TÜRKÇE İÇİN KONUŞMA SENTEZLEYİCİ TASARIMI
VE DOĞALLIK ARTIRMA ÇALIŞMALARI
İsmail KURNAZ
Erdem ERKAN
Bartın Üniversitesi
Karabük Üniversitesi
Bilgisayar Mühendisliği Bölümü
Uzaktan Eğitim Uygulama ve Araştırma Merkezi
ikurnaz@karabuk.edu.tr
erdemerkan@bartin.edu.tr
Özet
Metinden konuşma sentezleyici sistemlerin popülerliği ve uygulama alanları gün geçtikçe
artmaktadır. Konuşma sentezleyicilerde kalite faktörü metinden oluşturulan konuşmanın
doğal insan sesine olan yakınlığı ile doğru orantılıdır. Konuşmadaki vurgu ve tonlamalar
da doğallığı etkileyen faktörlerdir. Bu çalışmada, dijital ortamdaki Türkçe metinleri ses
sinyallerine dönüştürebilen akıcı, anlaşılır bir Türkçe metin sentezleyici yazılımı
geliştirilmiştir. Geliştirme aşamasında Türkçede kullanılması muhtemel 900 adet ikili,
bunlara ek olarak da en temel üçlü ve dörtlü sesler belirlenmiştir. Belirlenen her bir ses için
taşıyıcı kelimler seçilmiş ve bu taşıyıcı kelimeler stüdyo ortamında seslendirilmiştir.
Belirlenen sesler taşıyıcı kelimelerinden ayrılarak ses veritabanı oluşturulmuştur. Yazılım,
veritabanındaki sesleri belli kurallar çerçevesinde, seslendirilmesi istenen metine göre
birleştirilerek, konuşma üretmektedir. Konuşmanın doğallığını artırmak için konuşma
üretimi sırasında Türkçe dil yapısına göre cümleyi oluşturan sesler üzerinde, cümle ve
kelime yapısı temel alınarak belli değişiklikler yapılmaktadır. Geliştirilen uygulama
sayesinde klavyeden girilen Türkçe metinler anlaşılabilir şekilde seslendirilebilmekte,
vurgu ve tonlama benzeri parametreler üzerlerinde değişlikler yapılabilmektedir.
Anahtar Kelimeler: Metinden Konuşma Sentezleme (MKS), Metin Seslendirme
1
DESIGN FOR TURKISH SPEECH SYNTHESİZER
AND IMPROVEMENT WORKS NATURALNESS
Abstract
Popularity and application areas of text to speech synthesizer systems are increasing day
by day. Quality factor is directly proportional to the speech synthesizers proximity to the
natural human speech sound created from the text. Accents and intonation in speech are
factors that affect the natural. In this study, fluent and understandable Turkish text to
speech software has been developed which can convert Turkish texts to audio signals in
digital media. In the pipe line, 900 double, in addition to their most basic triple and
quadruple sound determined which likely to be used in Turkish. Carrier words determined
for each selected sound and these carrier words were spoken in a studio environment.
Designated sounds seperated from carrier words then sound database has been created.
Software, combines the sounds of the database and the desired text to spoken in
accordance with certain rules then produces speech. To improve the naturalness of speech,
based on the structure of words and sentences; certain changes are made on the sounds that
make up the sentence according to the structure of Turkish language, during the production
of speech. With the applications developed, Turkish text entered from the keyboard can be
vocalized in an understandable way and changes can be made on parameters like accent
and intonation.
Key Words: Text-to-Speech Synthesis (TTS), Speech Synthesis
2
1. GİRİŞ
Metinden konuşma sentezleyiciler (MKS), bilgisayar ortamındaki metinleri ses sinyallerine
dönüştürme işlemini gerçekleştiren yazılımlardır. Konuşma motoru yazılı bir metni alır ve
bunun konuşma dilindeki ses olarak çıktısını üretir. Bir metnin bilgisayar tarafından
okunmasının pek çok uygulama alanı vardır. Bu alanların en başında görme veya konuşma
engelli kişilerle iletişim, insan-makine etkileşimi, sesli uyarı sistemleri, elektronik mail
veya kitap okuma ve yabancı dil öğrenimi gelmektedir. Bu konudaki çalışmalar ilk olarak
1976 yılında başlamıştır.
