölümü], binom yığınları [75], Fibonacci
yığınları [30], eşleştirme yığınları [29], ve çarpık yığınlar [72]; ancak hiçbiri Karışık Yığın yapısı kadar basit değildir.
Yukarıdaki yapıların bazıları, decreaseKey(u, y) işlemini destekler. Bu işlem, u düğümünde depolanan değeri y’e düşürür
(y ≤ x
önkoşuldur). Önceki yapıların çoğu, u düğümünü silerek, ve y’i
ekleyerek, bu işlemi O(log n) zamanda destekleyebilir. Bununla
birlikte, bu yapıların bir kısmı, decreaseKey(u, y) işlemini daha
verimli olarak uygulayabilir. Özellikle, decreaseKey(u, y),
Fibonacci yığınları için O(1) amortize zaman alır. Eşleştirme yığınlarının [25] özel bir versiyonu için O(log log n) amortize zaman
alır. Bu daha verimli olan decreaseKey(u, y) işlemi, Dijkstra'nın
en kısa yol algoritması [30] dahil olmak üzere, birkaç grafik algoritmasını hızlandıran uygulamalarda kullanılır.
362|
Alıştırma 10.1. Şekil 10.2 sonunda gösterilen İkili Ağacı’na, 7 ve
daha sonra 3 değerlerinin eklenmesini gösterin.
Alıştırma 10.2. Şekil 10.2 sonunda gösterilen İkili Ağacı’ndan,
sonraki iki değerin (6 ve 8) silinmesini gösterin.
Alıştırma 10.3. İkili Ağacı’nda depolanan a[i] değerini silen sil(i)
işlemini uygulayın. Bu işlem O(log n) zamanda çalışmalıdır. Ardından, bu işlemin neden muhtemelen yararlı olmadığını açıklayın.
Alıştırma 10.4. İkili Ağacı’nın bir genellemesi olan d-Ağacı’nda,
her iç düğümün d çocuğu vardır. Mükemmel d-Ağaç’larını,
Eytzinger yöntemini kullanarak, diziler yardımıyla göstermek
mümkündür. Verilen bir i endeksi için, i’nin babası ve i’nin d çocuğunun her birinin endeksini belirleyen denklemleri hesaplayın.
Alıştırma 10.5. Alıştırma 10.4’te öğrendiklerinizi kullanarak, İkili
Yığın’ın d-li
D-li Yığın
genelleştirmesi olan D-li Yığını tasarlayın ve uygulayın.
üzerindeki işlemlerin çalışma zamanlarını analiz edin, ve
sizin yazdığınız D-li Yığın uygulamasının performansını, bu bölümde verilen İkili Yığın uygulamasının performansı ile karşılaştırın.
Alıştırma 10.6. Şekil 10.4’te gösterilen, h1 Karışık Yığını’na, 17 ve
sonra 82 değerinin eklenmesini gösterin. Rasgele biti örneklemek
için, gerekirse madeni para kullanın.
| 363
Alıştırma 10.7. Şekil 10.4’te gösterilen, h1 Karışık Yığını’ndan,
sonraki iki değerin (4 ve 8) silinmesini gösterin. Rasgele biti örneklemek için, gerekirse madeni para kullanın.
Alıştırma 10.8. Karışık Yığın’dan, u düğümünü silen sil(u) yöntemini uygulayın. Bu yöntem O(log n) beklenen zamanda çalışmalıdır.
Alıştırma 10.9. İkili Yığın veya Karışık Yığın içinde depolanan, en
küçük ikinci değeri sabit zamanda nasıl bulacağınızı gösterin.
Alıştırma 10.10. İkili Yığın veya Karışık Yığın içinde depolanan en
küçük k’nci değeri O(k log k) zamanda nasıl bulacağınızı gösterin
(İpucu: İkinci bir yığının kullanılması yardımcı olacaktır).
Alıştırma 10.11. Toplam uzunluğu n olan k adet sıralı liste verilsin. Bir yığın kullanarak, bunları tek bir sıralı liste halinde O(n log
k)
zamanda nasıl birleştireceğinizi gösterin (İpucu: Öğretici olması
açısından, başlangıçta k = 2 olsun).
364|
| 365
Bölüm 11
Sıralama Algoritmaları
Bu bölüm, n elemanlı bir kümenin sıralaması ile ilgili algoritmaları
tanıtıyor. Veri yapıları üzerine bir kitapta, bu konunun dahil edilmesi için birçok iyi neden vardır. En belirgin nedeni, bu sıralama
algoritmalarının ikisinin (hızlı-sıralama ve yığın-sıralama), daha
önce incelediğimiz veri yapılarının ikisi ile yakından ilişkili olmasıdır (sırasıyla, rasgele ikili arama ağaçları ve yığınlar).
Bu bölümün birinci kısmında, yalnızca karşılaştırmalara dayanan
sıralama algoritmalarını tartışacağız ve O(n log n) zamanda çalışan
üç algoritmayı tanıtacağız. Anlaşılan, her üç algoritma da asimptotik olarak en iyidir; sadece karşılaştırmaları kullanan hiçbir algoritma, en kötü durumda veya ortalama olarak n log n karşılaştırmadan daha azını gerçekleştirmemiştir.
Devam etmeden önce, unutmayın ki, önceki bölümlerde tanıtılan
Sıralı Küme
veya Öncelik Kuyruğu uygulamalarının herhangi biri,
O(n log n) zamanda çalışan bir sıralama algoritmasını elde etmek
için kullanılabilir. Örneğin, İkili Yığın veya Karışık Yığın üzerinde n
ekle(x)
işlemini ve bunu izleyen n sil() işlemini gerçekleştirerek n
elemanı sıralayabiliriz. Alternatif olarak, İkili Arama Ağacı veri
366|
yapılarının herhangi biri üzerinde, n ekle(x) işlemini çalıştırabilir
ve sonra elemanları sıralı düzende elde etmek için içsel-sıra gezintisi (Alıştırma 6.8) gerçekleştirebiliriz. Ancak, her iki durumda da,
tam olarak kullanılmayan bir yapıyı oluşturmak için bir sürü zahmete katlanılmaktadır. Bu nedenle sıralama, mümkün olan en hızlı,
basit ve alan-verimli direkt yöntemler geliştirmeye değer önemli bir
problemdir.
Bu bölümün ikinci kısmı, karşılaştırmaların yanı sıra başka işlemlere yer verirsek, ne olacağını önceden tahmin edemeyeceğimizi gösteriyor. Gerçekten, {0,..,nc – 1} aralığındaki n tamsayıyı, dizi endekslemesini kullanarak, O(cn) zamanda sıralamak mümkündür.
| 367
Karşılaştırmaya-Dayalı Sıralamalar
Bu bölümde, üç sıralama algoritmasını tanıtacağız: birleştirereksıralama, hızlı-sıralama ve yığın-sıralama. Bu algoritmaların her
biri girdi olarak a dizisini alır ve a’nın elemanlarını artan sırada
O(n log n) (beklenen) zamanda sıralar. Bu algoritmaların hepsi
karşılaştırmaya-dayalıdır. İkinci argümanları, c, compare(a, b)
yöntemini uygulayan bir Karşılaştırıcı’dır. Bu algoritmalar hangi
tür veriyi sıraladığını önemsemez; veri üzerinde yaptıkları tek işlem
compare(a, b)
yöntemini kullanarak yaptıkları karşılaştırmalardır.
SKüme Arayüzü-Sıralı Kümeler Bölümü’nden hatırlamalısınız ki, a
b
ise compare(a, b) negatif bir değer döndürür, a
tif bir değer döndürür, ve a = b ise sıfır döndürür.
b
için pozi-
368|
Birleştirerek-Sıralama
Birleştirerek-sıralama algoritması özyinelemeli böl ve yönet tekniğine klasik bir örnektir: a uzunluğu en fazla 1 ise, a zaten sıralanmıştır, bu yüzden hiçbir şey yapmayız. Aksi takdirde, a dizisini iki
parçaya böleriz, a0 = a[0],...,a[n/2 – 1], ve a1 = a[n/2],...,
a[n – 1].
Özyinelemeli olarak a0 ve a1 dizilerini sıralarız, ve sonra
(şimdi sıralanmış bulunan) a0 ve a1 dizilerini tam sıralı bir a dizisini elde etmek için birleştiririz.
Şekil 11.1 bir örneği göstermektedir.
İki sıralı diziyi, a0 ve a1, birleştirmek, sıralamaya göre oldukça
kolaydır. Her seferinde elemanlardan birini a’ya ekleriz. a0 veya
a1
boşsa, o zaman diğer (boş olmayan) dizideki, sonra gelen ele-
manları ekleriz. Aksi takdirde, a0 içindeki sonraki elemanın ve a1
içindeki sonraki elemanın en küçüğünü alır ve bunu a dizisine ekleriz:
| 369
Fark edebilirsiniz ki, merge(a0, a1, a, c) algoritması a0 veya a1
dizilerindeki elemanları tüketmeden önce en fazla n – 1 karşılaştırma gerçekleştirir.
370|
Birleştirerek-sıralama için gerekli çalışma zamanını anlamak için
en kolay yol, onu bir özyineleme ağacı olarak düşünmektir. Şimdilik, n’in ikinin kuvveti olduğunu varsayın, öyle ki, log n bir tamsayı iken, n = 2log n olsun. Şekil 11.2’e bakın. Birleştirerek-sıralama,
elemanın sıralanması problemini, her biri n/2 elemanı sıralayan
n
iki altproblem haline dönüştürür. Bu iki altproblem, yine daha sonra iki problem haline dönüşür, her biri n/4 elemandan oluşan dört
altproblem elde edilir. Bu dört altproblem, her biri n/8 elemandan
oluşan sekiz altproblem haline dönüşür, vb. Bu sürecin sonunda,
altproblem, her birinin boyutu 1 olan n probleme dönüştürülür.
n/2
n/2
i
boyutundaki her altproblem için, birleştirmek ve veri kopya-
lamak için harcanan zaman O(n/2i) olur. n/2i boyutunda
2
i
altproblem olduğu için 2i boyutunda problemlerin üzerinde ça-
lışmak için harcanan toplam zaman, özyinelemeli çağrılar önemsenmediği takdirde,
| 371
olur.
Böylece, birleştirerek-sıralama için harcanan toplam zaman,
olarak hesaplanır. Aşağıdaki teoremin kanıtı, az önceki analize dayanır, ancak n, 2’nin kuvveti değil iken, biraz daha dikkatli olunmak zorundayız.
Teorem 11.1. mergeSort(a, c) algoritması O(n log n) zamanda
çalışır ve en çok n log n karşılaştırma gerçekleştirir.
Kanıt. Kanıt n üzerine tümevarım yöntemiyle yapılacak. Başlangıç
durumu, n = 1, önemsizdir. Uzunluğu 0, veya 1 olan bir dizi ile
başlandığında, algoritma herhangi bir karşılaştırma yapmadan sadece diziyi döndürür.
Toplam uzunluğu n olan iki sıralı listeyi birleştirmek, en fazla
n – 1
karşılaştırmayı gerektirir. C(n) sayısı, mergeSort(a, c) tara-
fından n uzunluğunda bir a dizisi üzerinde gerçekleştirilen karşılaştırmaların maksimum sayısı olsun. n çift ise, o zaman iki
altproblem için tümevarım hipotezini uygulayarak,
372|
elde ederiz. n tek olduğu zaman, durum biraz daha karmaşıktır. Bu
durum için, doğrulanması kolay iki eşitsizlik kullanıyoruz: Her x ≥
1
için,
ve her x ≥ ½ için,
(11.1) eşitsizliği log(x) + 1 = log(2x) gerçeğinden ileri geliyor.
(11.2) eşitsizliği log fonksiyonunun içbükey özelliğe sahip olması
gerçeğinden ileri geliyor. Elimizdeki bu araçlar ile, n tek iken,
hesaplarız.
| 373
Hızlı-Sıralama
Hızlı-sıralama algoritması diğer bir klasik böl ve yönet algoritmasıdır. İki altproblemi çözdükten sonra birleştiren birleştirereksıralamanın aksine, hızlı-sıralama, çalışmasının hepsini veri üzerinde açık ve belirgin bir şekilde yapar.
Hızlı-sıralamanın tanımlanması oldukça kolaydır: a içinden rasgele
bir pivot elemanı, x, seçilir; x’den küçük elemanların oluşturduğu
küme, x’e eşit elemanların oluşturduğu küme, ve x’den büyük elemanların oluşturduğu küme olmak üzere a üç parçaya bölünür, ve
nihayet, özyinelemeli olarak birinci ve üçüncü kümeler sıralanır.
Şekil 11.3’de bir örnek gösterilmiştir.
374|
Tüm bunlar yerli yerinde yapılır, böylece, sıralanacak altdizilerin
kopyalarını yapmak yerine, quickSort(a, i, n, c) yöntemi sadece
a[i],…,a[i + n – 1]
altdizisini sıralar. Başlangıçta, bu yöntem
quickSort(a, 0, a.length, c)
argümanları ile çağrılır.
| 375
Hızlı-sıralama algoritmasının merkezinde, yerinde bölümleme algoritması vardır. Bu algoritma, herhangi bir ekstra alan kullanmadan, a elemanlarının yerlerini değiştirerek, p ve q endekslerini hesaplar; öyle ki,
Kodda while döngüsü tarafından yapılan bu bölümleme, ilk ve son
koşulu korumak şartıyla, p’nin yinelemeli artırılmasıyla ve q’nun
azaltılmasıyla çalışır. Her adımda, j pozisyonundaki eleman ya öne
taşınır, ya olduğu yerden sola kaydırılır, veya geriye taşınır. İlk iki
durumda j artırılırken, son durumda j artırılmaz, çünkü j pozisyonundaki yeni eleman henüz işlenmemiştir.
Hızlı-sıralama Bölüm 7’de anlatılan Rasgele İkili Arama Ağaç’ları
ile çok yakından ilgilidir. Aslında, hızlı-sıralamanın girdisi n farklı
376|
elemandan oluşuyorsa, hızlı-sıralamanın özyineleme ağacı bir
Rasgele İkili Arama Ağacı’dır.
Rasgele İkili Arama Ağacı’nı
Bunu anlamak için, hatırlayın ki,
oluşturacağımız zaman yaptığımız ilk
şey, rasgele bir x elemanını seçmek ve bunu ağacın kökü yapmaktı.
Bundan sonra, her bir eleman, sonunda x ile karşılaştırılmıştı, küçük elemanlar sol altağacın içine giderken, daha büyük elemanlar
sağ altağacın içine depolanmıştı.
Hızlı-sıralamada rasgele bir x elemanı seçeriz ve her şeyi hemen x
ile karşılaştırırız, daha küçük elemanları dizinin başına koyarız, ve
daha büyük elemanları dizinin sonuna koyarız. Daha sonra hızlısıralama özyinelemeli olarak, dizinin başlangıcını ve dizinin sonunu sıralarken, Rasgele İkili Arama Ağacı özyinelemeli olarak kökün sol altağacına daha küçük elemanları ve kökün sağ altağacına
daha büyük elemanları ekler.
Rasgele İkili Arama Ağaç’ları
ve hızlı-sıralama arasındaki yukarı-
daki benzeşmeler, Önerme 7.1’i hızlı-sıralama ile ilgili olarak şöyle
tercüme eder:
Önerme 11.1. 0,…,n – 1 tamsayılarını içeren bir diziyi sıralaması
için hızlı-sıralamayı çağırdığınızda, i elemanını pivot eleman ile
karşılaştırmak, en fazla Hi+1 + Hn-i beklenen sayıda gerçekleşir.
Özetle, harmonik sayılar, bize hızlı-sıralamanın çalışma zamanı ile
ilgili aşağıdaki teoremi verir:
| 377
Teorem 11.2. Hızlı-sıralama n farklı elemanı içeren bir diziyi sıralamak için çağrıldığında, gerçekleştirilen karşılaştırmalar en fazla
2n ln n + O(n)
beklenen sayıda olur.
Kanıt. n farklı eleman sıralanırken, hızlı-sıralama tarafından gerçekleştirilen karşılaştırmaların sayısı T olsun. Önerme 11.1 ve beklentinin doğrusallık özelliği kullanılarak:
Teorem 11.3 sıralanan tüm elemanların birbirinden farklı olduğu
durumu anlatıyor. Girdi, a, dizisi, yinelenen elemanları içeriyorsa,
hızlı-sıralamanın beklenen çalışma zamanı daha kötü değildir, ve
hatta daha da iyi olabilir; ne zaman yinelenen bir eleman, x, pivot
olarak seçilse, x’in tüm yinelemeleri biraraya gruplanır, ve her iki
altproblemin hiçbirinde de yer almazlar.
Teorem 11.3. quickSort(a, c) işlemi O(n log n) beklenen zamanda
çalışır, ve gerçekleştirdiği karşılaştırmalar en fazla 2n ln n + O(n)
beklenen sayıda olur.
378|
| 379
Yığın-Sıralama
Yığın-sıralama algoritması diğer bir yerinde-sıralama algoritmasıdır. Yığın-sıralama Bölüm 10’da tartışılan ikili yığınları kullanır.
Hatırlayın ki, İkili Yığın veri yapısı tek bir dizi kullanarak yığını
göstermektedir. Yığın-sıralama algoritması girdi, a, dizisini bir
yığına dönüştürür ve daha sonra ard arda minimum değeri çıkarır.
Özellikle, bir yığın, a, dizisi içindeki n elemanı en küçük değer
kökte, a[0], depolanmak üzere, a[0], …,a[n – 1] konumlarında
depolar. a, İkili Yığın’a dönüştürüldükten sonra, yığın sıralama
algoritması tekrar tekrar a[0] ile a[n – 1]’in yerlerini değiştirerek,
n’i
1 azaltır, ve trickledown(0) çağrılır. Böylece- a[0],...,a[n – 2],
bir kere daha geçerli bir yığın olacaktır. Bu süreç sona erdiğinde
(çünkü, n = 0), a elemanları azalan sırada depolanmış olur, a sıralamasını tersine çevirerek sıralamanın son halini elde ederiz. Şekil
11.4 heapSort(a, c) çalıştırmasına bir örnek gösteriyor.
Yığın-sıralamanın anahtar altyordamı, sıralı olmayan bir a dizisini
yığına dönüştüren kurucu programdır. İkili Yığın’ın ekle(x) işlemini
380|
defalarca çağırarak bunu O(n log n) zamanda yapmak kolay olurdu, ancak aşağıdan-yukarıya algoritma kullanarak daha iyisini yapabiliriz. Hatırlayın ki, bir İkili Yığın içinde a[i]’nin çocukları a[2i
+ 1]
ve a[2i + 2] konumlarında depolanır. Bunun anlamı,
elemanlarının çocuğu yoktur. Diğer bir deyiş-
le,
her biri boyutu 1 olan bir altyığındır. Şimdi,
geriye doğru çalışırsak,
için trickleDown(i)
çağrısını yaparız. Bu işe yarar, çünkü trickleDown(i) çağrısı yapıldığı zaman a[i]’nin her iki çocuğu, bir altyığının köküdür, böylece
trickleDown(i)
çağrısı a[i]’yi kendi altyığınının kökü yapar.
