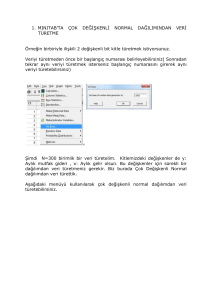
BSM-767 MAKİNE ÖĞRENMESİ
Makine Öğrenmesine Giriş ve Temel
Kavramlar
Yrd. Doç. Dr. Ümit ATİLA
umitatila@karabuk.edu.tr
http://web.karabuk.edu.tr/umitatilla/
Makine Öğrenmesi Nedir?
• Veri boyutunun büyüklüğü
insanların ondan faydalı bilgi
çıkarmasını zorlaştırır.
• Verinin sunuluş biçimi bile
bize anlamakta zor gelebilir.
• Sayılarla dolu bir dosya
içinde kaybolup gidebiliriz.
Ancak veriyi bir grafik
üzerinde görselleştirsek
daha anlaşılır olabilir.
2
Makine Öğrenmesi Nedir?
• İnsan 3 boyutlu hayatında 3
boyuttan yüksek boyuta
sahip verileri yorumlamakta
zorlanır.
• Bilgisayarlar için yüksek
boyutlu veri problem
oluşturmaz.
• Ya problemin boyutunu
azaltıp kendiniz çözersiniz
veya bilgisayara makine
öğrenmesi ile
çözdürürsünüz.
3
Makine Öğrenmesi Nedir?
• Örnek verileri ve geçmiş deneyimleri kullanarak
performans kriterini optimize etmektir.
• Makine öğrenmesinde verinin rolü
kaçınılmazdır.
• Öğrenme algoritması, veriden bilgi veya özellik
ortaya çıkarmak ve öğrenme için kullanılır.
• Veri setinin kalitesi ve büyüklüğü öğrenme ve
tahmin performansını etkileyecektir.
4
Genelleme (Generalization)
• Makine öğrenmesinde amaç genelleme
kapasitesine ulaşmaktır.
• Bir bilgisayarın bir problemin çözümü hakkında
yorum yapabilme kapasitesine ulaşmasıdır.
• Bilgisayar örnekler üzerinden öğrenir ve
görmediği örnekler hakkında doğru tahminlerde
bulunmaya çalışır (genelleme)
5
Makine Öğrenmesi Türleri
• Öğrenme, "pratik yaptıkça bir iş daha iyi
yapabilir hale gelmek" olarak ta
tanımlayabiliriz.
• Peki bilgisayar daha iyi bir konuma geldiğini
nasıl bilir ve kendisini daha iyi bir konuma nasıl
getirir?
• Bu sorunun cevabı bize farklı öğrenme türleri
ile verilir.
6
Makine Öğrenmesi Türleri
• Danışmanlı (Supervised) Öğrenme:
• Danışmansız (Unsupervised) Öğrenme:
• Reinforcement Öğrenme:
• Evrimsel Öğrenme:
7
Danışmanlı Öğrenme
• Sınıflandırma ve tahmin yöntemlerine
danışmanlı öğrenme yöntemleri de denilebilir.
8
Danışmanlı Öğrenme
Regresyon
• Bu değerlerin bir fonksiyondan
geldiğini kabul ederek bu fonksiyonun
ne olduğunu ortaya çıkarmak
istiyorsunuz.
• Böylece verilecek her hangi bir x
girişi için y çıkışının ne olduğunu
söyleyebileceksiniz.
• Genellikle fonksiyon yaklaşma veya
interpolasyon problemi olarak ta
tanımlanır.
9
Danışmanlı Öğrenme
Regresyon
• Bu tablodaki veriler için
kullanılabilecek birkaç
fonksiyon şekilde
verilmiştir.
• Sol üst: Noktaların
gösterimi,
• Sol alt: İki olası çözüm.
Noktaları doğrular ile
birleştirme (istenen şeyi
tam sağlamıyor) veya
(ax3+bx2+cx+d) şeklinde
kübik fonksiyon kullanma
(Birçok nokta için hata
yüksek).
