Uploaded by
ebru_bekar
Discriminant Analysis: A Powerful Tool for Classification

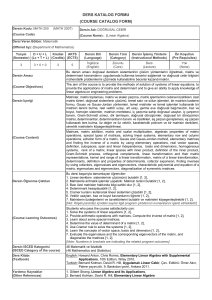
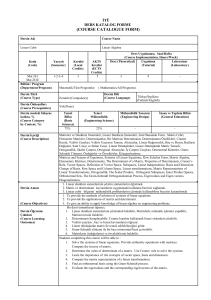
Discriminant Analysis: A Powerful Tool for Classification Discriminant Analysis (DA) is a statistical technique that enables the effective classification of observations or categories based on a specific set of predictor variables. By finding linear combinations of variables that best differentiate between different groups, DA empowers businesses, researchers, and organizations to make data-driven decisions and predictions through accurate classification. Ea by Ebru Bekar The Fundamentals of Discriminant Analysis Discriminant Functions Discriminant functions are Maximizing Between-Group Differences mathematical equations used to The primary objective of the classify observations into different discriminant function is to groups based on predictor maximize the differences between variables. These functions are the means of predictor variables derived from the characteristics of among different groups. This the data and aim to maximize the ensures a good separation in the difference between groups while feature space of groups and minimizing differences within facilitates accurate classification of groups. observations. Minimizing Within-Group Variability Establishing Decision Boundaries Another aim of the discriminant The discriminant function balances function is to minimize the between maximizing the difference variability of observations within between different classes and each group. By reducing within- minimizing within-group variability. group variability, the discriminant As a result, it establishes decision function can better distinguish boundaries that effectively classify between groups and improve the observations into their respective accuracy of classification. groups. Real-World Applications of Discriminant Analysis Market Segmentation Medical Diagnosis Credit Risk Assessment Determining consumer Classifying patients Predicting whether a segments based on into different disease credit applicant will demographic categories based on default or not based characteristics, symptoms, test on financial indicators. behaviors, or results, or biomarkers. preferences. Linear Discriminant Analysis (LDA) and Quadratic Discriminant Analysis (QDA) Choosing Between LDA and QDA Linear Discriminant Analysis (LDA) The choice between LDA and LDA is a classification technique QDA depends on the specific that assumes multivariate normal characteristics of the dataset and distribution within each group of the underlying distribution of the predictor variables. LDA aims to data. LDA is preferred when the find a linear combination of assumption of equal covariance features that best separates the matrices holds true, while QDA groups while maximizing the may be more suitable when this variance between groups and assumption is violated or when minimizing within-group variance. there is non-linearity in the data. 1 2 Quadratic Discriminant Analysis (QDA) QDA is a similar classification method to LDA but relaxes the assumption of homogeneous covariance matrices between groups. Unlike LDA, QDA allows for different covariance matrices for each group, allowing it to capture complex relationships 3 Key Assumptions and Considerations in Discriminant Analysis 1 Multivariate Normal Distribution 2 Homogeneity of Covariance Matrices 3 Independenc e of Observations This assumption This assumption This assumption states that states that assumes that observations are predictor covariance independent variables follow a matrices of within and multivariate predictor between groups. normal variables are Violations of this distribution within equal across all assumption, such each group. groups. as serial Violations of this Violations of this correlation or assumption can assumption can clustering of lead to biased lead to ineffective observations, can parameter discriminant lead to biased estimates and functions and parameter The Discriminant Analysis Workflow Data Preparation Collect and clean the data, dealing with missing values, outliers, and errors. Feature Selection Select relevant predictor variables for analysis, considering their importance and contributions. Data Transformation Standardize or normalize variables to ensure equal contributions and address distributional issues. Model Training Develop discriminant functions using appropriate techniques (e.g., LDA or QDA) based on the features of the data. Model Evaluation Assess the performance of the discriminant model using crossvalidation or other validation techniques. Interpretation Interpret the results, including the significance of predictor variables Validation Techniques for Discriminant Analysis Leave-One-Out Cross-Validation (LOOCV) K-Fold Cross-Validation Bootstrap Validation Divide the dataset into k Create multiple Train the model on all subsets, train the model bootstrap samples data except one on k-1 subsets, and test using repeated observation and test it it on the remaining sampling with on the remaining subset. Repeat this replacement from the observation, repeating process k times, using a dataset. Train the model this process for each different subset as the on each bootstrap observation. test set each time. sample and evaluate its performance on the original dataset. Challenges and Limitations in Discriminant Analysis 1 Assumption Violations 2 HighDimensional Problems 3 Overfitting When the When there are Overfitting occurs assumptions of more variables when a discriminant multivariate normality, than model captures noise homogeneity of observations, the or random fluctuations covariance matrices, analysis in the training data, and independence of becomes more resulting in poor observations are challenging, and generalization violated, the results of techniques like performance on discriminant analysis dimensionality unseen data. can be misleading. reduction may be necessary. The Future of Discriminant Analysis Advancements in Machine Learning As machine learning techniques continue to evolve, the integration of DA with these methods can lead to enhanced classification performance and the ability to Handling High-Dimensional Data handle more complex, non-linear Researchers relationships. are exploring ways to adapt DA to effectively handle highdimensional datasets, where the number of features far exceeds the number of observations, expanding Hybrid Approaches its applicability in the era of big Combining DA with other statistical data. and machine learning techniques, such as regularization methods and ensemble learning, can lead to more robust and accurate classification models, addressing Explainable AI the limitations of standalone DA. As the demand for interpretable and transparent machine learning models grows, the inherent interpretability of DA makes it a valuable tool in the development of explainable AI systems, bridging the gap between model performance and human