Bu aşağıdan-yukarıya strateji ile ilgili ilginç olan, n defa ekle(x)
çağırmaktan daha verimli olmasıdır. Bunu anlamak için, n/2 eleman için, hiçbir şey yapmayız, n/4 eleman için a[i] kökenli ve yüksekliği bir olan bir altyığın üzerine trickleDown(i) çağrısı yaparız,
n/8
eleman için yüksekliği iki olan bir altyığın üzerine
trickleDown(i)
çağrısı yaparız, vb. trickleDown(i) tarafından yapı-
lan iş, a[i] kökenli bir altyığının yüksekliği ile orantılı olduğu için,
toplam yapılan iş en fazla,
| 381
olur.
Sondan ikinci eşitliği,
toplamının, ilk defa yazı gelene
kadar atılan yazı-turanın beklenen sayısına eşit olduğunu hatırlayarak, ve Önerme 4.2’yi uygulayarak oluşturduk.
Aşağıdaki teorem heapSort(a, c) performansını açıklıyor.
Teorem 11.4. heapSort(a, c) işlemi O(n log n) zamanda çalışır ve
en fazla 2n log n + O(n) karşılaştırma gerçekleştirir.
Kanıt. Algoritma üç adımda çalışır: (1) a dizisinin bir yığın içine
dönüştürülmesi (2) a içinden ard arda minimum elemanın çıkarılması, (3) a elemanlarının tersine çevrilmesi. Adım 1’in çalışması
için, O(n) zaman gerektiği ve O(n) karşılaştırma gerçekleştirdiğini
az önce tartışmıştık. Adım 3, O(n) zaman alır ve hiçbir karşılaştırma yapmaz. Adım 2, trickleDown(0) için n çağrı gerçekleştirir. i
'nci böyle bir çağrı n – i boyutunda bir yığın üzerinde çalışır ve en
fazla 2log(n – i) karşılaştırma gerçekleştirir. i üzerinden bunları
toplayarak,
382|
elde ederiz. Üç adımın her birinde yapılan karşılaştırmaların sayısını toplayarak kanıt tamamlanır.
| 383
Karşılaştırmaya Dayalı Sıralama için Alt-Sınır
Gördüğümüz karşılaştırmaya-dayalı sıralama algoritmalarının her
biri O(n log n) zamanda çalışmaktadır. Şu andan itibaren, daha
hızlı algoritmaların var olup olmadığına dikkatimize vereceğiz. Bu
soruya verilecek en kısa cevap hayır olacaktır. a elemanları üzerinde sadece karşılaştırmaya izin veriliyorsa, o zaman hiçbir algoritma
n log n
karşılaştırmadana daha azını yapmaktan kaçınamaz. Bunu
kanıtlamak zor değildir, ancak biraz hayal gücü gerektirir. Kanıt
eninde sonunda,
gerçeğinden yola çıkar (Bu gerçeğin kanıtlanması Alıştırma 11.1’e
bırakılmıştır).
Belirli bir sabit n değeri için dikkatimizi ilk olarak birleştirereksıralama ve yığın-sıralama gibi deterministik algoritmalara odaklayacağız. Birbirinden farklı n elemanı sıralamak için böyle bir algo-
384|
ritmanın kullanıldığını varsayın. Alt sınırı kanıtlama yolunda anahtar rol oynayan gözlem şudur ki, sabit bir n değeri ile başlayan
deterministik bir algoritma için, karşılaştırılan ilk eleman çifti her
zaman aynıdır. Örneğin, heapSort(a, c) için n çift ise,
trickleDown(i)
için yapılan ilk çağrı i = n/2 – 1 için yapılır, ve ilk
karşılaştırma a[n/2 – 1] ve a[n – 1] elemanları arasında gerçekleşir.
Tüm girdi elemanları birbirinden farklı olduğu için, bu ilk karşılaştırmanın sadece iki olası sonucu vardır. Algoritma tarafından yapılan ikinci karşılaştırma, birinci karşılaştırmanın sonucuna bağlı
olabilir. Üçüncü karşılaştırma, böylece ilk ikisinin sonuçlarına bağlı
olabilir, vb. Bu nedenle, herhangi bir deterministik, karşılaştırmaya-dayalı sıralama algoritması köklü bir ikili karşılaştırma ağacı
olarak görülebilir. Bu ağacın her, u iç düğümü, u.i ve u.j endeks
çifti ile etiketlenmiştir. a[u.i] < a[u.j] ise algoritma sol alt ağaca
doğru ilerler, aksi takdirde sağ alt ağaca doğru devam eder. Bu ağacın her, w yaprağı, 0,…,n – 1 aralığındaki bir w.p[0],…,w.p[n – 1]
permütasyonu ile etiketlenmiştir. Bu permütasyon, karşılaştırma
ağacı bu yaprağa ulaşırsa, a’yı sıralamak için gereklidir. Yani,
Şekil 11.5, boyutu, n = 3 olan, bir dizi için karşılaştırma ağacına
bir örnek göstermektedir.
| 385
Karşılaştırma ağacı, bir sıralama algoritması hakkında her şeyi anlatır. Herhangi bir a girdi dizisi için, birbirinden farklı, n, elemanı
hangi sırada karşılaştıracağımızı, ve a’yı sıralarken nasıl düzenleyeceğimizi belirtir. Sonuç olarak, karşılaştırma ağacı en az n! yapraktan oluşmalıdır; eğer değilse, aynı yaprağa giden iki farklı
permütasyon
bulunmaktadır;
bu
nedenle
algoritma
bu
permütasyonların en azından birini doğru olarak sıralamayacaktır.
Örneğin, Şekil 11.6’deki karşılaştırma ağacı, 4
3! = 6
yaprağa
sahiptir. Bu ağacı incelersek, görüyoruz ki, iki girdi dizisi 3, 1, 2
ve 3, 2, 1 en sağdaki yaprağa götürür. 3, 1, 2 girdisi için doğru
çıktı üretilir, a[1] = 1, a[2] = 2, a[0] = 3. Ancak, 3, 2, 1 girdisi
için,
hatalı çıktı üretir a[1] = 2, a[2] = 1, a[0] = 3. Bu tartışma, karşılaştırmaya dayalı algoritmalar için birincil alt sınırı açıklıyor.
Teorem 11.5. Herhangi bir deterministik, karşılaştırmaya dayalı,
A, sıralama algoritması ve herhangi bir n ≥ 1 tamsayısı için, n
uzunluğunda öyle bir, a, girdi dizisi vardır ki, A, a dizisini sıralarken en az log(n!)= n logn – O(n) karşılaştırma gerçekleştirir.
386|
Kanıt. Önceki tartışmayla, A tarafından tanımlanan karşılaştırma
ağacı en az n! yaprak içermelidir. Kolay bir tümevarım kanıtı gösterir ki, k yapraklı herhangi bir ikili ağaç en az log k yüksekliğe
sahiptir. Bu nedenle, A’nın karşılaştırma ağacında, derinliği en az
log(n!)
olan bir w yaprağı ve bu yaprağa giden bir girdi, a dizisi
bulunmaktadır. Girdi, a, dizisi üzerinde A, en az log(n!) karşılaştırma gerçekleştirir.
Teorem
11.5
birleştirerek-sıralama
ve
yığın-sıralama
gibi
deterministik algoritmalar ile ilgilenir, ancak hızlı-sıralama gibi
randomize algoritmalar hakkında hiçbir şey söylemez. Acaba bir
randomize algoritma, karşılaştırma sayısı için var olan log(n!) alt
sınırını aşabilir mi? Cevap, yine hayır. Bunu kanıtlamanın yolu,
yine, randomize algoritmalar hakkında farklı düşünmektir.
Aşağıdaki tartışmada varsayalım ki, karar ağaçlarımız şu yolla “düzeltilmiştir”: Girdi, a dizisi tarafından ulaşılamayan herhangi bir
düğüm silinir. Bu temizliğin anlamı ağaç tam olarak n! yaprağa
sahip olur. n! yaprağı vardır çünkü aksi takdirde, sıralama doğru
olmazdı. En fazla n! yaprağı vardır, çünkü n farklı elemanın olası
her n! permütasyonu, karar ağacında kökten başlayarak yaprağa
giden tam olarak bir yolu izler.
İki girdi kabul eden deterministik bir R, randomize sıralama algoritması düşünebiliriz: Sıralanması gereken bir girdi a dizisi, ve
[0, 1]
aralığında rasgele reel sayılardan oluşan uzun bir dizi
b = b1, b2, b3,…,bm.
Rasgele sayılar, algoritma için randomizasyon
| 387
sağlıyor. Algoritmanın, yazı tura atması, veya rasgele bir seçim
yapması gerektiğinde, bunu b içinden bazı elemanı kullanarak yapar. Örneğin, hızlı-sıralamada ilk pivot endeksini hesaplamak için,
algoritma
formülünü kullanabilir. Şimdi fark edebilirsiniz ki,
eğer b’yi, bazı özel
bir
dizilimine sabitleyebilirsek, R deterministik
sıralama algoritması haline gelir ve ilgili karşılaştırma
ağacı
, olur. Ardından, fark edebilirsiniz ki {1,…,n} aralığında
rasgele bir a permütasyonu seçersek, bu,
’nin n! yaprağı için-
den, rasgele bir, w, yaprağını seçmekle eşdeğerdir.
Alıştırma 11.13, k yapraklı herhangi bir ikili ağaçtan rasgele bir
yaprak seçersek, o yaprağın beklenen derinliğinin en az log k olduğunu kanıtlamanızı istiyor. Bu nedenle, {1,…,n} aralığında rasgele
bir permütasyon içeren bir girdi dizisi verildiğinde, (deterministik)
algoritma,
tarafından yapılan karşılaştırmaların beklenen sayı-
sı en az log(n!) olarak hesaplanır.
Son olarak, not etmelisiniz ki,
’nin her seçimi için bu doğrudur,
bu nedenle R için bile geçerlidir. Böylece, randomize algoritmalar
için alt sınır kanıtı tamamlanır.
Teorem 11.6. Herhangi bir (deterministik veya randomize) karşılaştırmaya-dayalı sıralama algoritması, A, herhangi bir tamsayı n
≥ 1 için, {1,…,n} aralığında rasgele bir permütasyonu sıralarken,
en az log(n!) = n log n – O(n) beklenen sayıda karşılaştırma gerçekleştirir.
388|
Sayma Sıralama ve Taban Sıralaması
Bu bölümde karşılaştırmaya dayalı olmayan iki sıralama algoritmasını tanıtıyoruz. Bu algoritmalar küçük tamsayıları sıralamak için
özelleştirilmiştir, ve a dizisindeki elemanların parçalarını bir diziye
endeks olarak kullanarak, Teorem 11.5’in alt sınırından kurtulurlar.
şeklinde bir ifade düşünün. Bu ifade sabit zamanda çalışır, ancak,
a[i]
değerine bağlı olarak değişen c.length kadar farklı olası sonu-
cu vardır. Bunun anlamı, bu tür bir komut içeren bir algoritmanın
çalışması ikili ağaç olarak modellenemez. Sonuç olarak, bu bölümdeki algoritmaların, karşılaştırmaya dayalı algoritmalardan daha
hızlı sıralamalarına neden budur.
| 389
Sayma Sıralaması
Her biri 0,…,k – 1 aralığında n tamsayıdan oluşan bir girdi, a dizisinin olduğunu varsayalım. Sayma-sıralama algoritması, sayaçları
depolayan, yardımcı bir c dizisini kullanarak, a’yı sıralar. a’nın
sıralı çıktısını da yardımcı bir b dizisi tutar.
Sayma-sıralaması arkasındaki fikir basittir: Her i
{0,…,k – 1}
için, a içindeki i’nin yinelenme sayısını sayın ve bunu c[i]’de saklayın. Şimdi sıralama sonrasında, 0’ın yinelenme sayısını c[0], 1’in
yinelenme sayısını c[1], 2’nin yinelenme sayısını c[2],…,k – 1’in
yinelenme sayısını c[k – 1] tutacaktır. Bunu gerçekleştiren kod çok
düzgündür, ve örnek çalıştırması Şekil 11.7’de gösterilmiştir:
Bu koddaki birinci for döngüsü, her c[i] sayacını, a içindeki i yinelemelerini sayarak belirler. a değerlerini endeks olarak kullanarak,
bu sayaçların tümü O(n) zamanda tek bir for döngüsü içinde hesaplanabilir.
390|
Bu noktada, çıktı dizisi b’yi doldurmak için doğrudan c’yi kullanabiliriz. Ancak, a elemanlarının ilişkili verisi varsa, bu işe yaramayacaktır. Bu nedenle, b içine a elemanlarını kopyalamak için biraz
fazladan çaba harcarız.
O(k) zaman alan bir sonraki for döngüsü sayaçların toplamını he-
saplar, böylece a içinde, i’den daha az, veya eşit olan elemanların
sayısı c[i]’de saklanır. Özellikle, her i
dizisi b için,
{0,…,k – 1}
için, çıktı
| 391
olacaktır. Son olarak, algoritma, geri yönde tarayarak, elemanlarını
sıralı bir şekilde çıktı b dizisine yerleştirir. Tararken, a[i] = j elemanı, b[c[j] – 1] konumuna yerleştirilir ve c[j] değeri 1 azaltılır.
Teorem 11.7. countingSort(a, k) yöntemi, {0,…,k – 1} kümesinden n tamsayıyı içeren, a dizisini O(n + k) zamanda sıralayabilir.
Sayma-sıralaması algoritmasının kararlı olmak gibi güzel bir özelliği vardır; eşit elemanların göreli sırasını korur. İki eleman a[i] ve
a[j],
aynı değere sahipse, ve i
j
ise, b içinde a[i], a[j]’den önce
görünecektir. Bir sonraki bölümde bu yararlı olacaktır.
392|
Taban-Sıralaması
Sayma-sıralaması n dizi uzunluğu, dizinin maksimum değeri, k –
1’den
çok daha küçük olmadığı zaman, bir tamsayı dizisini sırala-
makta çok verimlidir. Şimdi tanıtacağımız taban-sıralaması algoritması, sayma-sıralamasının birkaç geçişini kullanıyor ve çok daha
büyük bir maksimum değer aralığını sıralayabiliyor.
Taban-sıralaması, sayma sıralamasının w/d geçişini kullanarak her
geçişte d bit olmak üzere, w-bit tamsayıları sıralıyor. Daha kesin
olarak, taban-sıralamasında tamsayılar önce en az önemli d bitine
göre, daha sonra bir sonraki önemli d bitine göre, ve bu şekilde son
seferde en önemli d bitine göre sıralanır.
(Bu kodda, (a[i]>>d * p)&((1<<d) – 1)
(p + 1)d – 1,…,pd
ifadesi, a[i]’nin
biti tarafından ikili gösterimi verilen tamsayıyı
| 393
çıkarır). Bu algoritma adımlarının bir örneği Şekil 11.8’de gösterilmiştir.
Bu dikkat çekici algoritma doğru sıralamaktadır, çünkü saymasıralaması kararlı bir sıralama algoritmasıdır. a’nın iki elemanı
x<y
ise, ve x, y’den en önemli r endeksinde farklılık gösteriyorsa,
o zaman r/d geçişi sırasında x, y’den önce yerleştirilecektir ve
daha sonraki geçişlerde, x ve y’nin göreli sırası değişmeyecektir.
Taban-sıralaması, sayma-sıralamasının w/d geçişini çalıştırır. Her
geçiş O(n + 2d) çalışma zamanı gerektirir. Taban-sıralamasının
performansı aşağıdaki teorem ile verilmiştir.
Teorem 11.8. Herhangi bir tamsayı d > 0 için, radixSort(a, k)
yöntemi, n adet w-bit tamsayı içeren bir a dizisini O((w/d)(n+2d))
çalışma zamanında sıralar.
394|
Bunun yerine, {0, nc – 1} aralığında dizinin elemanlarını düşünürsek, ve d = log n aldığımızda, Teorem 11.8’in aşağıdaki versiyonunu elde ederiz.
Sonuç 11.1. radixSort(a, k) yöntemi {0, nc – 1} aralığında n tamsayı değeri içeren bir a dizisini O(cn) zamanda sıralar.
| 395
Tartışma ve Alıştırmalar
Sıralama, bilgisayar bilimlerinin temel bir algoritmik problemidir,
ve uzun bir geçmişi vardır. Knuth [48] birleştirerek-sıralama algoritması için von Neumann’a (1945) başvuruyor. Hızlı-sıralama,
Hoare [39] sayesindedir. Orijinal yığın-sıralama algoritması
Williams [78]’a atfedilir, ancak burada yer alan versiyonun (yığın
O(n) zaman içinde aşağıdan-yukarıya oluşturuluyorsa) kaynağı
Floyd [28]’dur. Karşılaştırmaya dayalı sıralamada alt sınırlar çok
iyi bilinmektedir. Aşağıda tabloda, karşılaştırmaya dayalı algoritmaların performansı özetleniyor:
Bu karşılaştırmaya dayalı algoritmaların avantaj ve dezavantajları
vardır. Birleştirerek-sıralama, en az sayıda karşılaştırma yapar ve
randomizasyona dayanmaz. Ne yazık ki, birleştirme safhasında bir
yardımcı dizi kullanır. Bu diziyi tahsis etmek pahalı olabilir ve bellek miktarı sınırlı ise potansiyel bir başarısızlık sebebidir. Hızlısıralama yerinde-işlem yapan bir algoritmadır ve yaptığı karşılaştırma sayısı açısından baştan ikincidir, ancak randomizedir, bu nedenle çalışma zamanı her zaman garanti edilmez. Yığın-sıralama en
396|
fazla sayıda karşılaştırmayı yapar, ama yerinde ve deterministik
işlem yapar.
Bağlantılı-listeyi sıralarken birleştirerek-sıralama net olarak enöndedir. Bu durumda, yardımcı dizi gerekli değildir; sıralı iki bağlantılı-liste, işaretçi işlemleri ile çok kolayca tek bir bağlantılı liste
halinde birleştirilebilir (bkz. Alıştırma 11.2).
Bu bölümde tanıtılan sayma-sıralaması ve taban-sıralaması algoritmaları Seward sayesindedir [68, bkz.Dizi İki Başlı Kuyruk: Dizi
Kullanan Hızlı İki Başlı Kuyruk Bölümü]. Ancak, tabansıralamasının değişik çeşitleri, 1920'lerden beri, delikli kart sıralama makinelerini kullanarak delikli kartları sıralamak için kullanılmaktadır. Bu makineler kartın belirli bir yerindeki bir deliğin varlığına (veya yokluğuna) dayalı olarak kart destesini iki yığın halinde
sıralayabilirler. Farklı delik yerleri için bu işlemi tekrar etmek taban-sıralamasının bir uygulamasını verir.