10
Danışmanlı Öğrenme
Sınıflandırma
• N adet sınıftan birine ait olan örneklerle eğitim
yaparak giriş vektörlerinin N adet sınıftan
hangisine ait olacağını belirleme problemidir.
• Her örnek bir sınıfa aittir ve sınıflar kümesi
problem uzayında olası tüm girişler için
kullanılır.
• Bazı örnekler her hangi bir sınıfa dahil
edilemeyebilir.
11
Danışmanlı Öğrenme
Sınıflandırma
• Bozuk para tanıyan makine
• Özellik vektöründe yer
alabilecek parametreler
• Çap, ağırlık, şekil
(çoğaltılabilir)
• Hangi parametreleri
kullanmalıyız?
12
Danışmanlı Öğrenme
Sınıflandırma
• Farklı sınıflandırma algoritmalarının hepsinin amacı
karar sınırları (decision boundaries) belirlemektir.
• Şekilde soldaki doğrulardan oluşan karar sınırı,
sağdaki eğrilerden oluşan karar sınırına sahip
sınıflandırıcıya nazaran performansı kötüdür.
13
Makine Öğrenmesi Süreci
• 1-Veri Toplama ve Hazırlama
• 2-Özellik Seçimi
• 3-Algoritma Seçimi
• 4-Parametre ve Model Seçimi
• 5- Eğitim
• 6-Test
14
Terminoloji
• Öğrenme algoritmalarında giriş ve buna karşılık
çıkış vardır.
• Girişler: x = (x1,x2,…,xm) m boyutlu giriş vektörü
• Ağırlıklar: wij, i düğümünü j düğümüne bağlayan
ağırlıklandırılmış bağlantı. W ağırlık matrisinde
topluca belirtilirler.
• Çıkışlar: y = (y1,y2,…,yn) n boyutlu çıkış vektörü
• Hedef: t = (t1,t2,….,tn) n boyutlu hedef vektörü.
Danışmanlı öğrenmede kullanılan beklenen çıkış
değerlerinden oluşan vektördür.
15
Ağırlık Uzayı
• Elimizdeki veriler 2 ve 3 boyutlu
ise görselleştirme kolaydır.
• 3 boyuttan sonrası için sadece 3
tane özelliğin 3 boyutlu ortama
yansıması gözlenebilir.
• Veriler gibi başka büyüklüklerde
grafikte izlenebilir. Örneğin
makine öğrenmesi
algoritmalarında kullanılan
parametreler.
• Parametreler koordinat
düzleminde (Ağırlık Uzayı) temsil
edilebilir.
16
Boyut Sorunu
• Boyut arttıkça uzayda temsil edilen birim
hiperdüzlemin boyutu artmaz.
• Birim hiperdüzlem orijinden 1 birim uzaklıkta yer alan
noktaların birleştirilmesi ile elde edilen alandır.
• 2 boyutta (0,0) koordinatı etrafında çemberdir, 3
boyutta (0,0,0) etrafında küre.
• 3 boyuttan sonra hiperdüzlem elde edilir.
17
Boyut Sorunu
• 100 boyuta çıkıldığında elde
edilen hiper düzlemin
sınırının orijine uzaklığı 0.1'e
düşer.
• Böylece hiperdüzlemin
hacminin küçüldüğü anlaşılır.
• Hiperdüzlemin hacmi
formülü Vn = (2π / n) Vn-2
18
Boyut Sorunu
• Makine öğrenmesi algoritmaları için bunun
yorumu
• Giriş parametrelerinin boyutu arttıkça
algoritmanın iyi genelleme yapabilmesi için daha
fazla örneğe ihtiyaç duyulur.
• Sınıflandırmada parametre sayısı arttıkça başarılı
sınıflandırma için göstermemiz gereken örnek
sayısı da artar.
19
Makine Öğrenme Algoritmalarını
Test Etme
• Algoritmamızın ne kadar başarılı olduğunu
bilmek isteriz.