Görme engellilere yönelik olarak dünyadaki en muhteşem buluş, yazılı bir metni, bir
makinanın üzerine koymak ve onu duymaktır. Braille kullanmadan, bir başkasına
okutmadan bir kitabı okumaktır. Bunu Raymond Kurzweil başarmıştır. Bu, Braille'den
buyana başarılmış en büyük buluştur. Massachussetts Teknoloji Enstitüsü'nde mühendis
olan Raymond Kurzweil, 1976'da basılı metni yüksek sesle okuyabilen bir makine
tasarlamış, üretmiş ve piyasaya sürmüştür[1].
Türkçe metinden konuşma sentezleme çalışmaları ise 90’lı yıllardan itibaren akademik
alanda başlamış olup; günümüzde farklı araştırmacılar tarafından gerek akademik, gerekse
ticari amaçlar doğrultusunda yürütülmektedir[2].
Bu çalışmada da 3.parti yazılımlardan tamamen bağımsız, gerekli olan tüm sinyal işleme,
filtreleme vb. işlemlerde özgün kodlama kullanılarak tasarlanmış bir Türkçe metin
sentezleyicinin tasarlanması amaçlanmıştır.
2. KONUŞMA SENTEZLEME SİSTEMLERİNİN GENEL YAPISI
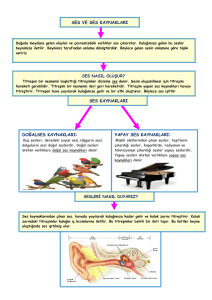
Konuşma sentezleyiciler girdi olarak aldığı metinleri ses sinyali olarak çıktıya dönüştüren
yapılardır. Bu çıktılar sonucunda girdi olarak alınan metin bilgisi istenilen dilde
konuşmaya çevrilmiş olur. Genel bir konuşma sentezleyici blok şeması aşağıdaki
şekildedir.
3
Şekil 1: Konuşma Sentezleyici Blok Şeması.
3. KONUŞMA SENTEZLEME TEKNİKLERİ
Bir konuşma sentezleyici siteminin en önemli özelliği doğallık ve anlaşılabilir olmasıdır.
Doğallık çıktının insan konuşmasına ne kadar yakın olduğunu tarif ederken anlaşıla bilirlik
çıktının ne kadar kolay algılanabildiğinin ölçüsüdür.
Konuşma sentezleme genel olarak Söyleyiş Sentezleme (Articulatory Synthesis), Formant
Sentezleme (Formant Synthesis) ve Eklemeli Sentezleme (Concatenative Synthesis) olmak
üzere üç ana başlık altında incelenebilir.
3.1. Söyleyiş Sentezleme (Articulatory Synthesis):
Bu tarz sentezleme yaklaşımı genel olarak insan ses organlarının modellenmesini temel
almaktadır. Söyleyiş Sentezleyiciler insan konuşma sisteminin nörofizyolojik ve
biyomekaniksel açıdan modellenmesini temel alır. Bu teknik diğer teknikler arasında daha
az gelişmiş bir teknik olsa da, detaylı ses dalgası üretimi için diğerlerinden daha doğru bir
seçim olduğu izlenimini vermektedir. Söyleyiş sentezleme belki de insanın vokal
organlarını bütünüyle modellenmesinin zorluğu hesaba katılmadan kesin bir sentezleme
olarak tanıtılmıştır. Ses bilimciler henüz tam anlamıyla Söyleyiş sentezleyiciyi destekleyen
bir model bulunmadığı konusunda hemfikirdir [3].
3.2. Birleştirmeli Sentezleme (Concatenative Synthesis):
Birleştirici sentezlemenin önceden kayıt edilmiş ses parçacıklarının birbirlerine eklenerek
yeni bir konuşma üretilmesi temeline dayanır. Genel olarak birleştirici sentezleme en doğal
şekilde duyulan sentezlenmiş sesi üretir. Ancak konuşmadaki doğal varyasyonlar
arasındaki farklar ve ses dalgalarının bölünmesi için kullanılan otomatikleştirilmiş
tekniklerin doğasından dolayı bazen elde edilen çıktıda sorunlar ortaya çıkmaktadır [4].