Son olarak, not ediniz ki, sayma-sıralama ve taban-sıralama, negatif
olmayan tamsayıların yanı sıra, diğer sayı türlerini sıralamak için
de kullanılabilir. Kolay değişiklikler yaparak {a,…,b} aralığındaki
tamsayılar, sayma sıralama ile O(n + b – a) çalışma zamanında
sıralanabilir. Benzer şekilde, taban-sıralama aynı aralıktaki tamsayıları O(n(logn(b – a)) çalışma zamanında sıralayabilir. Son olarak, bu algoritmaların her ikisi de, IEEE 754 kayan nokta formatında, kayan nokta sayılarını sıralamak için kullanılabilir. Bunun nedeni, IEEE formatı, iki kayan noktalı sayının değerini, sanki işaretli
| 397
ikili gösteriminde birer tamsayı gibi karşılaştırmak için tasarlanmıştır.
Alıştırma 11.1. 1,7,4,6,2,8,3,5 içeren bir girdi dizisi üzerinde birleştirme-sıralama ve yığın-sıralamanın çalışmasını gösterin. Aynı
dizi üzerinde, hızlı-sıralamanın olası bir çalışmasına örnek gösterin.
Alıştırma 11.2. Birleştirme-sıralama algoritmasının bir versiyonunu uygulayın. Bu versiyon, yardımcı bir dizi kullanmadan Çifte
Bağlantılı Liste’yi
sıralamalıdır (bkz. Alıştırma 3.13).
Alıştırma 11.3. Bazı quickSort(a, i, n, c) uygulamaları, pivot olarak her zaman a[i] kullanır. n uzunluğunda öyle bir girdi dizisi örneği verin ki, bu girdiyle çalışan uygulama
karşılaştırma ger-
çekleştirsin.
Alıştırma 11.4. Bazı quickSort(a, i, n, c) uygulamaları, pivot olarak her zaman a[i + n/2] kullanır. n uzunluğunda, öyle bir girdi
dizisi örneği verin ki, bu girdiyle çalışan uygulama
karşılaştır-
ma gerçekleştirsin.
Alıştırma 11.5. a[i],…,a[i + n – 1] değerlerine bakmadan, pivotu
deterministik olarak seçen herhangi bir quickSort(a, i, n, c) uygulaması için, her zaman
karşılaştırma gerçekleştiren, n uzunlu-
ğunda bir girdi dizisinin var olduğunu gösterin.
398|
Alıştırma 11.6. quickSort(a, i, n, c) uygulamasına bir argüman
olarak geçirilen bir Karşılaştırıcı, c, tasarlayın. Hızlı-sıralama, bu
argümanla çalıştırıldığında,
karşılaştırma gerçekleştirmelidir.
(İpucu: Karşılaştırıcının, karşılaştırılan değerlere gerçekten bakması gerekli değildir).
Alıştırma 11.7. Hızlı sıralama tarafından yapılan karşılaştırmaların
beklenen sayısının 2nHn – n + Hn olduğunu gösterin. Özellikle,
Teorem 11.3’ün kanıtında verilen analizden daha dikkatli analiz
edin.
Alıştırma 11.8. Yığın-sıralamanın, en az 2n log n – O(n) karşılaştırma gerçekleştirmesine neden olan bir girdi dizisi tanımlayın. Cevabınızı doğrulayın.
Alıştırma 11.9. Bu bölümde tanıtılan yığın-sıralama uygulaması,
elemanlarını ters sırada sıralıyor, ve daha sonra diziyi tersine çeviriyor. Bu son adımdan kaçınmak için, girdi Karşılaştırıcı’sı, c’nin
sonucunu olumsuzlayan, yeni bir Karşılaştırıcı tanımlanabilir. Bunun, neden iyi bir optimizasyon olmadığını açıklayın (İpucu: Diziyi
tersine çevirmenin maliyeti ile, kaç adet olumsuzlama gerçekleştirilmesinin maliyetini kıyaslayın).
Alıştırma 11.10. Şekil 11.6’deki karşılaştırma ağacı tarafından
doğru sıralanmayan, bir başka 1, 2, 3 permütasyon çiftini bulun.
Alıştırma 11.11. log n! = n log n – O(n) olduğunu kanıtlayın.
| 399
Alıştırma 11.12. k yapraklı ikili ağacın yüksekliğinin en az log k
olduğunu kanıtlayın.
Alıştırma 11.13. k yapraklı ikili ağaçtan rasgele bir yaprak seçersek, bu yaprağın beklenen yüksekliğinin en az log k olduğunu kanıtlayın.
Alıştırma 11.14. Bu bölümde tanıtılan radixSort(a, k) uygulaması
girdi, a dizisi, sadece negatif olmayan tamsayıları içerdiği zaman
çalışır. a, hem negatif ve hem de negatif olmayan tamsayıları içerdiğinde, uygulamanın düzgün çalışması için gerekli değişiklikleri
yapın.
400|
| 401
Bölüm 12
Grafikler
Bu bölümde, grafiklerin iki gösterimini ve bu gösterimleri kullanan
temel algoritmaları tanıtacağız.
Matematiksel olarak, (yönlü) grafik bir G = (V, E) çiftidir. Burada,
V,
köşelerden oluşan bir küme, E, kenarlar adıyla belirtilen sıralı
köşe çiftlerinden oluşan bir kümedir. (i, j) kenarının yönü i’den
j’ye
doğrudur; i, kenarın kaynağı, ve j, hedef olarak adlandırılır.
v0,…,vk
köşelerinden oluşan bir dizi, G üzerinde bir yoldur, öyle ki
her i
{1,…,k}
için (vi-1, vi) kenarı E kümesinin elemanıdır. Eğer,
buna ek olarak, (vk, v0) kenarı da E’nin elemanıysa v0,…,vk yolu bir
döngüdür. Eğer tüm köşeleri benzersiz ve tekil ise, yol (veya döngü) basittir. Herhangi bir vi köşesinden, herhangi bir vj köşesine yol
varsa, vj’nin vi’dan ulaşılabilir olduğunu söyleriz. Şekil 12.1 bir
grafik örneğini göstermektedir.
Birçok fenomeni modelleme yetenekleri nedeniyle, grafiklerin büyük sayıda uygulamaları vardır. Çok belirgin örnekler vardır. Bilgisayar ağları, köşeleri bilgisayarlar olan ve kenarları bu bilgisayarlar
arasındaki (yönlü) iletişim bağlantıları olan grafikler halinde modellenebilir. Şehir sokakları grafik olarak modellenebilir, köşeler
402|
kavşaklar ile temsil edilirken, kenarlar ardışık kavşakları birleştiren
sokakları gösterir.
Daha az belirgin örnekler, bir küme içindeki herhangi ikili ilişkileri
grafikler ile modelleyebileceğimizi fark ettiğimizde ortaya çıkar.
Örneğin, bir üniversite ortamında, bir ders programı çatışma grafiği
oluşturulabilir, burada köşeler üniversitede açılan dersleri temsil
ederken, hem sınıf i ve hem sınıf j’yi alan en az bir öğrenci varsa,
(i, j)
kenarı grafikte yer alır. Böylece, bir kenar, i sınıfı için düzen-
lenecek bir sınavın, aynı saatte j sınıfı için düzenlenmeyeceğine
işaret eder.
Bu bölüm boyunca, G köşe sayısını göstermek için, n, ve G kenar
sayısını göstermek için, m kullanacağız. Yani,
ve
.
Ayrıca, V = {0,…,n – 1} olduğunu varsayacağız. V elemanları ile
| 403
ilişkilendirmek istediğimiz başka bir veri, n uzunluğunda bir dizide
depolanabilir.
Grafikler üzerinde gerçekleştirilen bazı yaygın işlemler şunlardır:
addEdge(i, j)
removeEdge(i, j) : (i, j)
hasEdge(i, j)
outEdges(i)
: (i, j) kenarını E’ye ekler.
kenarını E’den siler.
: Kenar (i, j) E olup olmadığını kontrol eder.
: (i, j) E olan tüm j tamsayılarının bir Liste’sini
döndürür.
inEdges(i)
: (j, i) E olan tüm j tamsayılarının bir Liste’sini
döndürür.
Bu işlemleri verimli uygulamanın çok zor olmadığını unutmayın.
Örneğin, ilk üç işlem, Sırasız Küme kullanılarak doğrudan uygulanabilir, bu nedenle, Bölüm 5’te tartışılan karma tabloları kullanılarak, sabit beklenen zamanda çalışır. Son iki işlem, her bir köşe için,
ona bitişik köşelerin bir listesini depolayarak, sabit zamanda uygulanabilir.
Ancak, bu işlemler için, farklı grafik uygulamalarının, farklı performans gereksinimleri vardır ve ideal olarak en basit gerçekleştirimi uygulamanın tüm gereksinimini karşılayacak şekilde kullanmalıyız. Bu nedenle, grafik gösterimlerini iki geniş kategoride tartışıyoruz.
404|
Bitişiklik Matrisi: Bir Grafiğin Matris ile
Gösterimi
Bitişiklik matrisi, n köşeli bir G = (V, E) grafiğini, elemanları
boolean
değerler alan bir n x n matrisi ile gösterir.
Matris elemanı a[i][j],
olarak tanımlanır. Şekil 12.1’deki grafik için bitişiklik matrisi, Şekil 12.2’de gösterilmiştir.
Bu gösterimde, addEdge(i, j), removeEdge(i, j), ve hasEdge(i, j)
işlemleri, a[i][j] elemanını sadece belirlemeyi veya okumayı içerir:
| 405
Bu işlemler, işlem başına açıkça sabit zaman alır.
Bitişiklik
outEdges(i)
a’nın
matrisinin
kötü
performans
sergilediği
yerler,
ve inEdges(i) işlemleridir. Bunları uygulamak için,
karşılık gelen satır veya sütunundaki bütün n elemanlarını
taramalıyız ve sırasıyla a[i][j] ve a[j][i]’nin true değer aldığı tüm j
endekslerini toplamalıyız.
406|
| 407
Bu işlemler, işlem başına açıkça O(n) çalışma zamanı alır.
Bitişiklik matrisi gösteriminin başka bir dezavantajı büyük olmasıdır. n x n boolean matrisini depolaması nedeniyle en az n2 bit bellek gerektirir. Buradaki uygulama boolean değerlerden oluşan bir
matris kullanıyor, bu nedenle, gerçekte n2 bayt büyüklüğünde belleği kullanıyor. w boolean değeri her bir bellek sözcüğünün içinde
tutan daha dikkatli bir uygulama, alan kullanımını O(n2/w) bellek
sözcüğüne kadar azaltabilir.
Teorem 12.1. Bitişiklik Matrisi veri yapısı, Grafik arayüzünü uygular. Bitişiklik Matrisi aşağıdaki işlemleri destekler:
İşlem başına sabit zamanda çalışan addEdge(i, j),
removeEdge(i, j), hasEdge(i, j)
İşlem
başına
O(n)
zamanda
outEdges(i).
2
Bitişiklik Matrisi O(n )
ve,
alan kullanır.
çalışan
inEdges(i),
408|
Yüksek bellek gereksinimlerine ve inEdges(i) ve outEdges(i) işlemlerinin kötü performansına rağmen, Bitişiklik Matrisi hala bazı
uygulamalarda kullanışlı olabilir. Özellikle, G grafiği yoğunsa, yani
kenar sayısı n2’ye yakınsa, o zaman n2 bellek kullanımı kabul edilebilir.
Bitişiklik Matrisi
veri yapısı, aynı zamanda yaygın olarak kullanıl-
maktadır, çünkü G grafiğinin özelliklerini verimli hesaplamak için
a
matrisi üzerindeki cebirsel işlemleri kullanabilirsiniz. Bu konu
algoritmalar dersi içeriğinde yer alabilir, ancak burada şöyle bir
özelliğe dikkat çekeceğiz: a’nın girdilerini tamsayı olarak kabul
edersek (true için 1, ve false için 0), ve matris çarpımıyla a’yı
kendisi ile çarparsak, a2 matrisini elde ederiz. Matris çarpımı tanımından hatırlamalısınız ki,
Bu toplamı, G grafiği açısından yorumlarsak, bu formül köşe sayısını, k, sayar. Burada, G, hem (i, k) ve hem (k, j) kenarlarını içermelidir. Yani, k, ara köşeleri üzerinden, i’den j’ye uzunluğu tam
olarak iki olan yol sayısını sayar. Bu gözlem, sadece O(log n) matris çarpımı kullanır, ve G’nin bütün köşe çiftleri arasındaki en kısa
yolları hesaplayan bir algoritmanın temelidir.
| 409
Bitişiklik Listeleri: Liste Derlemi
olarak Grafik
Grafiklerin bitişiklik listesi ile gösterimleri daha köşe-merkezli bir
yaklaşım alır. Bitişiklik listelerinin birçok olası uygulamaları vardır. Bu bölümde, basit bir tanesini tanıtacağız. Bölümün sonunda,
farklı olasılıkları tartışacağız. Bitişiklik listeleri gösteriminde,
G = (V, E)
grafiği bir liste dizisi, adj, halinde temsil edilir. adj[i]
listesi, i köşesine bitişik tüm köşelerin bir listesini içerir. Yani, (i, j)
E olan
her j endeksini içerir.
Şekil 12.3 bir örneği gösteriyor. Bu özel uygulamada, adj içindeki
her listeyi bir Dizi Yığıt olarak temsil ediyoruz, çünkü konuma göre
erişim için sabit çalışma zamanı istiyoruz. Diğer seçenekler de
mümkündür. Özellikle, bir Çifte Bağlantılı Liste olarak da adj’i
uygulayabilirdik.
410|
addEdge(i, j)
işlemi, adj[i] listesine j değerini sadece ekler:
| 411
Bu sabit zaman alır.
removeEdge(i, j)
işlemi, adj[i] listesinde j değerini bulana kadar
arar, ve bulduğunda siler:
Bu, O(deg(i)) zaman alır, burada deg(i), (i’nin derecesi) E içinde
kaynağı i olan kenar sayısını sayar.
hasEdge(i, j)
işlemi de benzerdir; adj[i] listesinde j değerini bulana
kadar arar (ve true döndürür), veya listenin sonuna ulaşır (ve false
döndürür):
412|
Bu, O(deg(i)) zaman alır.
outEdges(i)
işlemi çok basittir; adj[i] listesini döndürür:
Bu, açıkça, sabit zaman alır.
inEdges(i)
işlemi, çok daha fazla iş gerektirir. Her j köşesi üzerin-
den tarayarak, (i, j) kenarının bulunup bulunmadığını kontrol eder,
ve eğer bulduysa, j’yi çıktı listesine ekler:
Bu işlem çok yavaştır. Her köşenin bitişiklik listesini tarar, bu nedenle O(n + m) zaman alır.
Aşağıdaki teorem yukarıdaki veri yapısının performansını özetlemektedir:
Teorem 12.2. Bitişiklik Listeleri veri yapısı, Grafik arayüzünü uygular. Bitişiklik Listeleri aşağıdaki işlemleri destekler:
| 413
İşlem başına sabit zamanda çalışan addEdge(i, j);
İşlem başına O(deg(i)) zamanda çalışan removeEdge(i, j)
ve hasEdge(i, j);
İşlem başına sabit zamanda çalışan outEdges(i); ve
İşlem başına O(n + m) zamanda çalışan inEdges(i).
Bitişiklik Listeleri O(n + m)
alan kullanır.
Daha önce değindiğimiz gibi, bir grafiği bitişiklik listesi halinde
uygularken, karar verilmesi gereken pek çok farklı seçenek vardır.
Öne çıkan bazı sorular şunları içermektedir:
Her adj elemanını depolamak için ne tür bir derlem kullanılmalıdır? Bir dizi-tabanlı liste, bir bağlantılı liste, hatta bir
karma tablosu kullanılabilir.
İkinci bir bitişiklik listesi, inadj, olmalı mıdır? Bu liste, her i
köşesi için, (j, i) E olan j köşe listesini depolar. Böylece,
inEdges(i)
işleminin çalışma zamanı büyük ölçüde azaltıla-
bilir, ancak kenarları eklerken veya silerken biraz daha fazla
iş gerektirir.
adj[i]
içindeki (i, j) kenarı, inadj [j] içinde kendisine karşı-
lık gelen girdiye bir referansla bağlanmalı mıdır?
Kenarlar kendilerine ilişkili verileri ile birinci sınıf nesneler
olmalı mıdır? Bu şekilde, adj, köşe (tamsayı) listesini değil,
kenar listesini içerecektir.
414|
Bu soruların çoğu uygulamanın karmaşıklığı (ve alan gereksinimi)
ile uygulamanın performans özellikleri arasında bir tercihte bulunmayı beraberinde getirir.
| 415
Grafik Ziyaretleri
Bu bölümde, bir grafiği incelemek için, grafiğin köşelerinden biri
olan, i köşesinden başlayarak, i’den ulaşılabilir bütün köşeleri bulan
iki algoritma tanıtacağız. Bu algoritmaların ikisi de, bitişiklik listesi
gösterimini kullanan grafikler için uygundur. Bu nedenle, bu algoritmaları analiz ederken, Bitişiklik Listeleri gösterimini temel olarak
varsayacağız.
416|
Enine-Arama
Enine-arama algoritması, i, köşesinden başlar ve ilk olarak, i’nin
komşularını ziyaret eder, sonra i’nin komşularının komşularını ziyaret eder, sonra i’nin komşularının komşularının komşularını ziyaret eder, vb.
Bu algoritma, ikili ağaçlar için enine-arama algoritmasının (bkz.
İkili Ağaçta Sıralı-Düğüm Ziyaretleri Bölümü) bir genellemesidir
ve çok benzerdir; başlangıçta sadece i’yi içeren, q kuyruğunu kullanır. Sonra q’dan bir eleman çıkarır ve komşularını daha önceden
eklenmediyse q’ya ekler. Bunu tekrarlayarak defalarca yapar. Enine-arama algoritmasının grafik versiyonu ile ağaç versiyonu arasındaki tek büyük fark, grafik algoritmasının q köşesini birden fazla
kere eklememesidir. Bunu sağlamak için, hangi köşelerin incelenmiş olduğunu tutan bir yardımcı boolean dizi, seen, kullanılır.
| 417
Şekil 12.1’deki grafik üzerinde, bfs(g, 0) çalıştırılmasına bir örnek,
Şekil 12.4’de gösterilmiştir. Bitişiklik listelerinin sırasına bağlı
olarak, farklı çalıştırmalar mümkündür; Şekil 12.4, Şekil 12.3’teki
bitişiklik listelerini kullanmaktadır.
bfs(g, i)
yordamının çalışma zamanını analiz etmek oldukça basit-
tir. seen dizisinin kullanılmasıyla, hiçbir köşe q’ya birden fazla
kere eklenmeyecektir. q’ya bir köşe eklemek (ve sonra silmek) köşe başına sabit zaman alır, bu O(n) toplam zaman eder. Her bir
köşe, iç döngü tarafından, en fazla bir defa işlendiği için, her bitişiklik listesi, en fazla bir kere işlenir, yani G’nin her kenarı en fazla
bir defa işlenir. İç döngü içinde yapılan bu işlem, yineleme başına
sabit zaman alır, bu O(m) toplam zaman eder. Bu nedenle, algoritmanın tamamı O(n + m) zamanda çalışır.