• Öğrenmenin performansını öngörebilmek için
Test Veri Seti kullanılır. Eğitim Veri seti ile
aynı dağılıma sahip olmalıdır.
20
Makine Öğrenme Algoritmalarını
Test Etme
• a, elimizdeki eğitim kümesi ve b ile c ise test kümeleri
• c kümesi, a ve b'den farklı dağılıma sahip. Bu durumda
a'dan öğrenilen özelliklerin c'de kullanılabilir olmasını
bekleyemeyiz.
21
Makine Öğrenme Algoritmalarını
Test Etme
• Bu 2 karar sınırı
eğitim kümesinde
%100 başarı
gösterirken, test
kümesinde daha
farklı bir davranış
sergilemekte.
22
Overfitting (Aşırı Uyum)
• Ne az eğitim ne de çok aşırısı işimize yaramaz.
• Eğer çok fazla eğitim gerçekleştirirseniz
veriye aşırı uyum gerçekleşir (ezberleme) yani
algoritma verideki gürültü ve yanlışlıklar da
öğrenilir ve genelleme yeteneğine zarar verilir.
23
Overfitting (Aşırı Uyum)
• Aşırı uyum gerçekleşmeden önce eğitimi
durdurmalıyız.
• Eğitimde her adımda ne kadar iyi genelleme
yapıldığına bakmalıyız.
• Bunun için eğitim veya test seti kullanılamaz.
• Validation set (değerlendirme verisi) gerekir.
24
Çapraz Geçerlik (Cross-validation)
• Genel olarak 3 veri setimiz vardır. Eğitim,
Değerlendirme ve Test.
• Elimizdeki verinin bu üç veri setine dağıtılması da
başarının tarafsızlığı için önemlidir.
• Bunun için cross-validation (çapraz geçerlik)
kuralları uygulanır.
• Üç tip çapraz geçerlik yöntemi önerilmiştir:
• Rasgele örnekleme
• K parçalı
• Birini hariç tut
25
Çapraz Geçerlik (Cross-validation)
Rasgele Örnekleme
• Rasgele örneklemede eğitim test ve değerlendirme
kümelerine rasgele örnekler seçilerek aktarılır.
• Çapraz geçerlik içerisinde en yüksek başarıyı
sağlayan yöntemdir.
26
Çapraz Geçerlik (Cross-validation)
K-Parçalı
• K parçalıda veri K adet kümeye ayrılır.
• Birisi test kümesi için ve biriside değerlendirme kümesi için
ayrılır diğer K-2 küme birleştirilip eğitim kümesi için seçilir.
• Bu işlem kümeler değiştirilerek K kez tekrarlanır.
• Genel başarı için K adet başarı değerinin ortalaması alınır.
27
Çapraz Geçerlik (Cross-validation)
Birini Hariç Tut
• K parçalının bir türüdür. Burada algoritma N
adet verinin bir tanesinde değerlendirilir N-1
tanesinde eğitilir.
• Her eğitimde bir tane örnek dışarıda bırakılır
ve diğerleri eğitimde kullanılır.
• K parçalı ve Birini Hariç tut yöntemlerinin
hesaplama maliyeti rasgele örneklemeden çok
yüksektir.
28
Karışıklık Matrisi
• Sınıflandırma algoritmalarının başarısını tayin etmek
için kullanılan bir yöntemdir.
• Karışıklık Matrisinde, satırları beklenen sınıfları ve
sütunları da tahmin edilen sınıfları temsil eden bir kare
matris oluşturulur.
• Matristeki diagonal veriler doğru olarak tahmin edilen
örnek sayılarıdır.
• Diagonalda yer alan sayıların matristeki toplam örnek
sayısına bölümü doğru sınıflandırma başarısını yüzde
olarak verir.
• Buna doğruluk (Accuracy) denir.
29
Doğruluk Ölçütleri
• Binary sınıflandırma problemlerinde olası sınıflar basit bir
tablo ile ifade edilebilir.