4
3.3. Formant Sentezleme (Formant Synthesis):
Kural temelli sentezleme olarak da adlandırılmaktadır. Teknik yapısı itibariyle doğadaki
tüm seslerin üretilmesine olanak sağlamaktadır. Diğer tekniklerde olduğu gibi ses
örneklerinden oluşan bir veri tabanına ihtiyaç duymaz. Dolayısıyla formant sentezleyiciler
daha az hafıza gereksinimi duyan aynı zamanda da çok fazla hesaplama yükü taşıyan
sistemlerdir.
Formant
sentezleyicilerin
yapısı
basitçe
“Kaynak-Filtre”
temeline
dayanmaktadır. Bu temel yapıda kaynak olarak bir osilatör veya benzeri bir sinyal üreteci,
filtre olarak ise bilinen temel filtreler kullanılmaktadır. Kaynaktan üretilen ses sinyali belli
bir sesi üretmek amacıyla modellenmiş (paralel veya seri bağlanarak) filtre gurubundan
geçirilerek ses üretimi yapılmaktadır [3,5,6].
4. TÜRKÇE KONUŞMA SENTEZLEYİCİ TASARIMI
Türkçenin yazıldığı gibi okunan dillerden olması konuşma sentezlemede bir avantaj olarak
karşımıza çıkmaktadır. Türkçede de her ne kadar seslendirilmesi istenen metin seslendirme
öncesi noktalama işaretleri, birimler, kısaltmalar vb. yapıların doğru okunması için bir ön
işlemden geçirilse de yazılış ve okunuşun aynı olması bu ön işlem yükünü azalmaktadır.
Yapılan
çalışmada
konuşma
sentezleyici
tasarımında
Birleştirmeli
Sentezleme
(Concatenative Synthesis) tekniği kullanılmıştır. Birleştirmeli sentezleme de en küçük ses
birimi fonem(tek ses) olarak adlandırılır. Ancak yalnız fonemlerin birleştirilmesiyle
geliştirilecek bir sistem çok fazla birleştirme gerektireceğinden, birleştirmeden
kaynaklanan olumsuzluklarda artacaktır. Kelimeleri ses birimi olarak kaydedip bu kelime
seslerini birleştirmek suretiyle konuşma üretilmesi de seçenekler arasındadır. Yalnız bu
şekilde geliştirilecek sistemin veritabanı barındırdığı kelimelerle sınırlı olacağından bizlere
makul bir çözüm sunmamaktadır. Bu noktada günümüzde de en çok kullanılan ikili
seslerin (difon) birleştirme elemanı olarak kullanılması, Türkçeye has bazı özel durumlarda
bu ikili seslerin üçlü hatta dörtlü seslerle desteklenmesinin en iyi doğal sonucu vereceği
düşünülmüştür.
5
4.1. Birleştirmede Kullanılacak Seslerin Belirlenmesi
Türkçede 8 sesli 21 sessiz olmak üzere toplam 29 harf mevcuttur. Çalışmada ikili sesler
temel alındığı için bu 29 harfin ikili kombinasyonu uygulamanın ses veritabanı için çıkış
noktası olmuştur. Ancak mevcut 8 sesli harfin normal okunuşlarının dışında uzun, ince,
kalın, yumuşak vb. okunuş şekilleri de vardır. Basitçe “Kar” ve “Kâr” kelimeleri a sesinin
2 farklı okunuşuna örnek gösterilebilir. Türkçedeki sesli harflerin farklı okunuşları Tablo 1
‘de gösterilmiştir [7].
İşte bu farklı okunuşlar veritabanındaki olması gereken ses elemanlarının sayısını
artırmaktadır. Yapılan çalışmada ikili sesler temel alındığından, yapı itibariyle ikili seslerin
birleştirilmesiyle oluşturulabilecek üçlü ve dörtlü seslerde yine ikili seslerin birleşiminden
elde edilmiştir. Belirlenen sesler için taşıyıcı kelimler tespit edilmiş ve tespit edilen taşıyıcı
kelimeler seslendirilerek kayıt altına alınmıştır. Veritabanını oluşturacak sesler bir ses
(fonem) için yaklaşık 75 ms (yaklaşık 3000 örnek) standart alınarak taşıyıcı kelimelerden
çıkarılmış ve ses veritabanı oluşturulmuştur.