418|
Aşağıdaki teorem bfs(g, r) algoritmasının performansını özetlemektedir.
Teorem 12.3. Bitişiklik Listeleri veri yapısını kullanan bir g Grafik
girdisi için, bfs(g, r) algoritması O(n+m) zamanda çalışır.
Enine-aramanın çok özel bazı özellikleri vardır. bfs(g, r) çağrısı,
r’den j’ye
yönlü bir yolu olan her j köşesini, eninde sonunda kuy-
ruğa ekler (ve sonunda kuyruktan siler). Ayrıca, r’ye 0 mesafesindeki köşeler (yani, r’nin kendisi), 1 mesafesindeki köşelerden önce
q’ya
eklenecektir. 1 mesafesindeki köşeler, 2 mesafesindeki köşe-
lerden önce q’ya eklenecektir, vb. Bu nedenle, bfs(g, r) işlemi, r’ye
olan mesafesi artan sırada olacak şekilde köşeleri ziyaret eder, ve r
tarafından ulaşılamayan köşeleri ziyaret etmez.
Enine-arama algoritmasının özellikle yararlı bir uygulaması, bu
nedenle, en kısa yolları hesaplamaktır. r’den diğer her köşeye en
kısa yolu hesaplamak için bfs(g, r) yordamının bir varyasyonunu
kullanıyoruz. Bu kod, n uzunluğunda bir p yardımcı dizisi kullanır.
Yeni bir j köşesi, q’ya eklendiğinde, p[j] = i olarak belirleriz. Bu
şekilde, r’den j’ye giden en kısa yol üzerindeki ikinci son düğüm
p[j]
olur. r’den j’ye giden en kısa yolu (tersine) yeniden kurmak
için bunu tekrarlarız, p[p[j], p[p[p[j]]], vb.
| 419
Derinliğine Arama
Derinliğine-arama algoritması ikili ağaçları inceleyen standart algoritmaya benzer; geçerli düğüme dönmeden önce altağaçlardan
birini tamamen incelemeyi bitirir, ve sonra başka bir altağacı araştırır. Derinliğine-arama, enine-aramayla bir fark dışında benzeşir,
kuyruk yerine yığıt kullanır.
Derinliğine-arama algoritmasının çalışması sırasında, her i köşesine, bir renk, c[i] atanır: Daha önce köşeyi görmemişsek white (beyaz), şu anda bu köşeyi ziyaret ediyorsak gray (gri), ve bu köşeyi
ziyaret etmeyi bitirdiysek black (siyah). Derinliğine-aramayı düşünmenin en kolay yolu, onu bir özyinelemeli algoritma olarak
düşünmektir. r köşesini ziyaret ederek başlarız. i köşesini ziyaret
ederken, i’yi gri olarak işaretleriz. Sonra, i’nin bitişiklik listesini
tararız ve bu listede bulduğumuz herhangi bir beyaz köşeyi özyinelemeli olarak ziyaret ederiz. Sonunda, i’yi işlemeyi tamamladığımızda, i’yi siyah renkle işaretleriz ve dönüş sağlarız.
420|
Şekil 12.5 bu algoritmanın çalışmasına bir örnek gösteriyor.
Derinliğine-arama en iyi şekilde özyinelemeli olarak düşünülse de,
özyineleme bunu uygulamak için en iyi yol değildir. Nitekim, yukarıda verilen kod, birçok büyük grafik için yığıt taşmasına yol
| 421
açarak başarısız olacaktır. Alternatif bir uygulama, açık bir yığıt
olan, s’in, özyineleme yığıtının yerine geçmesidir. Aşağıdaki uygulama tam olarak bunu yapar:
Yukarıdaki kodda, bir sonraki i köşesi işlendiği zaman, i, gri renge
boyanır ve sonra, yığıt üzerinde, bitişik köşeler ile yer değiştirir.
Sonraki yineleme sırasında, bu köşelerden biri ziyaret edilecektir.
Beklendiği gibi, dfs(g, r) ve dfs2(g, r) çalışma zamanları bfs(g, r)
ile aynıdır:
Teorem 12.4. Bitişiklik Listeleri veri yapısı kullanan g Grafik girdisi için, dfs(g, r) ve dfs2(g, r) algoritmalarının her biri O(n + m)
zamanda çalışır.
Enine-arama algoritmasında olduğu gibi, derinliğine-aramanın her
çalıştırması ile ilişkili altta yatan bir ağaç vardır. i r olan bir dü-
422|
ğüm, beyazdan griye renk değiştirdiğinde, bunun nedeni, bir i’ düğümünü işlerken özyinelemeli olarak dfs(g, i, c) yönteminin çağrılmasıdır (dfs2(g, r) algoritması için, yığıtta i’ düğümünün yerini
alan düğümlerden biri i’dir). Eğer i babası i’ ise, o zaman r kökenli
bir ağaç elde ederiz. Şekil 12.5’te bu ağaç köşe 0’dan köşe 11’e
giden bir yoldur.
Derinliğine-aramanın önemli bir özelliği şudur: Varsayalım ki, i
düğümü gri renklendirildiğinde, i’den diğer bazı j düğümü için sadece beyaz köşeleri kullanan bir yol vardır. O zaman, j ilk olarak
gri
renkli olacak, sonra i siyah olmadan önce siyah renkli olacaktır
(i’den j’ye herhangi bir, P yolunu dikkate alan çelişki yöntemi ile
kanıtlanabilir).
Bu özelliğin bir uygulaması, döngülerin saptanmasıdır. Şekil
12.6’ya bakın. r’dan ulaşılabilir bir, C döngüsünü düşünün. i, C'nin
ilk gri renkli düğümü olsun, ve C döngüsü üzerinde i’den önce gelen düğüm j olsun.
| 423
Sonra, yukarıda belirtilen özellikle, j gri renkli olacak ve i hala gri
iken (j, i) kenarı algoritma tarafından dikkate alınacaktır. Bu nedenle, derinliğine-arama ağacında i’den j’ye bir yol, P, olduğu ve
(j, i)
kenarının bulunduğu sonucuna varılabilir. Bu nedenle, P de
bir döngüdür.
424|
Tartışma ve Alıştırmalar
Derinliğine-arama ve enine-arama algoritmalarının çalışma zamanları Teorem 12.3 ve 12.4 tarafından biraz büyütülmüştür. nr, r’dan i
için bir yol bulunan G’nin köşe sayısı olsun. mr bu köşeleri kaynak
olarak alan kenar sayısını belirtsin. O zaman, aşağıdaki teorem enine-arama ve derinliğine-arama algoritmalarının çalışma zamanlarını daha kesin bir ifadeyle vermektedir (Bu daha gelişmiş ifade, alıştırmalarda hazırlanan bazı algoritmaların uygulamalarında yararlı
olacaktır).
Teorem 12.5. Bitişiklik Listeleri veri yapısı kullanan g Grafik girdisi için, bfs(g, r), dfs(g, r) ve dfs2(g, r) algoritmalarının her biri
O(nr + mr) zamanda çalışır.
Enine-arama Moore [52] ve Lee [49] tarafından, sırasıyla, labirent
keşif ve devre yönlendirme bağlamlarında bağımsız olarak keşfedilmiştir.
Grafiklerin Bitişiklik Listesi gösterimleri, Hopcroft ve Tarjan [40]
tarafından, (o zaman daha yaygın olan) Bitişiklik Matrisi gösterimine bir alternatif olarak tanıtıldı. Bu gösterim, derinliğine-arama ile
birlikte, ünlü Hopcroft-Tarjan düzlemsellik test algoritmasında
önemli bir rol oynadı. Bu algoritma ile, O(n) zamanda, hiçbir kenar
çifti birbirini kesmeyecek şekilde bir grafiğin [41] düzlemde çizilip
çizilemeyeceğini belirleyebilirsiniz.
| 425
Aşağıdaki alıştırmalarda, her i ve j için (i, j) kenarı, ancak ve ancak
(j, i)
kenarı mevcutsa bulunan bir grafiğe yönsüz grafik denir.
Alıştırma 12.1. Şekil 12.7’de gösterilen grafiğin Bitişikliklik Listesi
gösterimini ve Bitişiklik Matrisi gösterimini çizin.
Alıştırma 12.2. G grafiğinin yük matrisi gösterimi, aşağıdaki gibi
A
ile tanımlanan n x m matristir:
426|
1. Şekil 12.7’de gösterilen grafiğin yük matrisi gösterimini çizin.
2. Bir grafiğin yük matrisi gösterimini tasarlayın, analiz edin ve
uygulayın. addEdge(i, j), removeEdge(i, j), hasEdge(i, j),
inEdges(i),
ve outEdges(i) alan gereksinimini ve çalışma zamanla-
rını analiz ettiğinizden emin olun.
Alıştırma 12.3. Şekil 12.7’deki G grafiği üzerinde bfs(G, 0) ve
dfs(G, 0)
çalıştırmasını gösterin.
Alıştırma 12.4. G yönsüz grafik olsun. Her i, j köşe çifti için i’den
j’ye
bir yol varsa (G yönsüz grafik olduğu için j’den i’ye de bir yol
vardır) G grafiği bağlı bir grafiktir. G’nin bağlı olup olmadığını,
O(n + m) zamanda nasıl test edeceğinizi gösterin.
Alıştırma 12.5. G yönsüz grafik olsun. G’nin bağlı-bileşen etiketlemesi G köşelerini en büyük kümeler halinde bölümlere ayırır.
Bunların her biri, bağlı birer altgrafiktir. G’nin bağlı-bileşen etiketlemesini, O(n+m) zamanda nasıl hesaplayacağınızı gösterin.
Alıştırma 12.6. G yönsüz grafik olsun. G’yi kapsayan orman, bileşen başına, G kenarlarından ve G’nin bütün köşelerinden oluşan bir
ağaç topluluğudur. G’yi kapsayan ormanı, O(n + m) zamanda nasıl
hesaplayacağınızı gösterin.
Alıştırma 12.7. G grafiğinin her i, j köşe çifti için i’den j’ye bir yol
varsa kuvvetli-bağlı olduğu söylenir. G’nin kuvvetli-bağlı olup olmadığını, O(n + m) zamanda nasıl test edeceğinizi gösterin.
| 427
Alıştırma 12.8. G = (V, E) grafiği, ve bir özel köşesi, r
r’dan i’ye
giden en kısa yolun uzunluğunu, her i
V
V
için,
köşesi için,
nasıl hesaplayacağınızı gösterin.
Alıştırma 12.9. dfs(g, r) kodunun grafik düğümlerini ziyaret etmesine (basit) bir örnek verin. Bu örnekte, düğümler dfs2(g, r)’den
farklı bir sırada ziyaret edilmelidir. Düğümleri tam olarak dfs(g, r)
ile aynı sırada ziyaret eden dfs2(g, r)’in bir versiyonunu yazın
(İpucu: r birden fazla kenar için kaynak iken, her iki algoritmanın
da grafik üzerinde çalışmasını izleyin).
Alıştırma 12.10. G grafiğinde evrensel çıkış düğümü, n – 1 kenarın
hedefi olan, ancak hiçbir kenara kaynak olmayan bir köşedir. Bitişiklik Matrisi
ile gösterilen bir G grafiğinin, evrensel çıkış düğümü-
nün var olup olmadığını test eden bir algoritma tasarlayın ve uygulayın. Algoritmanız O(n) zamanda çalışmalıdır.
428|
| 429
Bölüm 13
Tamsayılar için Veri Yapıları
Bu bölümde, Sıralı Küme’nin uygulanması problemine geri dönüyoruz. Şu anki fark, Sıralı Küme’de depolanan elemanların w-bit
tamsayılar olarak varsayılmasıdır. Yani, x
le(x), sil(x),
{0, 2
w
– 1}
için ek-
ve bul(x) işlemlerini uygulamak istiyoruz. Pek çok
uygulama için verinin – veya en azından veri sıralamak için kullandığımız anahtarın – tamsayı olduğunu düşünmek zor olmayacaktır.
Fikirleri bir öncekinin üzerine kurulu üç veri yapısını tartışacağız.
İlk yapı, İkili Sıralı Ağaç, her zaman Sıralı Küme işlemlerinin üçünü de, O(w) zamanda gerçekleştirir. Bu çok etkileyici değildir,
çünkü {0,…,2w – 1} içinden herhangi bir alt küme n ≤ 2w boyutuna sahiptir, ve böylece log n ≤ w. Bu kitapta tartışılan diğer bütün Sıralı Küme uygulamalarının tüm işlemleri O(log n) zamanda
çalışır, bu nedenle en azından bir İkili Sıralı Ağaç kadar hızlıdır.
İkinci yapı X-Hızlı Sıralı Ağaç, karmayı kullanarak İkili Sıralı Ağaç
içinde yapılan aramayı hızlandırır. Bu hızlandırmayla, bul(x) işlemi
O(log w) zamanda çalışır. Ancak, ekle(x) ve sil(x) işlemleri, hala
X-Hızlı Sıralı Ağaç
O(n . w) olur.
içinde O(w) zaman alır, ve kullanılan alan
430|
Üçüncü yapı Y-Hızlı Sıralı Ağaç, her w elemanı içinden sadece bir
örneği depolamak için X-Hızlı Sıralı Ağaç’ı kullanır, ve kalan elemanları standart bir Sıralı Küme yapısında depolar. Böylece ekle(x)
ve sil(x) çalışma zamanı O(log w) ve alan gereksinimi
O(n)’ye kadar azalır.
Bu bölümde örnek olarak kullanılan uygulamalar, bir tamsayı ile
ilişkili her türlü veri türünü depolayabilir. Kod örneklerinde, ix
değişkeni, her zaman x tamsayı değeri ile ilişkilidir, ve
in.intValue(x)
yöntemi, x ile ilişkili tamsayıyı dönüştürüyor.
| 431
İkili Sıralı Ağaç: Sayısal Arama Ağacı
İkili Sıralı Ağaç, w-bit
tamsayılardan oluşan bir kümeyi ikili ağaç
içine kodlar. Ağaçtaki tüm yapraklar w derinliğindedir ve her tamsayı kökten-yaprağa giden bir yol olarak kodlanmıştır. i’nci en anlamlı bit, 0 ise, x tamsayısı için yol i seviyesinde sola doğru döner.
1
ise sağa döner. Şekil 13.1, w = 4 durumu için, 3 (0011),
9 (1001), 12 (1100), 13 (1101)
tamsayılarının depolandığı örnek
bir ağacı gösteriyor.
x
değeri için arama yolu, x bitlerine bağlı olduğu içindir ki, bir u
düğümünün çocuklarını, u.child[0] (sol) ve u.child[1] (sağ) olarak
isimlendirmek yararlı olacaktır. child olarak adlandırılan bu işaretçilerin birden çok fonksiyonu vardır. İkili Sıralı Ağaç’ın yapraklarında çocuk olmadığı için, işaretçilerin fonksiyonu yaprakları bir
Çifte-Bağlantılı Liste (ÇBListe)
Sıralı Ağaç
halinde bir araya getirmektir. İkili
içindeki bir yaprak için, u.child[0] (prev), listede u’dan
önce gelen düğümdür. u.child[1] (next) listede u’dan sonra gelen
düğümdür. Özel bir düğüm, dummy, hem ilk düğümün öncesinde,
hem son düğümün sonrasında kullanılır (bkz. ÇBListe: ÇifteBağlantılı Liste Bölümü).
Her, u, düğümü ayrıca u.jump adında bir ek işaretçi içerir. u düğümünün
solundaki
çocuğu
mevcut
değilse,
u.jump,
u
altağacındaki en küçük yaprağa işaret eder. Sağındaki çocuk mev-
432|
cut değilse, u.jump, u altağacındaki en büyük yaprağa işaret eder.
jump
işaretçilerini gösteren bir İkili Sıralı Ağaç örneği ve yaprakla-
rı Çifte-Bağlantılı Liste halinde Şekil 13.2’de gösterilmiştir.
İkili Sıralı Ağaç’ta bul(x)
işlemi oldukça kolaydır. Arama yolunun
başlangıcında, u düğümleri arasından x yaprağı aranır. Eğer öyleyse, x bulunmuş olarak hesaplanır. u düğümünden öteye gidilemezse, (x’in çocuğu yoksa, yani yaprağa ulaşıldıysa), u.jump yolu aranır. Bu arama, bizi x’den büyük en küçük yaprağa, veya x’den küçük en büyük yaprağa götürür. Bu iki durumdan, hangisinin önce
oluşacağını, u düğümünün sol çocuğunun mu, sağ çocuğunun mu,
sırasıyla, eksik, veya var olmasına bağlayabiliriz. Birinci durumda
(u’nun sol çocuğu eksik), istediğimiz düğüm bulunmuş olur. İkinci
durumda (u’nun sağ çocuğu eksik), istediğimiz düğüme ulaşmak
için bağlantılı listeyi kullanabiliriz. Bu durumların her biri, Şekil
13.3’te gösterilmiştir.
| 433
bul(x)
işleminin çalışma zamanı, kökten yaprağa aldığı yol ile be-
lirlenir, bu nedenle O(w) zamanda çalışır.
İkili Sıralı Ağacı’nda ekle(x)
işlemi kolay, ancak oldukça zahmetli-
dir:
1. Arama yolu üzerinde u düğümü için, ulaşılabilen son düğüme kadar arama yapılır.
2. u düğümünden başlayarak, arama yolunun kalanı için, x içeren bir yaprağa kadar arama yolu kaydedilir.
3. x içeren bir u’ düğümü oluşturularak bağlantılı yaprak listesine eklenir (Birinci adımda en son ziyaret edilen, u düğümüne ait olan jump işaretçisinin gösterdiği bağlantılı listenin içinden u’ öncesine, pred, erişim sağlar).
434|
4. x arama yolu üzerinde geri yürüyerek, şimdi x’i gösteren
jump
işaretçilerinin bulunduğu düğümlerde jump işaretçile-
ri ayarlanır.
Şekil 13.4 örnek bir ekleme çalıştırmasını gösteriyor.
Bu işlemin çalıştırılması sırasında, x için önce ileri, sonra geri yönde birer arama yolu bulunuyor. Bu yürüyüşlerin her iki adımı da
sabit zamanda çalışır, bu nedenle ekle(x) işlemi O(w) zamanda
çalışır.
| 435
436|
sil(x)
işlemi ekle(x) işini geri alır. ekle(x) gibi, yapması gereken
pek çok iş vardır:
| 437
1. x için arama yolu üzerinden x içeren u yaprağına ulaşana
kadar arar.
2. Çifte-bağlantılı listeden u’yu siler.
3. u silindikten sonra, x için arama yolu üzerinde olmayan bir
çocuğa sahip v düğümüne ulaşılana kadar arama yolu ardı
sıra silinir.
4. u’ya işaret veren her jump işaretçisini güncellemek için
başlangıcı v, sonu kök olan yeni bir yol oluşturulur.
Şekil 13.5 örnek bir silme çalıştırmasını gösteriyor.
Teorem 13.1. İkili Sıralı Ağaç, w-bit tamsayılar için Sıralı Küme
arayüzünü uygular. İkili Sıralı Ağaç, işlem başına O(w) zamanda
çalışan, ekle(x), sil(x), ve bul(x) işlemlerini destekler. n değer depolayan İkili Sıralı Ağacı O(n . w) alan kullanır.