• Bu tabloda TrueProzitif Sınıf1'e dahil edilen ve gerçekte de
Sınıf1'e ait olan örnek sayısı, FalsePozitif ise yanlışlıkla
Sınıf1'e dahil edilen örnek sayısıdır.
• Benzer şekilde TrueNegatif Sınıf2'ye dahil edilen ve
gerçekte de Sınıf2'e ait olan örnek sayısı, FalseNegatif ise
yanlışlıkla Sınıf2'e dahil edilen örnek sayısıdır.
• Bu tabloda diagonal'de yer alanlar doğru sınıflandırmalar
diğerleri ise yanlış sınıflandırmalardır.
30
Doğruluk Ölçütleri
• Doğruluk (accuracy) ise şu
şekilde tanımlanır.
• Ancak sınıflandırıcı
performansını ifade etmek için
doğruluk tek başına
yetersizdir.
• Bir birine zıt iki çift ölçüt
sensivity ile specifity ve
Precision ile Recall
sınıflandırıcı performansını
ifade etmek için kullanılır.
31
Doğruluk Ölçütleri
• ROC (Receiver Operator Characteristic)
eğrisi, sınıflandırma başarısını yorumlamak ve
sınıflandırıcıları karşılaştırmak için kullanılır.
• TruePozitif örneklerin oranının, FalsePozitif
örneklerin oranına göre nasıl değiştiğini
gösterir.
• Sınıflandırıcının bir kez çalıştırılması ROC
grafiğinde bir nokta bırakır. Bu nokta (0,1) ise
%100 TP ve %0 FP olduğu anlamına gelir.
• Her şeyi yanlış sınıflandıran bir sınıflandırıcı
ise (1,0) noktasındadır.
• Böylece ne kadar sol üst tarafta isek o kadar
başarılıyız demektir.
32
Doğruluk Ölçütleri
• ROC grafiğinde bir nokta yerine eğri elde
etmenin yolu çapraz geçerlilik uygulamaktır.
• Eğer veri seti 10'a bölünürse 10 farklı test
setinde 10 farklı sınıflandırma sonucu elde
edersiniz ve bir eğri oluşturabilirsiniz.
• Her sınıflandırıcı için bu şekilde ROC eğrileri
elde edilerek sınıflandırıcılar karşılaştırılabilir.
33
Dengeli Olmayan Veri Setileri için
Doğruluk Ölçütü
• Genelde veri setleri dengeli değildir.
• Dengeli olmayan veri setlerinde dengeli doğruluğu
hesaplamak için Sensivity ve Specifity toplanıp 2'ye
bölünebilir.
• Ancak daha doğru bir ölçü kullanmak isterseniz bu
durumda kullanılabilecek uygun doğruluk ölçüsü
Matthew Benzerlik Katsayısıdır (MCC).
34
Temel İstatistik Kavramları
Ortalamalar
• Mean (μ): Örneklerin ortalamasıdır. Örnek
toplamının örnek adedine bölümüdür.
• Medyan: Bir örnek setindeki ortanca değerdir.
Çift sayıda örnek varsa ortaya en yakın iki
örneğin ortalamasıdır. Önce kümedeki örnekler
büyüklüğe göre sıralanır.
• Mod: Bir örnek setindeki örneklerden frekansı
en fazla olanın frekans (küme için kaç adet
bulunuyor) değeridir.
35
Temel İstatistik Kavramları
Varyans-Kovaryans
• Beklenen değer (Expected Value-E): Bir grup
sayının beklenen değeri onların ortalamasıdır.
• Varyans (σ2): Bir örnek kümesindeki değerlerin
dağılımını gösterir. Örnek değerleri ile örnek
kümesinin beklenen değeri (mean) arasındaki
farkların kareleri toplamıdır.
• Standart Sapma (σ): Varyansın kareköküdür.