Tablo 1: Türkçedeki sesli harflerin okunuş farklılıkları [7].
4.2. Birleştirme Noktalarının Belirlenmesi
Bilindiği gibi her dilde kelimeler sesli ve sessiz harflerin birleşiminden oluşmaktadır.
Ancak sesli harflerin diğer harflerden farklı olan periyodiklik özelliği, sesli harflere sessiz
harfleri birleştirici bir görev yüklemektedir. Şekil 2 ve Şekil 3 ‘de sırasıyla “sa” ve “pa”
6
ikili sesleri görülmektedir. Her iki ikili ses gurubunda da ortak olan sesli harf olan “a”
sesinin periyodikliği, sessiz harf olan “s” ve “p” seslerinin periyodik olmadığı
görülmektedir.
1
0.5
0.8
0.6
0
0.4
0.2
0
-0.5
-0.2
-0.4
-0.6
0
1000
2000
3000
4000
5000
6000
-1
7000
Şekil 2: “sa” ikili ses sinyali.
0
1000
2000
3000
4000
5000
6000
7000
Şekil 3: “pa” ikili ses sinyali.
Periyodik olan sesli harflerin olumsuz birleştirme sonuçlarını en aza indireceğinden
düşünülerek
birleştirme
işlemleri
sesli
harfler
üzerinden
yapılmıştır.
Öncelikle
seslendirilmesi istenilen metin cümlelere, kelimelere ve hecelere ayrılmıştır. Hecelere
ayrılan kelimelerin hangi ikili seslerden oluşacağı belirlenmiş, belirlenen ikili sesler
birleştirilerek kelimeleri ifade eden sesler oluşturulmuştur. Örnek olarak “bayrak” kelimesi
bay-rak olarak hecelerine ayrılmış, heceler de ba+ay-ra+ak şeklinde kendilerini oluşturan
ikili seslere ayrılmıştır. İkili sesler Aynı heceye ait olanlar %50 oranında örtüştürülmek
suretiyle birleştirilmiş ve böylece seslendirme gerçekleşmiştir.
4.2. Tonlama ve Vurgu Çalışmaları
Seslendirilmesi istenilen metinler cümle, kelime, hece ve ses sınıflarına atanmaktadır. Bu
hiyerarşik sınıflandırma ile her ses sınıfının, cümlenin hangi kelimesinin hangi hecesinde
kaçıncı sırada bulunduğu bilinmektedir. Bu sayede birleştirme işlemi esnasında istenilen
ses guruplarına cümle ve kelime yapısı çerçevesinde birleştirme ve sinyal genlik oranı
değişiklileri yapılabilmektedir. Örnek olarak sonunda soru işareti olan bir cümlenin
istenilen kelimelerinin yine istenilen seslerine genlik artırımı yapılabilmekte, sonunda
virgül olan bir kelimeye yarım ses bekleme süresi eklenebilmektedir. Örnek olarak
“gidiyor musun.” ve “gidiyor musun?” kelimelerinin okunuşları sonlarındaki noktalama
işaretlerine göre bazı farklılıklar kazanmışlardır. Uygulamanın vurgu modülü sayesinde
7
sonu noktalı olan “gidiyor musun?” kelimesi düz bir tonlamada, seri bir şekilde
seslendirilirken, sonunda soru işareti olan “gidiyor musun?” kelimesinin diğerinden %60
daha
vurgulu
ve
“musun”
parçasının
sesinin
%50
oranında
alçaltılarak
seslendirilebilmektedir.
Gidiyor →musun→ .
Gidiyor↑musun↓ ?
Bu ve benzeri parametrelerle uygulamanın doğallığının artırılması amaçlanmıştır. Şekil 4
‘de sentezleme sonrası kaydedilmiş örnek bir cümle gösterilmiştir.