438|
| 439
X-Hızlı Sıralı Ağaç: Çifte-Logaritmik
Zamanda Arama
İkili Sıralı Ağaç
yapısının performansı çok etkileyici değildir. Veri
yapısında depolanan eleman sayısı, n, en çok 2W olur, bu nedenle
log n ≤ w
yazılabilir. Diğer bir deyişle, bu kitabın diğer bölümle-
rinde tanıtılan, karşılaştırmaya-dayalı Sıralı Küme yapılarının herhangi biri, en az İkili Sıralı Ağaç’lar kadar verimlidir, ve sadece
tamsayıları depolamakla sınırlı değildir.
Bu bölümde X-Hızlı Sıralı Ağaç yapısı tanıtılıyor. Bu yapının her
seviyesinde, birer w + 1 karma tabloya sahip İkili Sıralı Ağacı bulunmaktadır. Bu karma tablolar, bul(x) işleminin O(log w) zamanda çalışması için, hızlandırma amaçlı kullanılır. Hatırlayın ki, İkili
Sıralı Ağaç’ta bul(x)
u
işlemi, x için bir arama yolu üzerinde, öyle bir
düğümüne ulaştığımız zaman tamamlanmalıdır ki, u.right (veya
u.left)
üzerinden ilerlemek istediğimizde, u’nun sağ (sırasıyla, sol)
çocuğunu bulamamalıyız. Bu noktada, arama, u.jump yardımıyla,
İkili Sıralı Ağacı’nın
bir, v yaprağına atlamalıdır, ve v’yi, veya yap-
rakları depolayan bağlantılı-listede, v’den sonra gelen düğümü
döndürmelidir. X-Hızlı Sıralı Ağaç, ağaç seviyeleri üzerinde ikili
aramayı çalıştırarak, u düğümünü bulmak için geçen arama sürecini
hızlı hale getirir.
İkili aramayı kullanmak için, aradığımız u düğümünün belirli bir i
seviyesinin üstünde mi, yoksa i seviyesinde veya altında mı sorusu-
440|
nu karara bağlamamız lazımdır. Bu bilgi, x’in ikili gösteriminde en
önemli i biti ile verilmektedir; bu bitler kökten i’nci seviyeye x’i
taşıyan arama yolunu belirler. Örneğin, bkz. Şekil 13.6. Bu şekil
üzerinde, 14 için (ikili gösterimi 1110) arama yolunun son düğümü, u, 2.seviyede
ile etiketlenmiştir, çünkü 3.seviyede
ile etiketli herhangi bir düğüm yoktur. Böylece, i seviyesinde
bulunan her düğümü, i-bitlik bir tamsayı ile etiketleyebiliriz.
x’nin
en önemli i-bitinden oluşan etikete sahip bir düğüm, ancak ve
ancak, i seviyesinde bulunuyorsa, aradığımız u düğümü, i seviyesinde veya altında yer alır.
Her i
{0,…,w}
için, X-Hızlı Arama Ağacı’nın i seviyesinde bulu-
nan bütün düğümlerini, bir Sırasız Küme içinde depolarız. Bu Sırasız Küme,
karma tablo olarak uygulanan t[i] ile verilmiştir (bkz.
Bölüm 5). x’in en önemli i-biti ile etiketlenmiş bir düğümün i sevi-
| 441
yesinde var olup olmadığını kontrol etmemize olanak tanır. Bu
kontrolü beklenen sabit zamanda gerçekleştiririz. Gerçekte bu düğümü, t[i].bul(x
t[0]…t[w]
(w – i))
kullanarak da bulabiliriz.
karma tabloları, ikili aramayı kullanarak, u’yu bulmamı-
za olanak tanır. Başlangıçta, u’nun 0 ≤ i
w+1
için bazı i seviye-
sinde olduğunu biliyoruz. Bu nedenle, l = 0 ve h = w + l ile başlıyoruz, ve
bakıyoruz. Eğer
olan
t[i], x’in
t[i]
karma tablosuna tekrar tekrar
en önemli i-biti ile etiketli bir düğümü
içeriyorsa, l = i olarak belirleriz (u, i seviyesinde veya altındadır);
aksi takdirde, h = i olarak belirleriz (u, i seviyesinin üstündedir). h
– l ≤ 1
koşulu, bu işlemi sonlandırır, çünkü l seviyesinde u’nun
yeri belirlenmiştir. Sonra, u.jump ve yaprakların çifte-bağlantılı
listesini kullanarak bul(x) işlemini tamamlarız.
442|
Yukarıdaki yöntemde, while döngüsünün her yinelemesi h – l değerini yaklaşık olarak 2 faktör oranında azaltır. Bu nedenle, bu
döngü O(log w) yinelemeden sonra u’yu bulur. Her yineleme sabit
zamanda iş gerçekleştirir ve Sırasız Küme üzerinde, sabit beklenen
zamanda bir bul(x) işlemi gerçekleştirir. Kalan iş, sadece sabit zaman alır, bu nedenle, X-Hızlı Sıralı Ağaç üzerinde bul(x) işlemi,
O(log w) beklenen zamanda çalışır.
X-Hızlı Sıralı Ağaç
Ağaç’ın
için ekle(x) ve sil(x) yöntemleri, İkili Sıralı
aynı yöntemleri ile hemen hemen aynıdır. Sadece,
t[0],….,t[w]
karma tablolarını yönetmek için değişiklikler yapılma-
sı gereklidir. ekle(x) işlemi sırasında, i seviyesinde yeni bir düğüm
oluşturulduğu zaman, bu düğüm t[i] tablosuna eklenir, sil(x) işlemi
sırasında, i seviyesinde bir düğüm silindiğinde, bu düğüm t[i] tablosundan silinir. Karma tabloya ekleme veya silme, sabit beklenen
zaman aldığı için, ekle(x) ve sil(x) çalışma zamanları, sabit bir
faktörden daha fazla artmaz. ekle(x) ve sil(x) için kod dökümünü
burada dahil etmiyoruz, çünkü kod, İkili Sıralı Ağaç’ın yöntemleri
tarafından sağlanan (uzun) kodun hemen hemen aynısıdır.
Aşağıdaki teorem X-Hızlı Sıralı Ağaç performansını özetlemektedir:
Teorem 13.2. X-Hızlı Sıralı Ağaç, w-bit tamsayılar için Sıralı Küme
arayüzünü uygular. X-Hızlı Sıralı Ağaç aşağıdaki işlemleri destekler:
| 443
İşlem başına O(w) beklenen zamanda çalışan ekle(x),
sil(x)
ve,
İşlem başına O(log w) beklenen zamanda çalışan
bul(x).
n
değer depolayan X-Hızlı Sıralı Ağaç O(n . w) alan kullanır.
444|
Y-Hızlı Sıralı Ağaç: Çifte-Logaritmik Zamanlı Sıralı Küme
X-Hızlı Sıralı Ağaç,
sorgu zamanı açısından, İkili Sıralı Ağaç ile
kıyaslandığında, oldukça büyük –hatta üstel – bir gelişme sağlar,
ancak ekle(x) ve sil(x) işlemleri hala istenildiği kadar hızlı değildir.
Ayrıca, alan kullanımı, O(n . w), bu kitapta anlatılan ve kullanım
alanı O(n) olan tüm diğer Sıralı Küme uygulamalarından daha yüksektir. Bu iki sorun ilişkilidir; ekle(x) işlemi n defa çalıştırılarak
boyutu n . w olan bir yapı kurulursa, ekle(x) işlemi, işlem başına
en azından w cinsinden bir zaman (ve alan) gerektirir.
Ardından tartışılan Y-Hızlı Sıralı Ağaç, X-Hızlı Sıralı Ağaç’ın alanını
ve hızını aynı anda iyileştirir. Y-Hızlı Sıralı Ağaç, X-Hızlı Sıralı
Ağaç’ı, xft,
kullanır, ancak xft içinde sadece O(n/w) değer depolar.
Bu şekilde, xft tarafından kullanılan toplam alan sadece O(n) olur.
Ayrıca, Y-Hızlı Sıralı Ağaç içindeki her w ekle(x), veya sil(x) işleminden sadece biri, xft içinde bir ekle(x) veya sil(x) işlemiyle sonuçlanır. Bunu yaparak, xft’nin ekle(x) ve sil(x) işlemleri için yaptığı çağrıların ortalama maliyeti sadece sabit olur.
Açıkça şunu sormalıyız: xft sadece n/w eleman depoluyorsa, geride
kalan n(1 – 1/w) eleman nereye gider? Bu elemanlar ikincil yapıların içine, bu durumda genişletilmiş bir Treaps versiyonunun
(bkz. Treap: Randomize İkili Arama Ağaçları Bölümü) içine taşınmıştır. Bu ikincil yapılardan, ortalama olarak, yaklaşık n/w tane
| 445
vardır, her biri O(w) eleman depolar. Treaps, logaritmik zamanda
çalışan Sıralı Küme işlemlerini desteklemektedir, bu nedenle bu
Treap’ler
üzerindeki işlemler gerektiği gibi, O(log w) zamanda
çalışacaktır.
Daha somut olarak, Y-Hızlı Sıralı Ağaç, her elemanın bağımsız olarak 1/w olasılıkla göründüğü bir rasgele veri örneği olan X-Hızlı
Sıralı Ağaç’ı, xft,
içerir. Kolaylık sağlaması için, 2w – 1 değeri, her
zaman
içindedir.
x0
x1
xft’nin
...
xk-1
xft
içinde
depolanan
elemanlar
ile ifade edilsin. Şekil 13.7’de gösterildiği gi-
bi, her xi elemanı ile ilişkili, xi–1 + 1,...,xi aralığındaki tüm değerleri depolayan bir treap, ti, vardır.
Y-Hızlı Sıralı Ağaç
x
içinde bul(x) işlemi oldukça kolaydır. xft içinde
ararız, ve treap, ti, ile ilişkili bazı xi değeri buluruz. Sonra sorgu-
yu cevaplandırmak için treap bul(x) yöntemini ti üzerinde çalıştırırız. Tüm kod, bir satırdan oluşmaktadır:
Birinci bul(x) işlemi (xft üzerinde) O(log w) zamanda çalışır. İkinci bul(x) işlemi (treap üzerinde), O(log r) zamanda çalışır. Burada
r, treap
boyutudur.
446|
İlerleyen bölümlerde, treap’in beklenen boyutunun O(w) olduğunu
göstereceğiz, böylece bu işlem O(log w) zamanda çalışacaktır.
Y-Hızlı Sıralı Ağaç
içine bir eleman eklemek de – çoğu zaman –
oldukça kolaydır. Önce x’in içine gireceği treap, t’yi bulmak için
ekle(x)
yöntemi xft.bul(x) çağrısı yapar. Sonra x’i, t içine eklemek
için t.ekle(x) çağrısı yapar. Bu noktada, 1/w olasılığıyla, tura gelen
ve 1 – 1/w olasığıyla yazı gelen hileli parayı fırlatır. Tura geldiyse,
xft
içine x eklenecektir.
| 447
İşlerin biraz daha karışık hale geldiği yer burasıdır. xft içine x eklendiğinde, treap t’nin iki treaps haline, t1 ve t’ olmak üzere, ayrılması gerekir. t1 treap değerlerinin tümü, x’den daha küçük veya
eşittir. t’, orijinal t treap’i içinden t1 elemanlarının çıkarılmasıyla
elde edilir. Bu işlem bir kez yapıldıktan sonra, xft içine (x, t1) çiftini ekleriz. Şekil 13.8 bir örneği gösteriyor.
448|
t
içine x eklenmesi O(log w) zamanda çalışır. Alıştırma 7.12, t’nin,
t1
ve t’ halinde ayrılmasının da O(log w) beklenen zamanda yapı-
labileceğini gösteriyor. xft içine (x, t1) çiftinin eklenmesi O(w)
zaman alır, ancak sadece 1/w olasılığıyla gerçekleşir. Bu nedenle,
ekle(x)
işlemi,
beklenen zamanda çalışır.
sil(x)
işlemi, ekle(x) tarafından gerçekleştirilen işleri geri alır.
xft.bul(x)
sonucunda xft içinde u yaprağını buluruz. u’dan, x’i içe-
ren t treap’ini elde ederiz, ve x’i t’den sileriz. x, xft’de de depolanmışsa (x, 2w – 1’e eşit değilse), x’i xft’den sileriz, ve x
treap’inin
içindeki elemanları, bağlantılı listede u’nun ardından
gelen, t2 treap’inin içine ekleriz. Şekil 13.9’da bu gösterilmiştir.
| 449
xft
içinde u düğümü, O(log w) beklenen zamanda bulunur. t’den x,
O(log w) beklenen zamanda silinir. Yine, Alıştırma 7.12, t içindeki
tüm elemanları O(log w) zamanda t2 içinde birleştirebileceğinizi
göstermektedir. Gerekirse, xft’den x, O(w) zamanda silinir, ancak x
yalnızca 1/w olasılığı ile xft’de yer almaktadır. Bu nedenle, Y-Hızlı
Sıralı Ağaç’tan
bir eleman O(log w) beklenen zamanda silinir.
Daha öncesinde, bu yapıda treap’lerin boyutlarını tartışmayı erteledik. Bu bölümü bitirmeden önce, ihtiyacımız olan sonucu kanıtlayacağız.
450|
Önerme 13.1. x, Y-Hızlı Sıralı Ağacı’nda depolanan bir tamsayı
olsun, ve x’i içeren t treap’inde bulunan eleman sayısı nx ile gösterilsin. E[nx] ≤ 2w – 1 olur.
Kanıt. Y-Hızlı Sıralı Ağaç’ta depolanan elemanlar, x1
xi = x
x’e
xi+1
…
xn ile
x2
…
ifade edilsin; bkz. Şekil 13.10. t treap’i,
eşit veya daha büyük bazı elemanları içeriyor. Bu elemanlar,
xi , xi+1, …, xi+j-1 ise, ekle(x)
işleminde fırlatılan hileli paranın tura
olarak döndüğü tek eleman xi+j-1 olarak hesaplanır. Diğer bir deyişle, E[j], ilk turayı elde etmek için gereken hileli para fırlatmanın
beklenen sayısına eşittir. Her yazı tura atma bağımsızdır ve tura
gelme
olasılığı
E[j] ≤ w (w = 2
1/w
olarak
ortaya
çıkıyor,
bu
nedenle,
durumunun analizi için, bkz. Önerme 4.2).
| 451
Benzer şekilde, x’den daha küçük t elemanları xi–1,…,xi–k ile veriliyor. Burada ilk k para fırlatmanın sonucu yazı ve kalan xi–k–1 para
fırlatmanın sonucu tura gelir. Bu, önceki paragrafta ele alınan yazı
tura atma deneyinin aynısı olduğu, ancak son para fırlatma sayılmadığı için E[k] ≤ w – 1 olarak hesaplanır. Özetle, nx = j + k, bu
nedenle,
Y-Hızlı Sıralı Ağaç
performansını özetleyen aşağıdaki teoremin ka-
nıtının son parçası Önerme 13.1’dir:
Teorem 13.3. Y-Hızlı Sıralı Ağaç, w-bit tamsayılar için Sıralı Küme
arayüzünü uygular. Y-Hızlı Sıralı Ağaç, ekle(x), sil(x) ve bul(x)
işlemlerini, işlem başına O(log w) beklenen zamanda destekler. n
değer depolayan Y-Hızlı Sıralı Ağacı O(n + w) alan kullanır.
Alan gereksinimindeki w terimi, xft’nin her zaman 2w – 1 değeri
depoladığı gerçeğinden ileri gelmektedir. Uygulamada değişiklikler
yapılabilir (koda bazı ekstra durumları ekleme pahasına), böylece
452|
bu değeri depolamak gereksiz olabilir. Bu durumda, teoremin alan
gereksinimi O(n) olur.
| 453
Tartışma ve Alıştırmalar
ekle(x), sil(x)
ve bul(x) işlemlerini O(log w) zamanda gerçekleşti-
ren ilk veri yapısı van Emde Boas tarafından önerilmişti ve o zamandan beri van Emde Boas (veya Katmanlı) Ağacı [74] olarak
bilinir hale gelmiştir. Orijinal van Emde Boas yapısı 2w büyüklüğündeydi, büyük tamsayılar için bu pratik değildi.
X-Hızlı Sıralı Ağaç
ve Y-Hızlı Sıralı Ağaç veri yapıları Willard [77]
tarafından keşfedildi. van Emde Boas ağaçları ile X-Hızlı Sıralı
Ağaç
yapısı yakından ilgilidir; örneğin, bir X-Hızlı Sıralı Ağaç’taki
karma tabloları, van Emde Boas ağacındaki diziler ile yer değiştirmiştir. Bunun anlamı, t[i] karma tablosunu depolamak yerine, van
Emde Boas ağacı 2i uzunluğunda bir diziyi depolar.
Tamsayıları depolamak için başka bir yapı da Fredman'in ve
Willard'ın füzyon ağaçlarıdır [32]. Bu yapı, n adet w-bit tamsayıları
O(n) büyüklüğündeki bir alanda depolayabilir, böylece bul(x) iş-
lemi, O((log n / (log w)) zamanda çalışır.
da füzyon ağacını kullanarak, ve
Sıralı Ağacı
lemini
olduğunolduğunda Y-Hızlı
kullanarak, O(n) alana gereksinimi olan ve bul(x) işzamanda uygulayabilen bir veri yapısı elde edilir.
Son zamanlarda Patrascu ve Thorup’un [59] alt sınır ile ilgili sonuçları göstermektedir ki, bu sonuçlar, en azından sadece O(n) alan
kullanan yapılar için az veya çok idealdir.
454|
Alıştırma 13.1. Bağlantılı listesi veya jump işaretçileri olmayan,
İkili Sıralı Ağaç’ın
basitleştirilmiş versiyonunu tasarlayın ve uygu-
layın. bul(x), O(w) zamanda çalışmalıdır.
Alıştırma 13.2. Hiçbir şekilde İkili Sıralı Ağaç kullanmayan,
X-Hızlı Sıralı Ağaç’ın
basitleştirilmiş versiyonunu tasarlayın ve uygu-
layın. Bunun yerine, uygulamanız bir Çifte Bağlantılı Liste’de, ve w
+1
karma tabloda herşeyi depolamalıdır.
Alıştırma 13.3. İkili Sıralı Ağacı’nı w uzunluğunda bit dizelerini
depolayan bir yapı olarak düşünebiliriz. Her bit dizisi, köktenyaprağa bir yolu temsil eder. Sıralı Küme uygulaması olarak bu
fikri genişletin. Uygulamanız, değişken uzunluklu dizeleri depolamalı, ve ekle(s), sil(s) ve bul(s) işlemlerini s uzunluğuna orantılı
bir zamanda gerçekleştirmelidir. İpucu: Veri yapınızdaki her düğüm, karakter değerleri ile endeksli bir karma tablo depolamalıdır.