36
Temel İstatistik Kavramları
Varyans-Kovaryans
• Kovaryans: Varyans bir örneğin ortalamaya göre değişimine
bakar. Kovaryans ise iki örneğin birbirine göre değişimine
bakar.
• Kovaryans hesaplanırken iki ayrı örnek kümesindeki
örneklerin kendi kümelerinin ortalama değerlerinden
farklarının beklenen değeri çarpılır.
• Eğer iki örnek bağımsız ise kovaryans sıfırdır yani örneklerin
korelasyonsuzdur.
• Yani örneklerin ikisi de aynı anda artıyor ve azalıyorsa
kovaryans pozitiftir. Biri artıyorken diğeri azalıyorsa
negatiftir.
37
Temel İstatistik Kavramları
Varyans-Kovaryans
• Kovaryans, bir veri setindeki tüm veri çiftleri arasındaki korelasyona bakmak için
kullanılabilir.
• Bunun için tüm örnek çiftlerinin kovaryansı hesaplanır ve bunlar kovaryans matrisi
denilen matrise yerleştirilir.
• Burada xi, i. örneğin elemanlarını tanımlayan sütun vektörü, μi ise bu sütun vektördeki
elemanların mean değeri.
• Matris kare matristir. Diagonal elemanlar varyansları verir ve matris simetriktir yani
cov(xi,xj) = cov(xj,xi)
• X'in mean değeri E(X) olarak düşünüldüğünde bu matris aşağıdaki şekilde ifade
edilebilir.
38
Temel İstatistik Kavramları
Varyans-Kovaryans
• Kovaryans bize veri hakkında ne söyler?
• Esas olarak verinin her boyuta göre nasıl değiştiği bilgisini verir.
• Şekilde görülen veri setleri ve bir X test noktası görülüyor. Burada
X verinin bir parçası mıdır diye sorulsa. Muhtemelen soldaki için
evet, sağdaki için hayır dersiniz.
• Bu cevabı verirken verinin ortalamasına baktığınız gibi test
noktasının gerçek veri dağılımının neresinde olduğuna da bakarsınız.
39
Temel İstatistik Kavramları
Varyans-Kovaryans
• Eğer veri belli bir nokta etrafında sıkı bir şekilde toplanmış
olsaydı, test noktasının bu merkeze ne kadar mesafede
olduğuna bakardınız.
• Eğer veri merkez etrafında toplanmak yerine yayılmış
olsaydı. Test noktasının merkeze olan mesafesi çok önemli
olmayacaktı.
• Bu fikri hesaba alan bir mesafe ölçüsü vardır. Mahalanobis.
• Burada x, sütun vektörü olarak
alınan
veri
noktası,
μ
mean'i
veren sütun vektörü ve 𝛴 −1 ise kovaryans matrisinin tersidir.
• Eğer kovaryans matrisi, birim matris olarak ayarlanırsa bu
durumda Mahalanobis mesafesi Öklit mesafesine dönüşür.
40
Temel İstatistik Kavramları
Gauss Dağılımı
• En iyi bilinen olasılık dağılımıdır.
• Bir boyutta şekilde verildiği gibi
bir eğridir.
• Formülü ise
• Burada σ, standart sapma, μ ise
mean değeridir.
41
Temel İstatistik Kavramları
Gauss Dağılımı
• Gauss dağılımı, Merkezi Limit Teoreminden dolayı
bir çok problemde karşımıza çıkar.
• Bu teorem, bir çok rasgele küçük değerin Gauss
dağılımına sahip olacağını söyler. Yüksek boyutta şu
şekilde hesaplanır.
• Burada 𝛴, kovaryans matrisi, 𝛴 −1 kovaryans
matrisin tersi, 𝛴 ise bu matrisin determinantıdır.
42
Temel İstatistik Kavramları
Gauss Dağılımı
• Şekilde iki boyutta üç farklı durum görülmekte.
• Birincisi, kovaryans matrisin birim matrisi olduğu
durumda. Küresel kovaryans matrisi olarak bilinir.