1
0.5
0
-0.5
-1
0
1
2
3
4
5
6
7
8
9
10
4
x 10
Şekil 4: Sentezlenen ”Bu gün hava ne kadar güzel değil mi?” cümlesi.
5. KONUŞMA KALİTESİNİN DEĞERLENDİRİLMESİ
MOS (Mean Opinion Score), ses iletişiminde, özelliklede internet telefonlarında iletilen
ses kalitesi hakkında bir karara varmak için kullanılan bir test yöntemidir. MOS iletilen
sesin kalitesi hakkında sayısal bir ölçü sunmaktadır. Testin uygulanmasında dinleyicilere
birtakım sesler dinletilir ve kendilerinden bu seslerin 5-Mükemmel, 4-İyi, 3-Orta, 2-Kötü,
1-Çok Kötü şeklinde puanlamaları istenir. Tüm puanların aritmetik ortalaması sistemin
genel puanını verir. Sistem MOS değerlendirme sistemiyle değerlendirilen bir teste tabi
tutulmuştur. Görme engelli ve görme engelli olmayan toplam 25 kişilik bir grup üzerinde
5 cümle ile yapılan değerlendirme sonucunda konuşma sentezleyici 5 tam puan üzerinden
4,00 puan almıştır.
8
6. SONUÇLAR
Bu çalışmada Türkçe metinler için kullanılabilecek TURS adlı, basit ve esnek yapılı bir
konuşma sentezleyici geliştirilmiştir. Sentezleyici eklemeli sentezleme yapısına en uygun
en küçük ses birimlerini kullanarak düşük maliyetli bir veri tabanı kullanmaktadır.
Geleneksel konuşma sentezleyici sistemler yaklaşık 150 megabaytlık bir veritabanına
ihtiyaç duyarken TURS konuşma sentezleyici veritabanı 17 megabayt veritabanına
sahiptir.
Sentezlenen konuşmanın doğallığını artırma amaçlı çalışmalar yapılmıştır. Kodlamanın 3.
parti yazılımlardan bağımsız olarak tek bir sınıf dosyası olarak kullanılabilmesi
uygulamanın farklı platformlara taşınmasında avantaj sağlayacağı düşünülmektedir.
Geliştirme aşamasında karmaşık yöntemler yerine kolay anlaşılır, uygulaması kolay
yöntemler seçilmiştir.
Bu aşamadan sonra çalışmaya ilave edilecek bilgisayar öğrenme teknikleri sayesinde
sentezlenen konuşmaya duygusal insansı ifadeler katmak amaçlanmaktadır.
9
7. Kaynaklar
1. Subaşıoğlu,
F.
(2000).
“Engellilerin
Internet’e
Erişimi
Üzerine”,
Türk
Kütüphaneciliği, 14 (2), 188-204.
2. Sel, İ., Hanbay, D., Karbatak, M. (2011). “Beyin Bilgisayar Arayüzleri için Türkçe
Metinden Konuşma Sentezleme Sistemi”, Elektrik-Elektronik ve Bilgisayar
Sempozyumu
3. Tatham, M. and Morton, K., “Developments in Speeech Synthesis”, John Wiley &
Sons Ltd, England, 23-25 (2005).
4. Huang, X., Acero, A., Hon, H.W. (2001). Spoken Language Processing: A Guide to
Theory, Algorithm and System Development. New Jersey: Prentice Hall PTR.
5. Ünaldı, İ. (2007). “Taşınabilir Cihazlar İçin Türkçe Metinden Konuşma Sentezleme
Sistemi”, Yüksek Lisans Tezi, Hacettepe Üniversitesi, Fen Bilimleri Enstitüsü,
Ankara.
6. Eker, B., “Turkish text to speech system”, Yüksek Lisans Tezi,
Bilkent
Üniversitesi Mühendislik ve Fen Bilimleri Enstitüsü, Ankara, 19-20 (2002).
7. Canal, Ş. M., Kurnaz, S. ve Yılmaz, E., “Türkçe metinden konuşma sentezlemede
yaşanan sıkıntılar ve çözüm yöntemleri”, Havacılık ve Uzay Teknolojileri Dergisi,
4 (10): 47-55 (2010).
10