Alıştırma 13.4. Bir tamsayı x
bul(x)
{0,…,2w – 1}
için, d(x), x ile
tarafından döndürülen değer arasındaki farkı göstersin
[bul(x) null döndürürse, d(x), 2w olarak tanımlanır]. Örneğin,
bul(23), 43
döndürürse, d(23) = 20.
1. X-Hızlı Sıralı Ağaç’ta bul(x) işleminin değiştirilmiş bir versiyonunu
tasarlayın
ve
uygulayın.
Bu
işlem
O(1 + log d(x)) beklenen zamanda çalışmalıdır. İpucu:
t[w]
karma tablosu, d(x) = 0 olan tüm x değerlerini içerir.
Başlamak için burası iyi bir yerdir.
| 455
2. X-Hızlı Sıralı Ağaç’ta bul(x) işleminin değiştirilmiş bir versiyonunu
tasarlayın
ve
uygulayın.
Bu
O(1 + log log d(x)) beklenen zamanda çalışmalıdır.
işlem
456|
| 457
Bölüm 14
Dış Bellek Aramaları
Bu kitap boyunca, Hesaplama Modeli Bölümü’nde tanımlanan
w-bit
sözcük-RAM hesaplama modelini kullanıyorduk. Bu modelin
kesin varsayımı şudur: Bilgisayarımızın rasgele erişim belleği, veri
yapısı içindeki tüm verileri depolamak için yeterince büyüktür.
Bazı durumlarda, bu varsayım geçerli değildir. O kadar büyük veri
koleksiyonları vardır ki, hiçbir bilgisayar bunları depolamak için
yeterli belleğe sahip değildir. Bu gibi durumlarda, uygulama, bir
sabit disk, katı hal diski, hatta (kendi harici depolaması olan) ağ
dosya sunucusu gibi, herhangi bir dış depolama ortamı üzerinde
veri depolamaya başvurmalıdır.
Harici depolama, eleman erişimi için son derece yavaş bir yöntemdir. Örneğin, bu bilgisayarın sabit diske erişimi ortalama 19 milisaniye, ve katı hal sürücüsüne erişimi 0,3 milisaniye ile verilmiştir.
Bunun aksine, bilgisayardaki rasgele erişim belleğinin 0,000113
milisaniyeden daha düşük ortalama erişim zamanı vardır. RAM
erişimi, katı hal sürücüsüne erişimden 2.500 kat daha fazla hızlıdır,
ve sabit sürücüye erişimden 160.000 kat daha hızlıdır.
458|
Bu hızlar oldukça olağandır; rasgele olarak RAM’dan bir bayta
erişmek, sabit diskten veya katı hal sürücüsünden erişmekten daha
hızlıdır. Ancak binlerce kere daha hızlı olan erişim zamanı, bütün
hikayeyi anlatmıyor. Bir sabit disk veya katı hal diskinden bir bayta
eriştiğinizde, diskin bütün bir bloğu okunur. Bilgisayara bağlı sürücülerin her birinin 4.096 blok boyutu vardır; biz bir bayt okuduğumuzda, sürücü bize her zaman 4.096 bayt içeren bir blok verir.
Dikkatli bir şekilde veri yapısını düzenlersek, her disk erişimi, yaptığımız işi tamamlamak için yararlı olabilecek 4.096 baytı verir.
Şekil 14.1’de şematik olarak gösterilen dış bellek modeli hesaplamasının arkasındaki fikir budur. Bu modelde bilgisayar, tüm verilerin bulunduğu büyük bir dış belleğe erişiyor. Bu bellek her biri B
sözcük içeren bellek bloklarına ayrılmıştır. Bilgisayar aynı zamanda hesaplamaları gerçekleştirmek için sınırlı bir iç belleğe de sahiptir. İç bellek ve dış bellek arasında bir blok aktarma sabit zaman
alır. İç bellek içinde yapılan hesaplamalar bedavadır ve zaman gerektirmez. İç bellek hesaplamalarının bedava olması aslında biraz
garip gelebilir, ancak sadece dış belleğin RAM’dan çok daha yavaş
olduğu gerçeğini vurgulamaktadır.
Tam gelişmiş dış bellek modelinde, iç bellek boyutu da bir parametredir. Ancak, bu bölümde açıklanan veri yapıları için, O(B +
logB n)
boyutunda bir iç belleğe sahip olmak yeterlidir.
| 459
Yani, belleğin sabit sayıda bloğa ve O(logB n) yüksekliğinde bir
özyineleme yığınını depolama yeteneğine sahip olması gerekir.
Çoğu durumda, bellek gereksinimi için O(B) yeterlidir. Örneğin,
hatta nispeten küçük bir B=32 değeri ve her n ≤ 2160 için,
B ≥ logB n
olarak hesaplanır. Onluk tabanda, her
için B ≥ logB n olarak hesaplanır.
460|
Blok Deposu
Dış bellek kavramı çok sayıda farklı olası cihazları içerir; bunlardan her birinin, kendine ait blok boyutu vardır ve kendi koleksiyonlarına ait sistem çağrıları ile erişilir. Ortak fikirler üzerinde odaklanmak üzere, bu bölümün daha rahat anlaşılması için, BlokDeposu
adında bir nesne ile dış bellek cihazlarını kılıflıyoruz. BlokDeposu,
her biri B boyutunda olan bellek bloklarının bir koleksiyonunu depolar. Her blok benzersiz tamsayı endeksi ile tanımlanır.
BlokDeposu
şu işlemleri destekler:
1.
readBlock(i): i
endeksli blok içeriğini döndürür.
2.
writeBlock(i, b): i
3.
placeBlock(b):
endeksli blok üzerine b içeriğini yazar.
Yeni bir endeks döndürür ve bu endeksli blok
üzerine b içeriğini depolar.
4.
freeBlock(i): i
endeksli bloğu serbest bırakır. Bu, blok içeriği-
nin artık kullanılmadığı anlamına gelir, bu nedenle, bu blok tarafından ayrılan dış bellek yeniden kullanılabilir.
BlokDeposu’nu
düşünmenin en kolay yolu, disk üzerinde her biri B
bayt içeren bloklara bölünen bir dosyayı depolamanın tasarımlanmasıdır. Bu şekilde, readBlock(i) ve writeBlock(i, b), bu dosyadan
sadece iB,...,(i + 1)B – 1 bayt okur ve üzerine yazar. Buna ek olarak, BlokDeposu, kullanıma hazır olan blokların bir serbest listesini
tutabilir. freeBlock(i) tarafından serbest bırakılan bloklar, serbest
listesine eklenir. Bu şekilde, placeBlock(b), serbest listesinden bir
| 461
blok kullanabilir, veya hiçbiri hazır kullanılışlı değilse, dosyanın
sonuna yeni bir blok ekler.
462|
B-Ağaçları
Bu bölümde, dış bellek modelinde verimliliği olan ve B-Ağaç denilen, İkili Ağaç’ların bir genellemesini tartışıyoruz. B-Ağaç, alternatif olarak, 2-4 Ağacı Bölümü’nde anlatılan 2-4 Ağaç’larının doğal
genellemesi olarak görülebilir (2-4 Ağaç, B = 2 olarak belirlenmiş
B-Ağacı’nın
özel bir durumudur).
Herhangi bir tamsayı, B ≥ 2 için B-Ağacı, yaprakları aynı derinliğe
sahip olan, ve kök-olmayan her, u, iç düğümünün en az B çocuğu,
ve en çok 2B çocuğunun olduğu bir ağaçtır. u çocukları, u.children
dizisinde depolanır. Gerekli çocuk sayısı kökte dikkate alınmaz, 2
ve 2B aralığında herhangi bir sayıda olabilir.
B-Ağacı’nın
yüksekliği h ise, o zaman B-Ağacı’nın yaprak sayısı, l,
için şu söylenebilir:
İlk eşitsizliğin logaritması alınarak ve terimler yeniden düzenlenerek,
elde edilir.
| 463
Yani, B-Ağacı’nın yüksekliği, yaprak sayısının B-tabanında logaritması ile orantılıdır.
B-Ağacı’nın
her u düğümü, u.keys[0],...,u.keys[2B – 1] konumla-
rında bir anahtar dizisi depolar. u, k çocuklu bir iç düğüm ise, o
zaman u tarafından depolanan anahtarların sayısı tam olarak k – 1
olur, ve bunlar, u.keys[0],...,u.keys[k – 2] konumlarında depolanır. u.keys dizisinin kalan 2B – k + 1 girişleri null olarak belirlenir. u kök olmayan bir yaprak düğüm ise, o zaman, u, B – 1 ve 2B
– 1
arasında bir anahtar değer depolar. B-Ağacı’nın anahtarları İkili
Arama Ağacı’nın
anahtarlarının benzeridir. k – 1 anahtar depolayan
her, u düğümü için,
sıralaması geçerlidir.
Eğer, u bir iç düğüm ise, o zaman her i
u.keys[i]
{0,…,k – 2}
için
anahtarı, u.children[i] kökenli altağaçta depolanan her
anahtardan büyüktür, ancak u.children[i + 1] kökenli altağaçta
depolanan her anahtardan küçüktür. Yani,
Şekil 14.2, B = 2 olan B-Ağacı’na bir örnek gösteriyor.
464|
B-Ağacı’nda
bir düğümde depolanan veri boyutu daha önce O(B)
olarak açıklanmıştı. Dikkat edin ki, B-Ağacı’nın içindeki B değerini
seçerken, bir düğüm bir adet dış bellek bloğuna sığmalıdır. Dış
bellek modelinde, B-Ağaç işlemini gerçekleştirmek için gerekli
zaman, erişilen (okunan veya yazılan) düğüm sayısı ile orantılıdır.
Örneğin, anahtarlar 4 bayt tamsayı ve düğüm işaretleri de 4 bayt
ise, o zaman B = 256 belirlemesiyle her düğümde,
bayt veri depolanır. Blok boyutu 4096 bayt olan sabit disk veya bu
bölümde tartışılan katı hal sürücüsü için bu, mükemmel bir B değeri olacaktır.
B-Ağacı’nı
uygulayan B-Ağaç sınıfı, B-Ağacı’nın düğümlerini ve
kök düğümün endeksini, ri, depolayan BlokDeposu’nu, bs, depolar.
| 465
Her zamanki gibi, veri yapısındaki eleman sayısını belirlemek için,
n
tamsayısı, kullanılır:
466|
Arama
İkili Arama Ağacı’ndaki bul(x)
işlemini genelleştirerek Şekil
14.3’te gösterilen bul(x) işlemini uygulayabilirsiniz. x için arama
kökte başlar, ve bir u düğümünün çocuklarının hangisinden arama
devam edecekse bunu belirlemelisiniz. Bunun için, u düğümünde
depolanan anahtarları kullanın.
Daha spesifik olursak, bir u düğümündeki arama için, x’in u.keys
içinde saklı olduğunu kontrol etmelisiniz. Eğer öyleyse, x bulunmuştur ve arama tamamlanır. Aksi takdirde, arama u.keys[i] > x
olan en küçük, i, tamsayısını bulur, ve u.children[i] kökenli
altağaçta arama devam eder.
u.keys
içinde bulunan hiçbir anahtar, x’den büyük değilse, o zaman
arama u’nun en sağındaki çocuğundan devam eder.
| 467
Aynı ikili arama ağaçlarında olduğu gibi, algoritma x’den büyük
olan, en son görülen z anahtarını izler. x bulunmazsa, x’e eşit, veya
daha fazla olan en küçük değer olarak, z, döndürülür.
bul(x)
işleminin merkezinde, null ile başlatılmış sıralı bir, a dizisi
içinde x değerini arayan, findIt(a, x) işlemi bulunmaktadır. Bu işlem Şekil 14.4’de gösterilmiştir.
Herhangi bir, a dizisi için, sıralı olarak dizilmiş anahtarlar
a[0],...,a[k
–
1]
ile gösterildiği takdirde, ve başlangıçta
a[k],...,a[a.length – 1]
değerlerinin tümü null iken, örnek çalıştı-
rılmıştır.
Eğer x, dizide, i konumunda ise, o zaman findIt(a, x) tarafından
döndürülen değer, – i – 1 olarak hesaplanır. Aksi takdirde,
a[i]
x,
veya a[i] = null olan en küçük, i endeksini döndürür.
468|
findIt(a, x)
işlemi, her adımda arama alanını yarıya bölen ikili
aramayı kullanır, bu nedenle O(log(a.length)) zamanda çalışır.
Bizim ortamımızda, a.length = 2B olduğu için, findIt(a, x) çalışma zamanı O(log B) olur.
B-Ağaç bul(x)
işleminin çalışma zamanını, hem normal sözcük-
RAM modelinde (her komutu hesaba kattığımız), ve hem dış bellek
modelinde (sadece erişilen düğüm sayısını önemsediğimiz) analiz
edebiliriz.
B-Ağaç
içindeki her yaprak en az bir anahtar depoladığı için, ve l
yapraklı B-Ağaç’ın yüksekliği O(logB l) olduğu için, n anahtar depolayan B-ağacı’nın yüksekliği O(logB n) olarak hesaplanır. Bu
nedenle, dış bellek modelinde, bul(x) işlemi O(logB n) zamanda
çalışır. Sözcük-RAM modelinde çalışma zamanını belirlerken, eriş-
| 469
tiğimiz her düğüm için, findIt(a, x) çağrı maliyetini hesaba katmalıyız, böylece sözcük-RAM modelinde bul(x) işlemi,
zamanda çalışır.
470|
Ekleme
B-Ağacı
ve Serbest Yükseklikli İkili Arama Ağacı Bölümü’nde
anlatılan İkili Arama Ağacı veri yapısı arasındaki önemli farklardan
biri, B-Ağaç düğümlerinin menşeilerine işaretçi tutmamalarıdır.
Bunun nedeni kısaca açıklanacaktır. Menşei işaretçilerinin eksikliği
B-Ağaç’lar
üzerinde ekle(x) ve sil(x) işlemlerinin en kolayca özyi-
neleme kullanılarak uygulanması anlamına gelir.
B-Ağacı’nda ekle(x)
çalışması sırasında düğümlerin bölünmesi ile
bir tür dengeleme gereklidir. Tüm dengeli arama ağaçlarında olduğu gibi, bölünme iki düzeyli özyineleme sırasında gerçekleşir; bkz.
Şekil 14.5. Bölünmeyi en iyi şu şekilde anlayabilirsiniz: 2B anahtar
ve 2B + 1 çocuk sahibi bir, u düğümünü girdi olarak alan bir işlemdir. u.children[B],..,u.children[2B] benimsenerek yeni bir, w
düğümü oluşturulur. Yeni düğüm w, u’nun en büyük anahtarlarını
u.keys[B],…,u.keys[2B – 1]
alır. Bu noktada, u, B çocuğa ve B
anahtara sahiptir. Ekstra anahtar, u.keys[B – 1], u menşeine kadar
geçirilerek, w benimsenir.
Dikkat etmelisiniz ki, bölme işlemi üç düğüm değiştirir: u, u’nun
menşei ve yeni düğüm w. B-ağaç düğümlerinin menşei işaretçilerini tutmamasının önemli nedeni, dış bellek erişimlerinin sayısını
3’ten B + 4’e artırmasıdır. w
tarafından benimsenen B + 1 çocuğun
tüm menşei işaretçilerini değiştirmek, büyük B değerleri için, BAğaç’larını
çok daha az etkili kılar.
| 471
Şekil 14.6, B-ağaç ekle(x) işleminin örnek çalıştırmasını gösteriyor. Yüksek seviyede bu işlem, x değerini eklemek için bir, u yaprağını bulur. Bunun sonucunda, B – 1 anahtar içerdiği için, u fazla
doluyken, u bölünür. u’nun menşei fazla doluluk içindeyse, o zaman u menşei de bölünür, u’nun büyükbabasının fazla doluluk
içermesine neden olabilir, vb. Bu süreç, ağaç her seferinde bir seviye yukarı hareket ederek, fazla dolu olmayan bir düğüme ulaşana
kadar veya kök bölünene kadar devam eder. İlk durumda, işlem
durur. Sonraki durumda, orijinal kök bölündüğü zaman elde edilen
472|
düğümlerin kökün iki çocuğu haline gelmesiyle, yeni bir kök oluşturulur.
ekle(x)
işleminin kısa özeti, kökten yaprağa x aranır, bulunan yap-
rağa x eklenir, ve sonra köke dönüş yolunda karşılaşılan herhangi
fazla dolu düğümler bölünür. Geliştirdiğimiz bu üst düzey düşünceyle, bu işlemin özyinelemeli olarak nasıl uygulanabilir olduğunu
araştırmaya devam ediyoruz.
| 473
ekle(x)
için gerekli gerçek iş, ui tanımlayıcısına sahip u kökenli
altağaca x değerini ekleyen, addRecursive(x, ui) işlemi tarafından
yapılıyor. u bir yaprak ise, o zaman x sadece u.keys içine eklenir.
Aksi takdirde, özyinelemeli olarak x, uygun u’ çocuğu içine eklenir.
Bu özyinelemeli çağrının sonucu, normalde null iken, aynı zamanda u’ bölündüğü için yeni oluşturulan, w, düğümüne bir referans
olabilir. Bu durumda, w, u tarafından benimsenir ve ilk anahtarı
alarak u’ üzerindeki bölme işlemini tamamlar.
x
değeri (u veya altındaki düğümlerden biri içine) eklendikten son-
ra, addRecursive(x, ui) işlemi, u tarafından çok fazla anahtar depolanıp depolanmadığını (2B – 1 anahtardan daha fazla olmamalı)
kontrol eder. Eğer öyleyse, u.split() işlemine yapılan bir çağrı ile u
bölünür. u.split() çağrısının sonucu, addRecursive(x, ui) için dönüş değeri olarak kullanılan yeni bir düğümdür.
474|
addRecursive(x, ui)
işlemi, B-Ağacı’nın köküne bir, x değeri ekle-
mek için addRecursive(x, ri) çağrısının yapıldığı, ekle(x) işlemini
çalıştırır. addRecursive(x, ri), kökü bölene kadar giderse, o zaman
hem eski kökü, ve hem eski kökün bölünmesiyle oluşturulan yeni
düğümü çocukları olarak alan, yeni bir kök oluşturulur.
ekle(x)
ve addRecursive(x, ui) işlemlerini iki aşamada analiz ede-
biliriz:
Aşağı yönde: Özyinelemenin aşağı yönünde, x eklenmeden önce,
bir dizi BAğacı düğümüne erişim sağlanır, ve her düğüm üzerinde
findIt(a, x)
çağrısı gerçekleştirilir. bul(x) işleminde olduğu gibi,
| 475
dış bellek modelinde O(logB n) zamanda, ve sözcük-RAM modelinde O(log n) zamanda çalışır.
Yukarı yönde: Özyinelemenin yukarı yönünde, x eklendikten sonra, bu işlemler, en fazla O(logB n) bölünme gerçekleştirir. Her bölünme sadece üç düğüm içerir, bu nedenle bu aşama dış bellek modelinde O(logB n) zamanda çalışır. Ancak, her bölünme B anahtarın
ve çocuklarının bir düğümden diğer düğüme hareket etmesini içerdiği için, sözcük-RAM modelinde, O(B log n) zaman alır.