• İkinci durum, sadece kovaryans matrisin
diagonalinde sayıların olduğu durum
• Üçüncüsü ise genel durum.
43
Bias-Varyans Çekişmesi
• Makine öğrenmesinde karmaşık modeller
öğrenmede daha fazla veriye ihtiyaç duyarlar
ve overfitting riski yüksektir.
• Overfitting engellemek için validation setler
kullanılır.
• Daha karmaşık bir modelin her zaman daha iyi
sonuçlar vermeyeceğini göstermek için basit
bir fikir ortaya atılmıştır. Bias-varyans
çekişmesi.
44
Bias-Varyans Çekişmesi
• Makine öğrenmesi gerçekleştiren bir model iki
sebeple kötü olabilir.
• Veriye uyum sağlayamamıştır (bias)
• Hassas değildir. Sonuçlarda çok fazla varyasyon
vardır (varyans)
• Model karmaşıklaştıkça bias artar, varyans düşer.
Modeli spesifik hale getireyim deseniz ve varyansı
artırsanız bu sefer de bias düşer.
• Bir modelde hatayı hesaplamanın en genel yöntemi
hedef ve gerçek çıkış arasındaki farkları karelerini
toplamaktır.
45
Bias-Varyans Çekişmesi
• Bu hata formülüne baktığımızda bu formülü
parçalamak suretiyle buradan varyans ve bias
büyüklüklerini elde edebiliriz.
• Diyelim ki yaklaşmaya çalıştığımız fonksiyon 𝑦 =
𝑓 𝑥 + 𝜀 olsun. Burada 𝜀 gürültüdür ve 0 varyans ve
mean değerine sahip olduğu varsayılır.
• Biz makine öğrenmesi algoritmasını ℎ 𝑥 = 𝑤 𝑇 𝑥 + 𝑏
2
hipotezini hata kareleri toplamını 𝑦𝑖 − ℎ 𝑥𝑖
𝑖
minimize etmek için veriye uydurmaya çalışırız.
46
Bias-Varyans Çekişmesi
• Modelimizin başarılı olup olmadığını görmek için
bağımsız bir veri olarak x* girişi kullanılır ve rasgele
bir değer olduğunu varsaydımız hata kareleri
toplamının beklenen değeri hesaplanır.
• Hatırlayacağımız gibi 𝐸 𝑥 = 𝑥ҧ mean değeridir.
• Eğer Z rasgele bir değer ise bu durumda şu eşitlik
yazılabilir.
𝐸 = (𝑍 − 𝑍)ҧ 2 = 𝐸 𝑍 2 − 2𝑍 𝑍ҧ + 𝑍ҧ 2
ഥ + 𝑍ҧ 2
= 𝐸[𝑍 2 ] − 2𝐸[𝑍]𝑍
= 𝐸[𝑍 2 ] − 2𝑍ҧ 𝑍ҧ + 𝑍ҧ 2
= 𝐸[𝑍 2 ] − 𝑍ҧ 2
47
Bias-Varyans Çekişmesi
• Bu eşitlikten hareketle yeni bir giriş için hata
kareleri toplamının beklenen değerini
hesaplayabiliriz.
48
Bias-Varyans Çekişmesi
• Eşitliğin sağ tarafındaki 3 büyüklükten en soldaki test
verisinin varyansıdır ve indirgenemez hatadır ve bizim
kontrolümüzün dışındadır.
• İkinci terim varyans ve üçüncüsü ise bias karesidir.
• Burada bias büyüklüğü yaklaşma hatasıdır… Bias terimi
bize neyi veriyor? Gerçek fonksiyon ile ortalama
gerçeklenen fonksiyon arasındaki farktır.
• Varyans büyüklüğü ise tahmin hatasıdır… Yani öğrenen
model tarafından eğitim seti için gerçeklenen
fonksiyonun ortalamasından bir örneğin gerçeklemesi
çıkartılıyor ve karesi alınıyor.
49
Bias-Varyans Çekişmesi
50
Bias-Varyans Çekişmesi
51