B
değeri oldukça büyük, hatta log n’den çok daha büyük olduğu
takdirde, sözcük-RAM modelinde, B-ağacı’na bir değer eklemek,
dengeli İkili Arama Ağacı içine eklemekten çok daha yavaş olabilir.
Daha sonra, B-Ağaç’ların Amortize Analizi Bölümü’nde, durumun
fazla da korkutucu olmadığını göstereceğiz; bir ekle(x) çalışması
sırasında bölünme işlemlerinin amortize sayısı sabittir. SözcükRAM modelinde, ekle(x) işleminin (amortize) çalışma zamanı, bu
nedenle, O(B + log n) olur.
476|
Silme
B-ağaç
içindeki sil(x) işlemini uygulamak, yine en kolay şekilde,
bir özyinelemeli işlemdir. Karmaşıklığı, birkaç işlem üzerinden
yayılmasına rağmen, Şekil 14.7’de gösterilen genel süreç, oldukça
kolaydır. Anahtarların karıştırılıp değiştirilmesiyle silme işlemi, bir
x’
değerinin bazı, u yaprağından çıkarılması problemine indirgenir.
x’
çıkarılmasıyla, u, B – 1 anahtar ile bırakılabilir, bu durum
alttaşma olarak adlandırılır.
Bir alttaşma oluştuğunda, u kardeşlerinden biri ile birleşir, veya
kardeşinden anahtar ödünç alır. u, kardeşi ile birleştiyse, o zaman,
u
menşei, bir çocuk daha az, ve bir anahtar daha az sahibi olacaktır;
bu, u’nun menşeinin de alttaşmasına neden olabilir, bu tekrar,
ödünç alma veya birleştirerek düzeltilir, ancak birleştirme u'nun
büyükbabasının da alttaşmasına neden olabilir. Bu süreç, köke kadar artık alttaşma kalmayana kadar, veya kökün son iki çocuğu bir
tek çocuk halinde birleştirilene kadar geri dönüş yolunda çalışır.
İkinci durum olduğunda, kök kaldırılır, ve yalnız olan tek çocuk
yeni kök olarak hesaplanır.
Şimdi, bu adımların her birinin nasıl uygulandığını detaylarıyla
anlatacağız. sil(x) işleminin ilk işi, çıkarılacak x elemanını bulmaktır. x bir yaprakta bulunursa, o zaman bu yapraktan x silinir. Aksi
takdirde, bazı iç düğüm, u için u.keys[i] pozisyonunda x bulunur-
| 477
sa, o zaman algoritma u.children[i + 1] kökenli altağaçtaki en küçük, x’ değerini siler.
x’
değeri, BAğaç’ta depolanan x’den büyük olan en küçük değerdir.
x’
değeri, sonra u.keys[i] içindeki
x
değerini değiştirmek için kul-
lanılacak. Şekil 14.8 bu süreci gösteriyor.
removeRecursive(x, ui)
bir uygulamasıdır:
işlemi önceki algoritmanın özyinelemeli
478|
Unutmayın ki, özyinelemeli olarak u’nun i’nci çocuğundan x değerini çıkardıktan sonra, bu çocuğun hala en az B – 1 anahtarı bulunduğunu removeRecursive(x, ui) işleminin sağlaması gerekiyor.
Önceki kodda, u’nun i’nci çocuğunda bir alttaşma olup olmadığını
kontrol ettik, ve bunu düzelten checkUnderflow(x, i) adı verilen bir
işlemi kullandık. u’nun i’nci çocuğu w olsun. w sadece B – 2 anahtara sahipse, bunun düzeltilmesi gerekir. Düzeltme, w’nin bir kardeşinin kullanılmasını gerektirir. Bu u’nun ya (i + 1)’nci çocuğudur veya (i – 1)’nci çocuğudur. Genellikle, w’nin doğrudan solundaki kardeşi, v olan (i – 1)’nci çocuğu kullanacağız. Bunun işe
yaramadığı sadece bir zaman vardır, i = 0 iken, bu durumda w’nin
doğrudan sağındaki kardeşi kullanırız.
| 479
480|
Aşağıda,
durumuna odaklanıyoruz. Burada u’nun i’nci çocu-
ğundaki herhangi bir alttaşma, u’nun (i – 1)’nci çocuğu yardımı ile
düzeltiliyor. i = 0 durumu da benzerdir, ve ayrıntıları ekteki kaynak
kodunda bulunabilir.
w
düğümündeki bir alttaşmayı düzeltmek için, w için daha fazla
anahtar (ve muhtemelen de çocuklar) bulmamız gerekiyor. Bunu
yapmanın iki yolu vardır:
| 481
Ödünç alma: w’nin, B – 1 anahtardan daha fazlasına sahip olan, v,
adında bir kardeşi varsa, o zaman w bazı anahtarları (ve muhtemelen de çocukları) v’den ödünç alabilir. Daha spesifik olarak, v, size(v)
tane anahtar depoluyorsa o zaman, v ve w, aralarında,
anahtara sahip olur. Bu nedenle, v’den w’ye anahtarları kaydırabiliriz, böylece v ve w’nin her biri en az B – 1 anahtara sahip olacaktır.
Şekil 14.9 bu süreci gösteriyor.
Birleştirme: Eğer v’nin sadece B – 1 anahtarı varsa, daha zorlayıcı
bir şey yapmamız gerekir, çünkü v herhangi bir anahtarı w’ye vermeyi göze alamaz. Bu nedenle, Şekil 14.10’de gösterildiği gibi, v
ve w birleştirilir. Birleştirme işlemi bölme işleminin tersidir. 2B – 3
toplam anahtar içeren iki düğüm alır, ve onları 2B – 2 anahtar içeren tek bir düğüm haline birleştirir (Ek anahtarın gelmesinin nedeni
şudur: v ve w’yi birleştirdiğimizde, onların ortak menşei u’nun
şimdi bir daha az çocuğu vardır ve dolayısıyla anahtarlarından birisinden vazgeçmesi gerekiyor).
Özetlemek gerekirse, B-Ağaç’taki sil(x) işlemi kökten yaprağa bir
yol izler, u, yaprağından bir x’ anahtarını kaldırır, ve sonra u ve
onun atalarını içeren sıfır veya daha fazla birleştirme işlemleri gerçekleştirir, ve en fazla bir ödünç alma işlemi gerçekleştirir. Her
birleştirme ve ödünç alma işlemi sadece üç düğüm değiştirmeyi
482|
içerdiğinden ve bu işlemlerin sadece O(logB n) kadarı oluştuğundan, dış bellek modelinde tüm süreç O(logB n) zamanda çalışır.
Yine, sözcük-RAM modelinde her birleştirme ve ödünç alma işlemi, O(B) zamanda; sil(x) işlemi O(B logB n) zamanda çalışır.
| 483
484|
B-Ağaç’ların Amortize Analizi
Şimdiye kadar göstermiştik ki:
1. Dış bellek modelinde, B-Ağaç’ın bul(x), ekle(x) ve sil(x)
işlemlerinin çalışma zamanı O(logB n) olarak hesaplanır.
2. Sözcük-RAM modelinde, bul(x) işleminin çalışma zamanı
O(log n), ve ekle(x), sil(x) işleminin çalışma zamanı O(B
log n)
olarak hesaplanır.
Aşağıdaki önerme gösteriyor ki, şimdiye kadar, B-Ağaç’ları tarafından gerçekleştirilen birleştirme ve bölünme işlemlerinin sayısını,
olduğundan fazla tahmin ettik.
Önerme 14.1. Boş bir B-Ağaç ile başlandığında, m adet ekle(x) ve
sil(x)
işlemi herhangi bir sırada yürütülürse, en çok 3m/2 adet
bölünme, birleştirme ve ödünç alma gerçekleştirilir.
Kanıt. Bunun kanıtı, zaten Kırmızı Siyah Ağaçlar-Özet Bölümü’nde, B = 2 özel durumu için kısaca anlatılmıştı. Önerme, kredi
düzeni kullanılarak kanıtlanabilir. Burada,
1. Her bölme, birleştirme, veya ödünç alma işlemi iki kredi ile
ödenir, yani, bu işlemlerin biri oluştuğunda her zaman bir
kredi kaldırılır; ve,
2. Herhangi ekle(x) veya sil(x) işlemi sırasında en çok üç kredi oluşturulur.
| 485
Herhangi bir zamanda, en çok 3m kredi oluşturulduğu için, ve her
bir bölünme, birleştirme ve ödünç alma iki kredi ile ödendiği için
en çok 3m/2 adet bölünme, birleştirme, ve ödünç alma yapıldığı
sonucuna varırız. Bu krediler, Şekil 14.5, 14.9 ve 14.10’da ¢ sembolü kullanılarak gösterilmiştir.
Bu kredileri takip etmek için, kanıt, aşağıdaki kredi değişmeyenini
korur: B – 1 anahtara sahip kök-olmayan bir düğüm, bir kredi depolar, ve 2B – 1 anahtarlı herhangi bir düğüm üç kredi depolar. En
az B anahtar ve en çok 2B – 2 anahtar depolayan bir düğümün herhangi bir kredi depolaması gerekmez. Geriye kalan yapmamız gereken, kredi değişmeyenini korumak olduğunu göstermek ve her
ekle(x)
ve sil(x) işlemi sırasında, yukarıda verilen, 1. ve 2. özellik-
leri sağlamaktır.
Ekleme: ekle(x) işlemi, herhangi bir birleştirme veya ödünç alma
gerçekleştirmez, bu nedenle, sadece ekle(x) için yapılan aramaların
bir sonucu olarak ortaya çıkan bölünme işlemlerini dikkate almamız gerekiyor.
Her bölünme işlemi gerçekleştiğinde, zaten 2B – 1 anahtar içeren
bir, u düğümüne bir anahtar eklenir. Bu durumda, u, B – 1 anahtar
içeren u’, ve B anahtar içeren u’’ düğümü olmak üzere iki düğüme
ayrılmıştır. Bu işlem öncesinde, u, 2B – 1 anahtar ve dolayısıyla üç
kredi saklıyordu. Bu kredilerin ikisi, bölünmeyi ödemek için kullanılabilir, ve diğer kredi, kredi değişmeyenini korumak için (B – 1
486|
anahtara sahip olan) u’ düğümüne verilebilir. Bu nedenle, bölünme
için ödeme yapabiliriz, ve herhangi bir bölünme sırasında kredi
değişmeyenini koruyabiliriz.
Bir ekle(x) işlemi sırasında meydana gelen düğümler için yapılan
diğer değişiklik, sadece bütün bölünmeler tamamlandığında gerçekleşir. Bu değişiklik, bazı u’ düğümüne yeni bir anahtar eklenmesini
içerir. Eğer, bunun öncesinde u’ düğümünün 2B – 2 çocuğu vardıysa, şimdi 2B – 1 çocuk sahibidir ve bu nedenle üç kredi almak zorundadır. Bu ekle(x) işlemi ile dağıtılan yalnız ve tek kredidir.
Silme: sil(x) için yapılan bir çağrı sırasında, sıfır veya daha fazla
birleştirme meydana gelir, ve muhtemelen bunu tek bir ödünç alma
izler. Her birleştirme, sil(x) çağrısı öncesinde her biri tam olarak B
–1
anahtar sahibi iki düğümün, v ve w, tam olarak 2B – 2 anahta-
ra sahip tek bir düğüm halinde birleştirilmesi nedeniyle oluşur. Bu
türde her birleştirme, bu nedenle, birleştirmeyi ödemek için kullanılabilecek olan iki krediyi serbest bırakır.
Herhangi bir birleştirme yapıldıktan sonra, en fazla bir ödünç alma
işlemi gerçekleşir; daha sonra başka hiçbir birleştirme, veya ödünç
alma meydana gelmez. Bu ödünç alma işlemi, sadece B – 1 anahtara sahip, v, yaprağından bir anahtarı kaldırırsak oluşur. v düğümü
bu nedenle bir krediye sahiptir, ve bu kredi ödünç alma maliyetine
doğru gider. Bu tek kredi ödünç almayı ödemek için yeterli değildir, bu nedenle ödemeyi tamamlamak için bir kredi yaratırız.
| 487
Bu noktada, bir kredi yarattık ve hala kredi değişmeyeninin korunabilir olduğunu göstermemiz gerekiyor. En kötü durumda, v’nin
kardeşi, w, ödünç almadan önce tam olarak B anahtara sahipti, böylece, daha sonra, v ve w, her ikisinin de B – 1 anahtarı olacaktır.
Bunun anlamı, işlem tamamlandığında v ve w, her ikisinin de kredi
depoluyor olması gerekir. Bu nedenle, bu durumda, v ve w’ye vermek için, ek iki kredi oluştururuz. Bir sil(x) çalışması sırasında, en
fazla bir kez ödünç alma olduğu için bu, gerektiği gibi en çok üç
kredi yarattığımız anlamına gelir.
sil(x)
işlemi ödünç alma işlemini içermiyorsa, bunun nedeni, iş-
lemden önce B veya daha fazla anahtarı olan bazı düğümden bir
anahtar çıkararak bitirdiği içindir. En kötü durumda, bu düğümün,
tam olarak B anahtarı vardı, öyle ki şimdi B – 1 anahtarı bulunuyor,
ve yarattığımız bir kredi verilmelidir.
Her iki durumda – silme, ödünç alma ile işini bitirse de veya bitirmese de – sil(x) için yapılan bir çağrı sırasında kredi değişmeyenini
korumak, ve meydana gelen tüm ödünç alma ve birleştirmelerin
ödemesini yapmak için, en fazla üç kredi yaratılmalıdır. Bu önermenin kanıtını tamamlar.
Önerme 14.1’in amacı, sözcük-RAM modelinde, m adet ekle(x) ve
sil(x)
işlemi sırasında gerçekleştirilen bölünme ve birleştirmelerin,
sadece O(Bm) zamanda çalıştığını göstermektir. Yani, işlem başına
amortize maliyet, sadece O(B) olarak hesaplanır, böylece sözcük-
488|
RAM modelinde, ekle(x) ve sil(x) amortize maliyeti O(B + log n)
olarak hesaplanır. Aşağıdaki teorem çifti bunu özetliyor:
Teorem 14.1 (Dış Bellek B-Ağaç’ları). BAğaç, Sıralı Küme
arayüzünü uygular. Dış Bellek modelinde, BAğaç, işlem başına
O(logB n) zamanda çalışan ekle(x), sil(x), ve bul(x) işlemlerini
destekler.
Teorem 14.2 (Sözcük-RAM B-Ağaç’ları). BAğaç, Sıralı Küme
arayüzünü uygular. Sözcük-RAM modelinde, bölünme, birleştirme
ve ödünç almaların maliyeti önemsenmediği takdirde, BAğaç, işlem
başına O(log n) zamanda çalışan ekle(x), sil(x), ve bul(x) işlemlerini destekler. Boş bir BAğaç ile başlandığında, herhangi bir sırada
m
adet ekle(x) ve sil(x) işlemlerini yürütürsek bölünme, birleştir-
me, ve ödünç alma, toplam O(Bm) zamanda çalışır.
| 489
Tartışma ve Alıştırmalar
I/O modeli veya disk erişimi modeli olarak da adlandırılan, dış bellek hesaplama modeli, Aggarwal ve Vitter tarafından tanıtıldı [4].
B-Ağacı
için dış bellek araması, İkili Arama Ağacı için içsel bellek
aramasına benzer. B-ağacı [9] 1970 yılında Bayer ve McCreight
tarafından tanıtıldı, ve on yıldan daha az bir süre sonra, Comer
ACM Bilgisayar Anketleri makalesi, onları her yerde hazır bulunan
olarak anmıştır [15].
İkili Arama Ağacı
B-Ağacı
gibi, B-Ağacı’nın, B+ Ağacı, B* Ağacı, ve sayılan
dahil olmak üzere birçok çeşidi vardır. B-Ağacı, gerçekten
her yerde vardır, ve Apple'ın HFS+, Microsoft'un NTFS, ve Linux
Ext4 dahil olmak üzere, birçok dosya sistemlerinde, her büyük veritabanı sisteminde, ve anahtar-değer depolayan bulut bilişimin birincil veri yapısıdır. Graefe’nin en son anketi [36] birçok modern
uygulamalar, varyantları, ve B-ağacı’nın optimizasyonları üzerine
200+ sayfalık bakış sağlar.
B-Ağacı, Sıralı Küme
arayüzünü uygular. Yalnızca Sırasız Küme
arayüzü gerekli ise, dış bellek karma işlemi, B-Ağacı’nın bir alternatifi olarak kullanılabilir. Dış bellek karma tasarımları vardır; bkz.
örneğin, Jensen ve Pagh [43]. Bu tasarımlar, Sırasız Küme işlemlerini, dış bellek modelinde O(1) beklenen zamanda uygular. Bununla birlikte, çeşitli nedenlerden dolayı, birçok uygulama sadece Sıra-
490|
sız Küme
işlemlerini gerektiriyor olsa bile, B-Ağaç’larını hala kul-
lanmaktadır.
B-Ağaç’larını
böyle popüler bir seçim yapan nedenlerden biri, ge-
nellikle önerilen O(logB n) çalışma zamanı sınırlarından daha iyi
performans gösteriyor olmasıdır. Bunun nedeni, dış bellek ortamlarında, B değeri genellikle oldukça büyüktür – yüzler hatta binler
cinsinden. Bunun anlamı, B-Ağaç verilerinin % 99, hatta % 99,9
kadarı yapraklarda depolanır. Büyük bir belleğe sahip bir veritabanı
sisteminde, B-ağacı’nın, RAM’deki tüm iç düğümlerini önbelleğe
alması mümkün olabilir, çünkü toplam veri setinin sadece % 1 veya
% 0,1 kadarını temsil eder. Bunun anlamı, B-ağacı’nın, RAM’i
içinde iç düğümler aracılığıyla ve bunu takiben bir yaprak bulup
getirmek için, tek bir dış bellek erişimiyle çok hızlı arama gerçekleştirebilmesidir.
Alıştırma 14.1. Şekil 14.2’deki B-Ağacı’na 1,5 ve 7,5 anahtarlarını
eklediğinizde ne olacağını gösterin.
Alıştırma 14.2. Şekil 14.2’deki B-Ağacı’ndan 3 ve 4 anahtarlarını
sildiğinizde ne olacağını gösterin.
Alıştırma 14.3. n anahtar depolayan B-Ağacı’nın iç düğümlerinin
maksimum sayısı nedir? (n ve B parametrelerini alan bir fonksiyon
tanımlayın.)
Alıştırma 14.4. Bu bölümün giriş kısmında, B-Ağacı’nın sadece,
O(B + logB n) boyutunda içsel belleğe ihtiyacı olduğu öne sürül-
| 491
müştü. Ancak, burada verilen uygulama gerçekte daha fazla bellek
gerektiriyor.
1.
Bu bölümde verilen ekle(x) ve sil(x) işlemlerinin uygula-
masının, O(B logB n) ile orantılı içsel bellek kullandığını gösterin.
2.
Bu işlemlerin bellek tüketimini O(B + logB n) düzeyine
azaltmak amacıyla, nasıl değiştirebileceğinizi açıklayın.
Alıştırma 14.5. Şekil 14.6 ve 14.7’deki ağaçlar üzerinde, Önerme
14.1’in kanıtında kullanılan kredileri yazın. Bölünme, birleştirme,
ödünç alma ve kredi değişmezinin korunmasını üç ek kredi ile ödeyebileceğinizi doğrulayın.
Alıştırma 14.6. Düğümleri B’den 3B’ye kadar çocuk (ve dolayısıyla B – 1’den 3B – 1’e kadar sayıda anahtar) sahibi olan
B-Ağacı’nın
değiştirilmiş bir versiyonunu tasarlayın. B-Ağacı’nın
bu yeni versiyonunun, m işlem dizisi sırasında sadece O(m/B) bölünme, birleştirme ve ödünç alma gerçekleştirdiğini gösterin.
Alıştırma 14.7. Bu alıştırmada, B-Ağaç’larında bir seferde en fazla
üç düğümü dikkate alarak bölünme, ödünç alma ve birleştirme sayısını asimptotik olarak azaltan, ve değiştirilmiş bir bölünme ve
birleştirme işlemi tasarlayacaksınız.
1.
u
fazla dolu bir düğüm ve, v, u’nun hemen sağındaki kardeş
olsun. u taşmasını düzeltmek için iki yol vardır:
492|
u anahtarlarından bazılarını v’ye verebilir; veya,
u bölünebilir, ve u ve v anahtarları, u, v ve yeni oluşturulan
w
düğümü arasında eşit olarak dağıtılabilir.
Bu işlem sonrasında etkilenen düğümlerin her birinin (en fazla 3
adet), herhangi bir sabit
için, en az
ve en çok
anahtar sahibi olduğunu gösterin.
2.
u
az dolu bir düğüm, ve v ve w, u’nun kardeşleri olsun. u
alttaşmasını düzeltmek için iki yol vardır:
Anahtarlar, u, v ve w arasında dağıtılabilir; veya,
u, v,
ve w iki düğüm halinde birleştirilir, ve u, v ve w anah-
tarları bu düğümler arasında dağıtılabilir.
Bu işlem sonrasında etkilenen düğümlerin her birinin (en fazla 3
adet), herhangi bir
sabiti için, en az
ve en çok
anahtar sahibi olduğunu gösterin.
3. m işlem sırasında, bu değişikliklerle gerçekleştirilen birleştirme, ödünç alma, ve bölünme sayısının O(m/B) olduğunu gösterin.
Alıştırma 14.8. Şekil 14.11’de gösterilen B+-Ağacı, her bir anahtarı
bir yaprakta tutar, ve yaprakları Çifte-Bağlantılı Liste olarak depolar. Her zamanki gibi, her yaprak B – 1 ve 2B – 1 arası bir sayıda
anahtar depolar. Sonuncusu dışında, her yaprağın en büyük değerini depolayan B-Ağacı, bu listenin yukarısında yer alır.
| 493
1.
B+-Ağacı
üzerinde, ekle(x), sil(x) ve bul(x) işlemlerinin hızlı
uygulamalarını nasıl gerçekleştirebileceğinizi anlatın.
2.
B+-Ağacı
üzerinde x’ten daha büyük, ve y’den daha küçük ve-
ya eşit tüm değerleri bildiren findRange(x, y) işlemini verimli olarak nasıl uygulayabileceğinizi açıklayın.
3.
bul(x), ekle(x), sil(x)
ve findRange(x, y) işlemlerini gerçek-
leştiren BPlusTree sınıfını uygulayın.
4.
B+-Ağacı,
bazı anahtarları çoğaltır, çünkü hem B-Ağacı’nda,
hem listede, her ikisinde de depolanır. B’nin büyük değerleri için
anahtar çoğaltılmasının neden çok fazla pahalı olmadığını açıklayın.
SON
494|
| 495
Kaynakça (Bibliography)
[1] Free eBooks by Project Gutenberg. Available from:
http://www.gutenberg.org/
[cited 2011-10-12].
[2] IEEE Standard for Floating-Point Arithmetic. Technical report,
Microprocessor Standards Committee of the IEEE Computer Society, 3
Park Avenue, New York, NY 10016-5997, USA, August 2008.
doi:10.1109/IEEESTD.2008.4610935.
[3] G. Adelson-Velskii and E. Landis. An algorithm for the organization
of information. Soviet Mathematics Doklady, 3(1259-1262):4, 1962.
[4] A. Aggarwal and J. S. Vitter. The input/output complexity of sorting
and related problems. Communications of the ACM, 31(9):1116–1127,
1988.
[5] A. Andersson. Improving partial rebuilding by using simple balance
criteria. In F. K. H. A. Dehne, J.-R. Sack, and N. Santoro, editors,
Algorithms and Data Structures, Workshop WADS ’89, Ottawa, Canada,
August 17–19, 1989, Proceedings, volume 382 of Lecture Notes in
Computer Science, pages 393–402. Springer, 1989.
[6] A. Andersson. Balanced search trees made simple. In F. K. H. A.
Dehne, J.-R. Sack, N. Santoro, and S. Whitesides, editors,
Algorithms and Data Structures, Third Workshop, WADS ’93,
496|
Montreal, Canada, August 11–13, 1993, Proceedings, volume 709
of Lecture Notes in Computer Science, pages 60–71. Springer,
1993.
[7] A. Andersson. General balanced trees. Journal of Algorithms,
30(1):1–18, 1999.
[8] A. Bagchi, A. L. Buchsbaum, and M. T. Goodrich. Biased skip lists.
In P. Bose and P. Morin, editors, Algorithms and Computation, 13th
International Symposium, ISAAC 2002 Vancouver, BC, Canada,
November 21–23, 2002, Proceedings, volume 2518 of Lecture Notes in
Computer Science, pages 1–13. Springer, 2002.
[9] R. Bayer and E. M. McCreight. Organization and maintenance of
large ordered indexes. In SIGFIDETWorkshop, pages 107–141.
ACM, 1970.
[10] Bibliography on hashing. Available from: http://liinwww.ira.
uka.de/bibliography/Theory/hash.html
[cited 2011-07-20].
[11] J. Black, S. Halevi, H. Krawczyk, T. Krovetz, and P. Rogaway.
UMAC: Fast and secure message authentication. In M. J. Wiener, editor,
Advances in Cryptology - CRYPTO ’99, 19th Annual International
Cryptology Conference, Santa Barbara, California, USA, August 15–19,
1999, Proceedings, volume 1666 of Lecture Notes in Computer Science,
pages 79–79. Springer, 1999.
| 497
[12] P. Bose, K. Douieb, and S. Langerman. Dynamic optimality for skip
lists and b-trees. In S.-H. Teng, editor, Proceedings of the Nineteenth
Annual ACM-SIAM Symposium on Discrete Algorithms, SODA 2008, San
Francisco, California, USA, January 20–22, 2008, pages 1106– 1114.
SIAM, 2008.
[13] A. Brodnik, S. Carlsson, E. D. Demaine, J. I. Munro, and R.
Sedgewick. Resizable arrays in optimal time and space. In Dehne et al.
[18], pages 37–48.
[14] J. Carter and M. Wegman. Universal classes of hash functions.
Journal of computer and system sciences, 18(2):143–154, 1979. [15] D.
Comer. The ubiquitous B-tree. ACM Computing Surveys, 11(2):121–137,
1979.
[16] C. Crane. Linear lists and priority queues as balanced binary trees.
Technical Report STAN-CS-72-259, Computer Science Department,
Stanford University, 1972.
[17] S. Crosby and D.Wallach. Denial of service via algorithmic
complexity attacks. In Proceedings of the 12th USENIX Security
Symposium, pages 29–44, 2003.
[18] F. K. H. A. Dehne, A. Gupta, J.-R. Sack, and R. Tamassia, editors.
Algorithms and Data Structures, 6th International Workshop, WADS ’99,
Vancouver, British Columbia, Canada, August 11–14, 1999,
Proceedings, volume 1663 of Lecture Notes in Computer Science.
Springer, 1999.
498|
[19] L. Devroye. Applications of the theory of records in the study of
random trees. Acta Informatica, 26(1):123–130, 1988.
[20] P. Dietz and J. Zhang. Lower bounds for monotonic list labeling. In
J. R. Gilbert and R. G. Karlsson, editors, SWAT 90, 2nd Scandinavian
Workshop on Algorithm Theory, Bergen, Norway, July 11–14, 1990,
Proceedings, volume 447 of Lecture Notes in Computer Science, pages
173–180. Springer, 1990.
[21] M. Dietzfelbinger. Universal hashing and k-wise independent
random variables via integer arithmetic without primes. In C. Puech and
R. Reischuk, editors, STACS 96, 13th Annual Symposium on Theoretical
Aspects of Computer Science, Grenoble, France, February 22–24, 1996,
Proceedings, volume 1046 of Lecture Notes in Computer Science, pages
567–580. Springer, 1996.
[22] M. Dietzfelbinger, J. Gil, Y. Matias, and N. Pippenger. Polynomial
hash functions are reliable. InW. Kuich, editor, Automata, Languages and
Programming, 19th International Colloquium, ICALP92, Vienna,
Austria, July 13–17, 1992, Proceedings, volume 623 of Lecture Notes in
Computer Science, pages 235–246. Springer, 1992.
[23] M. Dietzfelbinger, T. Hagerup, J. Katajainen, and M. Penttonen. A
reliable randomized algorithm for the closest-pair problem. Journal of
Algorithms, 25(1):19–51, 1997.
| 499
[24] M. Dietzfelbinger, A. R. Karlin, K. Mehlhorn, F. M. auf der Heide,
H. Rohnert, and R. E. Tarjan. Dynamic perfect hashing: Upper and lower
bounds. SIAM J. Comput., 23(4):738–761, 1994.
[25] A. Elmasry. Pairing heaps with O(loglogn) decrease cost. In
Proceedings of the twentieth Annual ACM-SIAM Symposium on Discrete
Algorithms, pages 471–476. Society for Industrial and Applied
Mathematics, 2009.
[26] F. Ergun, S. C. Sahinalp, J. Sharp, and R. Sinha. Biased dictionaries
with fast insert/deletes. In Proceedings of the thirty-third annual ACM
symposium on Theory of computing, pages 483–491, New York, NY,
USA, 2001. ACM.
[27] M. Eytzinger. Thesaurus principum hac aetate in Europa viventium
(Cologne). 1590. In commentaries, ‘Eytzinger’ may appear in variant
forms, including: Aitsingeri, Aitsingero, Aitsingerum, Eyzingern.
[28] R.W. Floyd. Algorithm 245: Treesort 3. Communications of the
ACM, 7(12):701, 1964.
[29] M. Fredman, R. Sedgewick, D. Sleator, and R. Tarjan. The pairing
heap: A new form of self-adjusting heap. Algorithmica, 1(1):111–129,
1986.
500|
[30] M. Fredman and R. Tarjan. Fibonacci heaps and their uses in
improved network optimization algorithms. Journal of the ACM,
34(3):596–615, 1987.
[31] M. L. Fredman, J. Komlos, and E. Szemeredi. Storing a sparse table
with 0 (1) worst case access time. Journal of the ACM, 31(3):538–544,
1984.
[32] M. L. Fredman and D. E. Willard. Surpassing the information
theoretic bound with fusion trees. Journal of computer and system
sciences, 47(3):424–436, 1993.
[33] I. Galperin and R. Rivest. Scapegoat trees. In Proceedings of the
fourth annual ACM-SIAM Symposium on Discrete algorithms, pages
165–174. Society for Industrial and Applied Mathematics, 1993.
[34] A. Gambin and A. Malinowski. Randomized meldable priority
queues. In SOFSEM98: Theory and Practice of Informatics, pages 344–
349. Springer, 1998.
[35] M. T. Goodrich and J. G. Kloss. Tiered vectors: Efficient dynamic
arrays for rank-based sequences. In Dehne et al. [18], pages 205–216.
[36] G. Graefe. Modern b-tree techniques. Foundations and Trends in
Databases, 3(4):203–402, 2010.
[37] R. L. Graham, D. E. Knuth, and O. Patashnik. Concrete
Mathematics. Addison-Wesley, 2nd edition, 1994.
| 501
[38] L. Guibas and R. Sedgewick. A dichromatic framework for
balanced trees. In 19th Annual Symposium on Foundations of Computer
Science, Ann Arbor, Michigan, 16–18 October 1978, Proceedings, pages
8–21. IEEE Computer Society, 1978.
[39] C. A. R. Hoare. Algorithm 64: Quicksort. Communications of the
ACM, 4(7):321, 1961.
[40] J. E. Hopcroft and R. E. Tarjan. Algorithm 447: Efficient algorithms
for graph manipulation. Communications of the ACM, 16(6):372–378,
1973.
[41] J. E. Hopcroft and R. E. Tarjan. Efficient planarity testing. Journal
of the ACM, 21(4):549–568, 1974.
[42] HP-UX process management white paper, version 1.3, 1997.
Available from:
http://h21007.www2.hp.com/portal/download/files/prot/files/STK/pdfs
/proc_mgt.pdf
[cited 2011-07-20].
[43] M. S. Jensen and R. Pagh. Optimality in external memory hashing.
Algorithmica, 52(3):403–411, 2008.
[44] P. Kirschenhofer, C. Martinez, and H. Prodinger. Analysis of an
optimized search algorithm for skip lists. Theoretical Computer Science,
144:199–220, 1995.
502|
[45] P. Kirschenhofer and H. Prodinger. The path length of random skip
lists. Acta Informatica, 31:775–792, 1994.
[46] D. Knuth. Fundamental Algorithms, volume 1 of The Art of
Computer Programming. Addison-Wesley, third edition, 1997.
[47] D. Knuth. Seminumerical Algorithms, volume 2 of The Art of
Computer Programming. Addison-Wesley, third edition, 1997.
[48] D. Knuth. Sorting and Searching, volume 3 of The Art of Computer
Programming. Addison-Wesley, second edition, 1997.
[49] C. Y. Lee. An algorithm for path connection and its applications.
IRE Transaction on Electronic Computers, EC-10(3):346–365, 1961.
[50] E. Lehman, F. T. Leighton, and A. R. Meyer. Mathematics for
Computer Science. 2011. Available from:
http://courses.csail.mit.edu/6.042/spring12/mcs.pdf
[cited 2012-09-
06].
[51] C. Mart´ınez and S. Roura. Randomized binary search trees. Journal
of the ACM, 45(2):288–323, 1998.
[52] E. F. Moore. The shortest path through a maze. In Proceedings of
the International Symposium on the Theory of Switching, pages 285–292,
1959.
| 503
[53] J. I.Munro, T. Papadakis, and R. Sedgewick. Deterministic skip
lists. In Proceedings of the third annual ACM-SIAM symposium on
Discrete algorithms (SODA’92), pages 367–375, Philadelphia, PA, USA,
1992. Society for Industrial and Applied Mathematics.
[54] Oracle. The Collections Framework. Available from:
http://download.oracle.com/javase/1.5.0/docs/guide/collections/
[cited 2011-07-19].
[55] Oracle. Java Platform Standard Ed. 6. Available from:
http://download.oracle.com/javase/6/docs/api/
[cited 2011-07-
19].
[56] Oracle. The Java Tutorials. Available from:
http://download.oracle.com/javase/tutorial/
[cited 2011-07-19].
[57] R. Pagh and F. Rodler. Cuckoo hashing. Journal of Algorithms,
51(2):122–144, 2004.
[58] T. Papadakis, J. I. Munro, and P. V. Poblete. Average search and
update costs in skip lists. BIT, 32:316–332, 1992.
[59] M. Patrascu and M. Thorup. Randomization does not help searching
predecessors. In N. Bansal, K. Pruhs, and C. Stein, editors,
Proceedings of the Eighteenth Annual ACM-SIAM Symposium on
Discrete Algorithms, SODA 2007, New Orleans, Louisiana, USA,
January 7–9, 2007, pages 555–564. SIAM, 2007.
504|
[60] M. Patrascu and M. Thorup. The power of simple tabulation
hashing. Journal of the ACM, 59(3):14, 2012.
[61] W. Pugh. A skip list cookbook. Technical report, Institute for
Advanced Computer Studies, Department of Computer Science,
University of Maryland, College Park, 1989. Available from:
ftp://ftp.cs.umd.edu/pub/skipLists/cookbook.pdf
[cited 2011-07-
20].
[62] W. Pugh. Skip lists: A probabilistic alternative to balanced trees.
Communications of the ACM, 33(6):668–676, 1990.
[63] Redis. Available from: http://redis.io/ [cited 2011-07-20].
[64] B. Reed. The height of a random binary search tree. Journal of the
ACM, 50(3):306–332, 2003.
[65] S. M. Ross. Probability Models for Computer Science. Academic
Press, Inc., Orlando, FL, USA, 2001.
[66] R. Sedgewick. Left-leaning red-black trees, September 2008.
Available from:
http://www.cs.princeton.edu/˜rs/talks/LLRB/LLRB.pdf
[cited
2011-07-21].
[67] R. Seidel and C. Aragon. Randomized search trees. Algorithmica,
16(4):464–497, 1996.
| 505
[68] H. H. Seward. Information sorting in the application of electronic
digital computers to business operations. Master’s thesis,
Massachusetts Institute of Technology, Digital Computer
Laboratory, 1954.
[69] Z. Shao, J. H. Reppy, and A. W. Appel. Unrolling lists. In
Proceedings of the 1994 ACM conference LISP and Functional
Programming (LFP’94), pages 185–195, New York, 1994. ACM.
[70] P. Sinha. A memory-efficient doubly linked list. Linux Journal, 129,
2005. Available from: http://www.linuxjournal.com/article/6828
[cited 2013-06-05].
[71] SkipDB. Available from:
http://dekorte.com/projects/opensource/SkipDB/
[cited 2011-07-
20].
[72] D. Sleator and R. Tarjan. Self-adjusting binary trees. In Proceedings
of the 15th Annual ACM Symposium on Theory of Computing, 25–
27 April, 1983, Boston, Massachusetts, USA, pages 235–245.
ACM, ACM, 1983.
[73] S. P. Thompson. Calculus Made Easy. MacMillan, Toronto, 1914.
Project Gutenberg EBook 33283. Available from:
http://www.gutenberg.org/ebooks/33283
[cited 2012-06-14].
506|
[74] P. van Emde Boas. Preserving order in a forest in less than
logarithmic time and linear space. Inf. Process. Lett., 6(3):80–82,
1977.
[75] J. Vuillemin. A data structure for manipulating priority queues.
Communications of the ACM, 21(4):309–315, 1978.
[76] J. Vuillemin. A unifying look at data structures. Communications of
the ACM, 23(4):229–239, 1980.
[77] D. E.Willard. Log-logarithmic worst-case range queries are possible
in space _(N). Inf. Process. Lett., 17(2):81–84, 1983.
[78] J. Williams. Algorithm 232: Heapsort. Communications of the ACM,
7(6):347–348, 1964.
")